 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured light with a million light planes per second
Nov 27, 2024



We introduce a structured light system that captures full-frame depth at rates of a thousand frames per second, four times faster than the previous state of the art. Our key innovation to this end is the design of an acousto-optic light scanning device that can scan light planes at rates up to two million planes per second. We combine this device with an event camera for structured light, using the sparse events triggered on the camera as we sweep a light plane on the scene for depth triangulation. In contrast to prior work, where light scanning is the bottleneck towards faster structured light operation, our light scanning device is three orders of magnitude faster than the event camera's full-frame bandwidth, thus allowing us to take full advantage of the event camera's fast operation. To surpass this bandwidth, we additionally demonstrate adaptive scanning of only regions of interest, at speeds an order of magnitude faster than the theoretical full-frame limit for event cameras.
Dress-Me-Up: A Dataset & Method for Self-Supervised 3D Garment Retargeting
Jan 06, 2024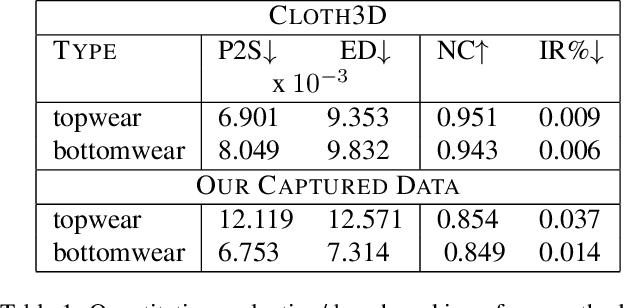
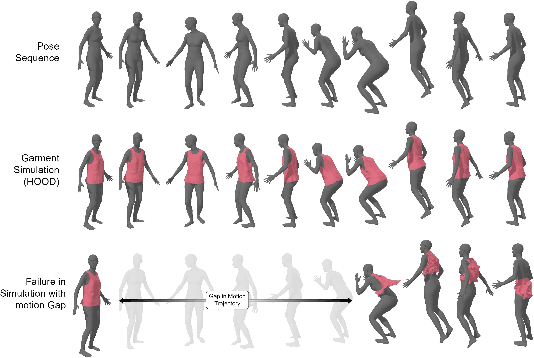
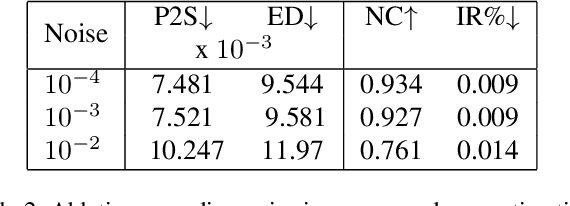
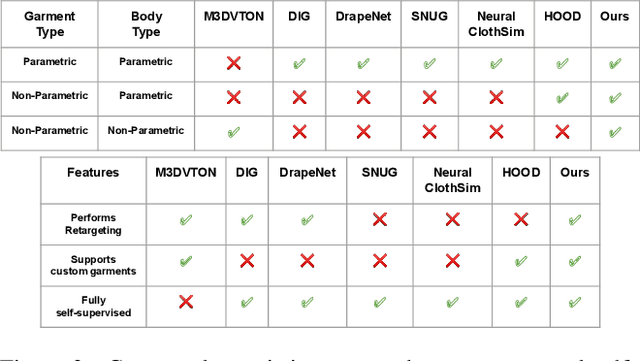
We propose a novel self-supervised framework for retargeting non-parameterized 3D garments onto 3D human avatars of arbitrary shapes and poses, enabling 3D virtual try-on (VTON). Existing self-supervised 3D retargeting methods only support parametric and canonical garments, which can only be draped over parametric body, e.g. SMPL. To facilitate the non-parametric garments and body, we propose a novel method that introduces Isomap Embedding based correspondences matching between the garment and the human body to get a coarse alignment between the two meshes. We perform neural refinement of the coarse alignment in a self-supervised setting. Further, we leverage a Laplacian detail integration method for preserving the inherent details of the input garment. For evaluating our 3D non-parametric garment retargeting framework, we propose a dataset of 255 real-world garments with realistic noise and topological deformations. The dataset contains $44$ unique garments worn by 15 different subjects in 5 distinctive poses, captured using a multi-view RGBD capture setup. We show superior retargeting quality on non-parametric garments and human avatars over existing state-of-the-art methods, acting as the first-ever baseline on the proposed dataset for non-parametric 3D garment retargeting.
FusedRF: Fusing Multiple Radiance Fields
Jun 07, 2023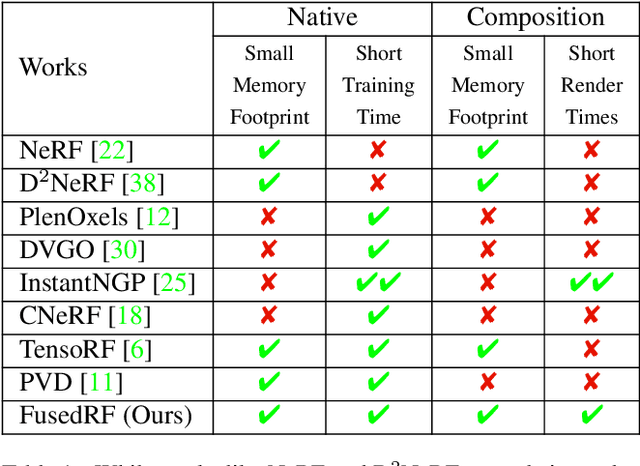
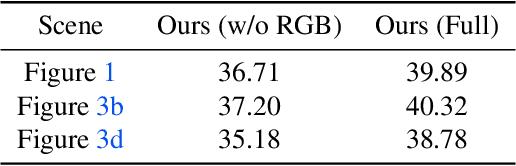
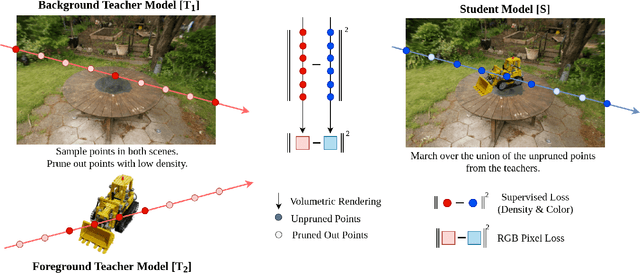

Radiance Fields (RFs) have shown great potential to represent scenes from casually captured discrete views. Compositing parts or whole of multiple captured scenes could greatly interest several XR applications. Prior works can generate new views of such scenes by tracing each scene in parallel. This increases the render times and memory requirements with the number of components. In this work, we provide a method to create a single, compact, fused RF representation for a scene composited using multiple RFs. The fused RF has the same render times and memory utilizations as a single RF. Our method distills information from multiple teacher RFs into a single student RF while also facilitating further manipulations like addition and deletion into the fused representation.
Interactive Segmentation of Radiance Fields
Dec 27, 2022
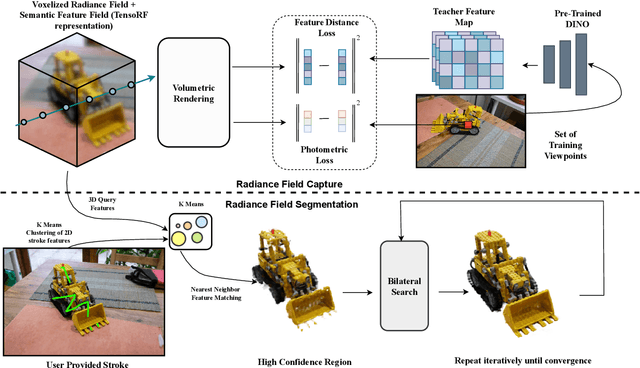
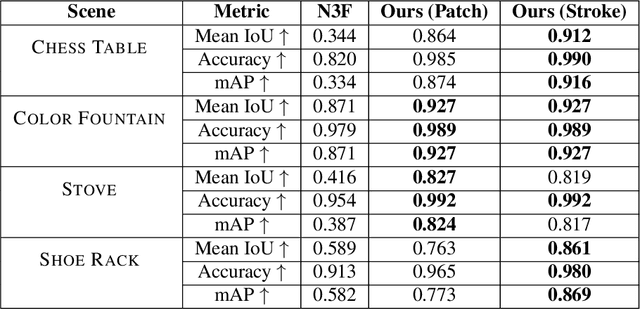

Radiance Fields (RF) are popular to represent casually-captured scenes for new view generation and have been used for applications beyond it. Understanding and manipulating scenes represented as RFs have to naturally follow to facilitate mixed reality on personal spaces. Semantic segmentation of objects in the 3D scene is an important step for that. Prior segmentation efforts using feature distillation show promise but don't scale to complex objects with diverse appearance. We present a framework to interactively segment objects with fine structure. Nearest neighbor feature matching identifies high-confidence regions of the objects using distilled features. Bilateral filtering in a joint spatio-semantic space grows the region to recover accurate segmentation. We show state-of-the-art results of segmenting objects from RFs and compositing them to another scene, changing appearance, etc., moving closer to rich scene manipulation and understanding. Project Page: https://rahul-goel.github.io/isrf/
Appearance Editing with Free-viewpoint Neural Rendering
Oct 14, 2021



We present a neural rendering framework for simultaneous view synthesis and appearance editing of a scene from multi-view images captured under known environment illumination. Existing approaches either achieve view synthesis alone or view synthesis along with relighting, without direct control over the scene's appearance. Our approach explicitly disentangles the appearance and learns a lighting representation that is independent of it. Specifically, we independently estimate the BRDF and use it to learn a lighting-only representation of the scene. Such disentanglement allows our approach to generalize to arbitrary changes in appearance while performing view synthesis. We show results of editing the appearance of a real scene, demonstrating that our approach produces plausible appearance editing. The performance of our view synthesis approach is demonstrated to be at par with state-of-the-art approaches on both real and synthetic data.