 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusedRF: Fusing Multiple Radiance Fields
Jun 07, 2023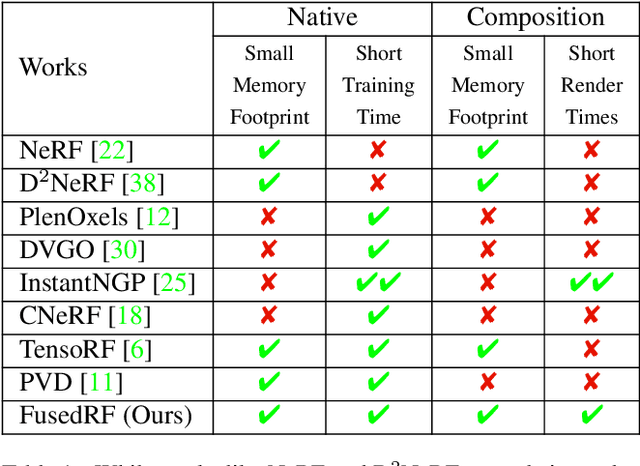
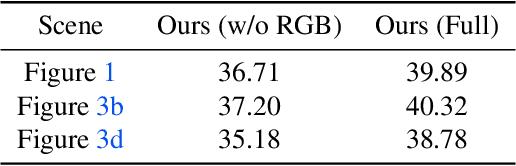
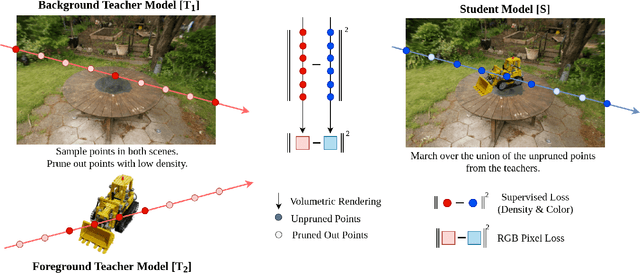

Radiance Fields (RFs) have shown great potential to represent scenes from casually captured discrete views. Compositing parts or whole of multiple captured scenes could greatly interest several XR applications. Prior works can generate new views of such scenes by tracing each scene in parallel. This increases the render times and memory requirements with the number of components. In this work, we provide a method to create a single, compact, fused RF representation for a scene composited using multiple RFs. The fused RF has the same render times and memory utilizations as a single RF. Our method distills information from multiple teacher RFs into a single student RF while also facilitating further manipulations like addition and deletion into the fused representation.
Interactive Segmentation of Radiance Fields
Dec 27, 2022
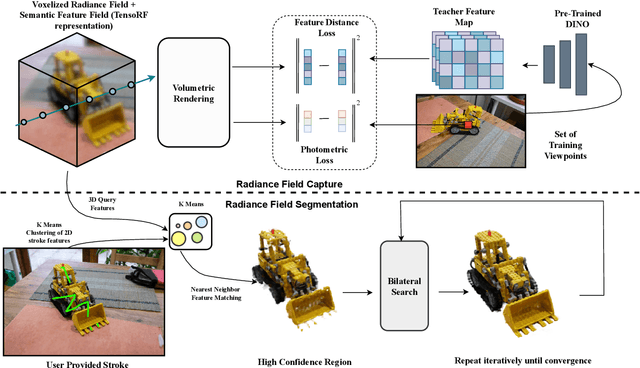
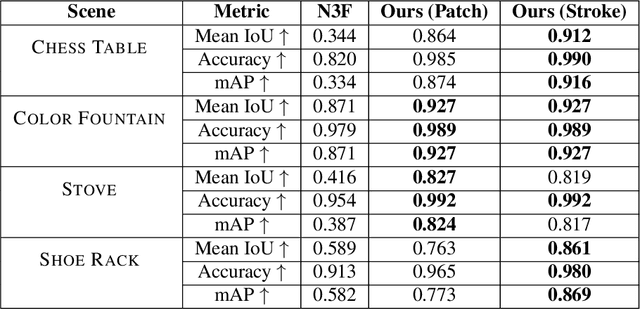

Radiance Fields (RF) are popular to represent casually-captured scenes for new view generation and have been used for applications beyond it. Understanding and manipulating scenes represented as RFs have to naturally follow to facilitate mixed reality on personal spaces. Semantic segmentation of objects in the 3D scene is an important step for that. Prior segmentation efforts using feature distillation show promise but don't scale to complex objects with diverse appearance. We present a framework to interactively segment objects with fine structure. Nearest neighbor feature matching identifies high-confidence regions of the objects using distilled features. Bilateral filtering in a joint spatio-semantic space grows the region to recover accurate segmentation. We show state-of-the-art results of segmenting objects from RFs and compositing them to another scene, changing appearance, etc., moving closer to rich scene manipulation and understanding. Project Page: https://rahul-goel.github.io/isrf/
Learning to Hash-tag Videos with Tag2Vec
Dec 13, 2016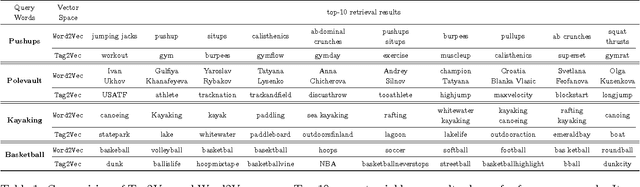
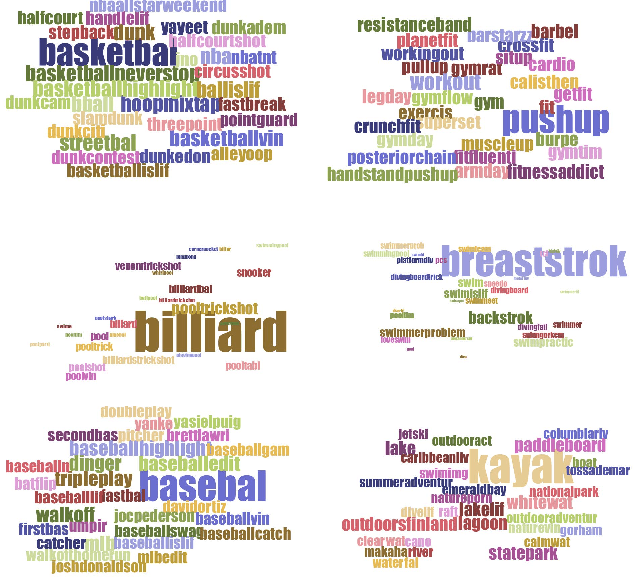

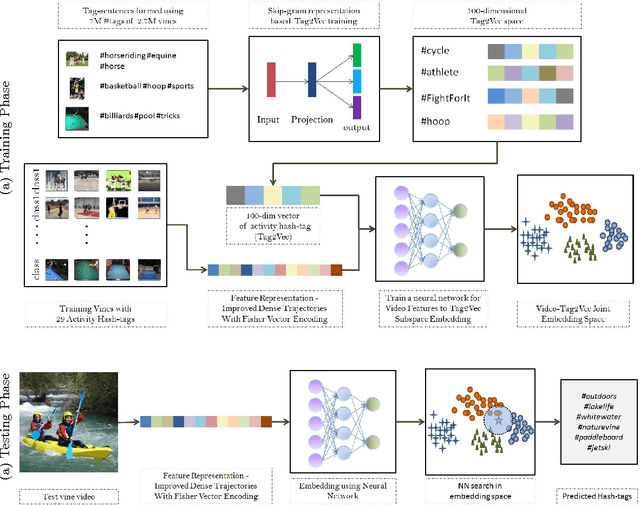
User-given tags or labels are valuable resources for semantic understanding of visual media such as images and videos. Recently, a new type of labeling mechanism known as hash-tags have become increasingly popular on social media sites. In this paper, we study the problem of generating relevant and useful hash-tags for short video clips. Traditional data-driven approaches for tag enrichment and recommendation use direct visual similarity for label transfer and propagation. We attempt to learn a direct low-cost mapping from video to hash-tags using a two step training process. We first employ a natural language processing (NLP) technique, skip-gram models with neural network training to learn a low-dimensional vector representation of hash-tags (Tag2Vec) using a corpus of 10 million hash-tags. We then train an embedding function to map video features to the low-dimensional Tag2vec space. We learn this embedding for 29 categories of short video clips with hash-tags. A query video without any tag-information can then be directly mapped to the vector space of tags using the learned embedding and relevant tags can be found by performing a simple nearest-neighbor retrieval in the Tag2Vec space. We validate the relevance of the tags suggested by our system qualitatively and quantitatively with a user study.