 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Are in Control of Your State: Why Human Outcomes Are Controllable Through Causal State Intervention
May 28, 2026A central puzzle for the behavioural sciences and for human-facing artificial intelligence is the persistence of within-person variability. The same individual, presented with the same observable input, produces different outcomes on different occasions, and different individuals produce divergent outcomes that no observable covariate fully predicts. We argue that this variability belongs in the dynamic latent state of the person, and that human outcomes are controllable in a precise and operational sense through interventions that target the state and its weighting at the moment a decision is being formed. We define a state as the time-indexed weighting vector over the dimensions that govern how an individual's biology, physiology, and neuropsychology process the next event into a decision and an outcome. The relationship between state, decision, and outcome is causal rather than correlational. The weighting vector is dynamic at sub-daily timescales. The conscious channel through which outcomes are reportable is a narrow attentional bottleneck whose contents are themselves state-dependent. Taken together, these claims imply that the outcome of a given event is controllable, conditionally, on the state-trajectory at the time of intervention. We motivate the framework with six strands of established evidence (causal inference, predictive processing, allostasis, attentional bottleneck, chronobiology, computational psychiatry) and a 24-month observational base from a deployed behavioural platform spanning more than 200,000 consented users across four occupational personas (research period 2023 to 2026). We derive seven testable predictions, list six operational requirements for state-aware systems, and discuss implications for digital health, education, AI personalisation, and personal agency.
Thread Detection and Response Generation using Transformers with Prompt Optimisation
Mar 09, 2024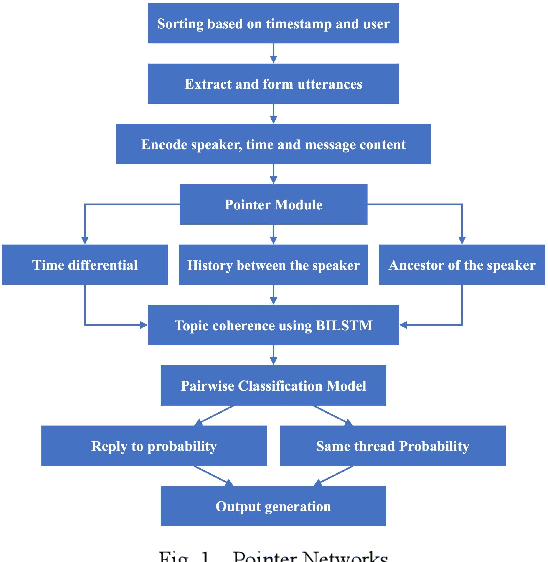
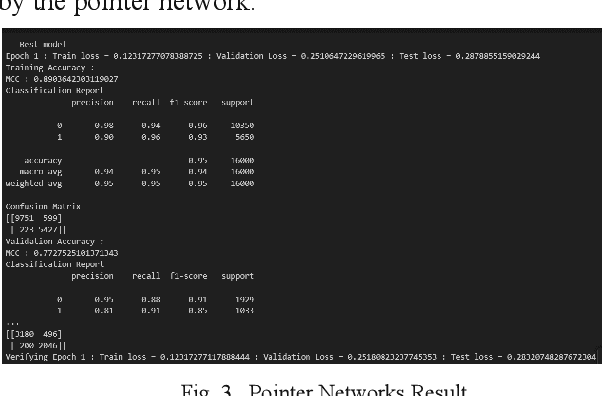

Conversational systems are crucial for human-computer interaction, managing complex dialogues by identifying threads and prioritising responses. This is especially vital in multi-party conversations, where precise identification of threads and strategic response prioritisation ensure efficient dialogue management. To address these challenges an end-to-end model that identifies threads and prioritises their response generation based on the importance was developed, involving a systematic decomposition of the problem into discrete components - thread detection, prioritisation, and performance optimisation which was meticulously analysed and optimised. These refined components seamlessly integrate into a unified framework, in conversational systems. Llama2 7b is used due to its high level of generalisation but the system can be updated with any open source Large Language Model(LLM). The computational capabilities of the Llama2 model was augmented by using fine tuning methods and strategic prompting techniques to optimise the model's performance, reducing computational time and increasing the accuracy of the model. The model achieves up to 10x speed improvement, while generating more coherent results compared to existing models.
Semi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection
Sep 05, 2022One of the primary challenges in Semi-supervised Domain Adaptation (SSDA) is the skewed ratio between the number of labeled source and target samples, causing the model to be biased towards the source domain. Recent works in SSDA show that aligning only the labeled target samples with the source samples potentially leads to incomplete domain alignment of the target domain to the source domain. In our approach, to align the two domains, we leverage contrastive losses to learn a semantically meaningful and a domain agnostic feature space using the supervised samples from both domains. To mitigate challenges caused by the skewed label ratio, we pseudo-label the unlabeled target samples by comparing their feature representation to those of the labeled samples from both the source and target domains. Furthermore, to increase the support of the target domain, these potentially noisy pseudo-labels are gradually injected into the labeled target dataset over the course of training. Specifically, we use a temperature scaled cosine similarity measure to assign a soft pseudo-label to the unlabeled target samples. Additionally, we compute an exponential moving average of the soft pseudo-labels for each unlabeled sample. These pseudo-labels are progressively injected or removed) into the (from) the labeled target dataset based on a confidence threshold to supplement the alignment of the source and target distributions. Finally, we use a supervised contrastive loss on the labeled and pseudo-labeled datasets to align the source and target distributions. Using our proposed approach, we showcase state-of-the-art performance on SSDA benchmarks - Office-Home, DomainNet and Office-31.
ViTOL: Vision Transformer for Weakly Supervised Object Localization
Apr 14, 2022
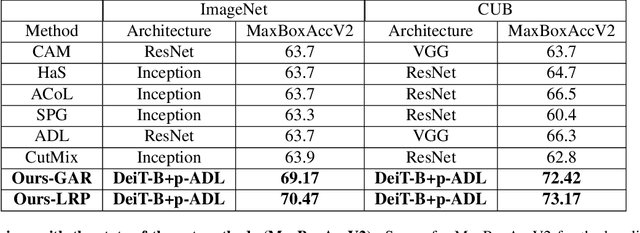
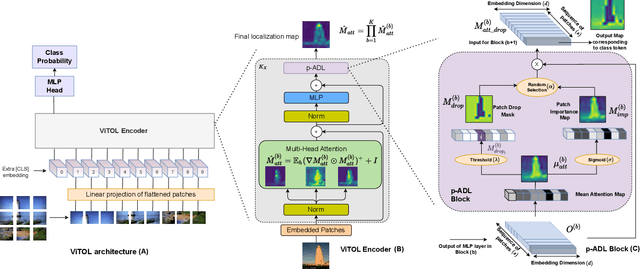
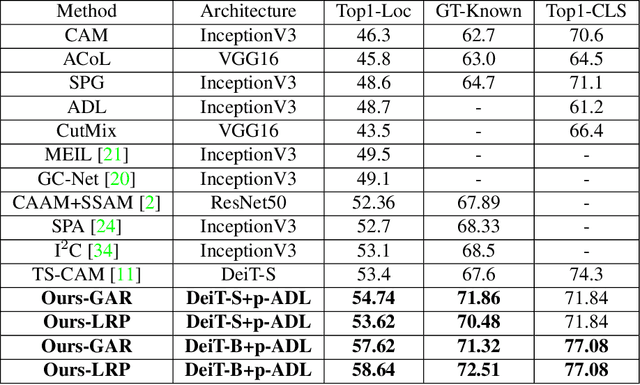
Weakly supervised object localization (WSOL) aims at predicting object locations in an image using only image-level category labels. Common challenges that image classification models encounter when localizing objects are, (a) they tend to look at the most discriminative features in an image that confines the localization map to a very small region, (b) the localization maps are class agnostic, and the models highlight objects of multiple classes in the same image and, (c) the localization performance is affected by background noise. To alleviate the above challenges we introduce the following simple changes through our proposed method ViTOL. We leverage the vision-based transformer for self-attention and introduce a patch-based attention dropout layer (p-ADL) to increase the coverage of the localization map and a gradient attention rollout mechanism to generate class-dependent attention maps. We conduct extensive quantitative, qualitative and ablation experiments on the ImageNet-1K and CUB datasets. We achieve state-of-the-art MaxBoxAcc-V2 localization scores of 70.47% and 73.17% on the two datasets respectively. Code is available on https://github.com/Saurav-31/ViTOL
Wind ramp event prediction with parallelized Gradient Boosted Regression Trees
Oct 17, 2016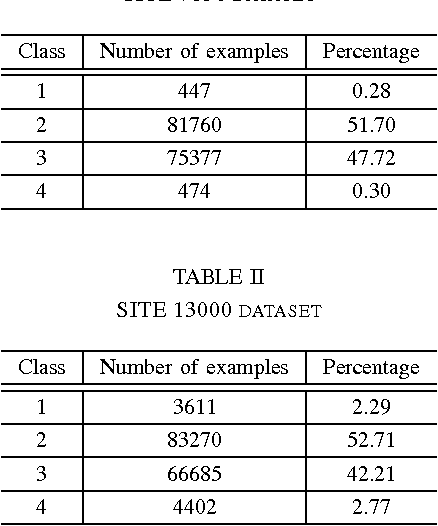
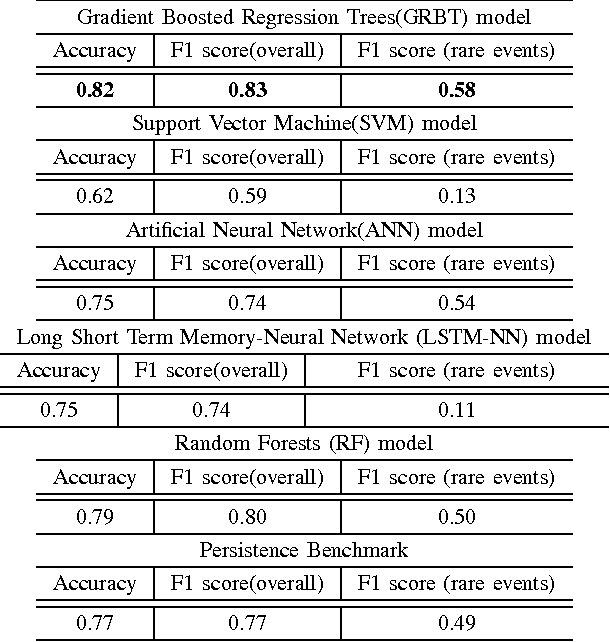

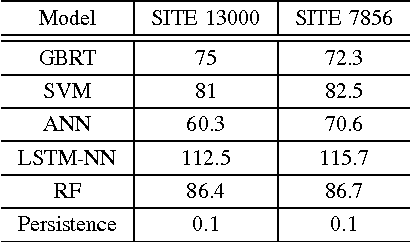
Accurate prediction of wind ramp events is critical for ensuring the reliability and stability of the power systems with high penetration of wind energy. This paper proposes a classification based approach for estimating the future class of wind ramp event based on certain thresholds. A parallelized gradient boosted regression tree based technique has been proposed to accurately classify the normal as well as rare extreme wind power ramp events. The model has been validated using wind power data obtained from the National Renewable Energy Laboratory database. Performance comparison with several benchmark techniques indicates the superiority of the proposed technique in terms of superior classification accuracy.