 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection
Sep 05, 2022One of the primary challenges in Semi-supervised Domain Adaptation (SSDA) is the skewed ratio between the number of labeled source and target samples, causing the model to be biased towards the source domain. Recent works in SSDA show that aligning only the labeled target samples with the source samples potentially leads to incomplete domain alignment of the target domain to the source domain. In our approach, to align the two domains, we leverage contrastive losses to learn a semantically meaningful and a domain agnostic feature space using the supervised samples from both domains. To mitigate challenges caused by the skewed label ratio, we pseudo-label the unlabeled target samples by comparing their feature representation to those of the labeled samples from both the source and target domains. Furthermore, to increase the support of the target domain, these potentially noisy pseudo-labels are gradually injected into the labeled target dataset over the course of training. Specifically, we use a temperature scaled cosine similarity measure to assign a soft pseudo-label to the unlabeled target samples. Additionally, we compute an exponential moving average of the soft pseudo-labels for each unlabeled sample. These pseudo-labels are progressively injected or removed) into the (from) the labeled target dataset based on a confidence threshold to supplement the alignment of the source and target distributions. Finally, we use a supervised contrastive loss on the labeled and pseudo-labeled datasets to align the source and target distributions. Using our proposed approach, we showcase state-of-the-art performance on SSDA benchmarks - Office-Home, DomainNet and Office-31.
Low-Cost Transfer Learning of Face Tasks
Jan 09, 2019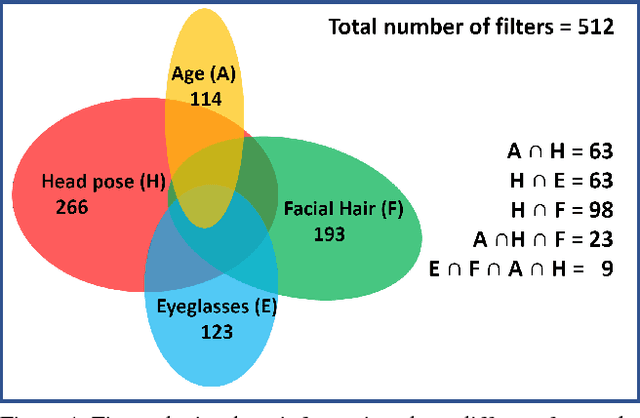
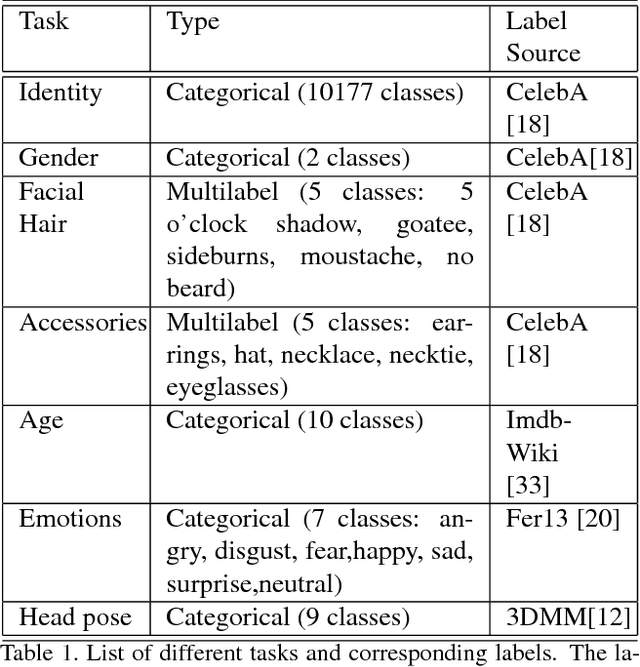
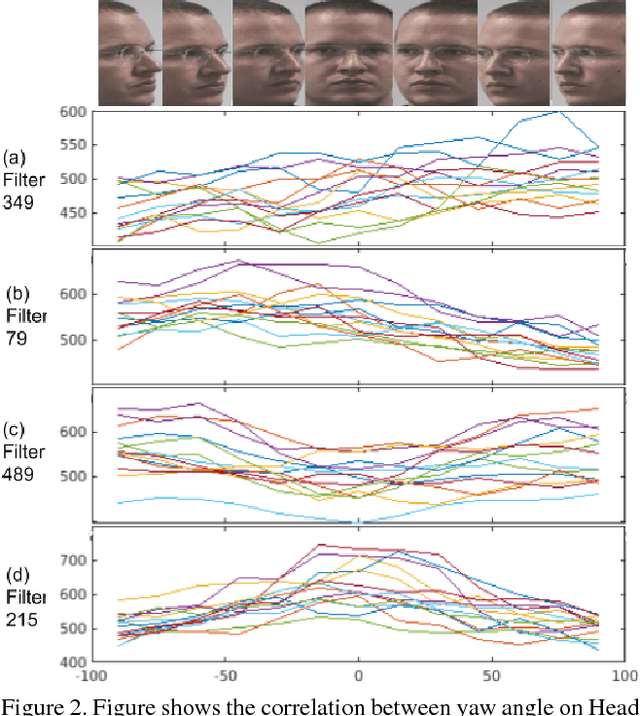

Do we know what the different filters of a face network represent? Can we use this filter information to train other tasks without transfer learning? For instance, can age, head pose, emotion and other face related tasks be learned from face recognition network without transfer learning? Understanding the role of these filters allows us to transfer knowledge across tasks and take advantage of large data sets in related tasks. Given a pretrained network, we can infer which tasks the network generalizes for and the best way to transfer the information to a new task.