 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Deep Face Algorithms through Visualization: A Survey
Sep 26, 2023



Although current deep models for face tasks surpass human performance on some benchmarks, we do not understand how they work. Thus, we cannot predict how it will react to novel inputs, resulting in catastrophic failures and unwanted biases in the algorithms. Explainable AI helps bridge the gap, but currently, there are very few visualization algorithms designed for faces. This work undertakes a first-of-its-kind meta-analysis of explainability algorithms in the face domain. We explore the nuances and caveats of adapting general-purpose visualization algorithms to the face domain, illustrated by computing visualizations on popular face models. We review existing face explainability works and reveal valuable insights into the structure and hierarchy of face networks. We also determine the design considerations for practical face visualizations accessible to AI practitioners by conducting a user study on the utility of various explainability algorithms.
Canonical Saliency Maps: Decoding Deep Face Models
May 04, 2021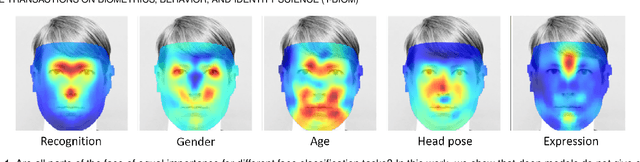

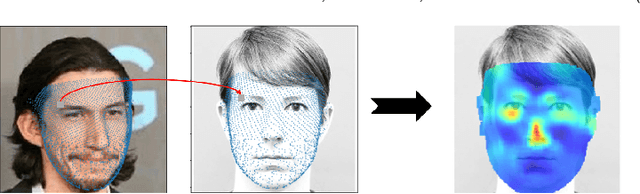

As Deep Neural Network models for face processing tasks approach human-like performance, their deployment in critical applications such as law enforcement and access control has seen an upswing, where any failure may have far-reaching consequences. We need methods to build trust in deployed systems by making their working as transparent as possible. Existing visualization algorithms are designed for object recognition and do not give insightful results when applied to the face domain. In this work, we present 'Canonical Saliency Maps', a new method that highlights relevant facial areas by projecting saliency maps onto a canonical face model. We present two kinds of Canonical Saliency Maps: image-level maps and model-level maps. Image-level maps highlight facial features responsible for the decision made by a deep face model on a given image, thus helping to understand how a DNN made a prediction on the image. Model-level maps provide an understanding of what the entire DNN model focuses on in each task and thus can be used to detect biases in the model. Our qualitative and quantitative results show the usefulness of the proposed canonical saliency maps, which can be used on any deep face model regardless of the architecture.
Low-Cost Transfer Learning of Face Tasks
Jan 09, 2019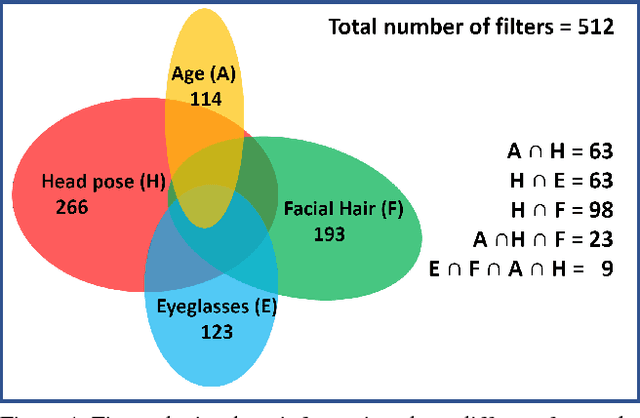
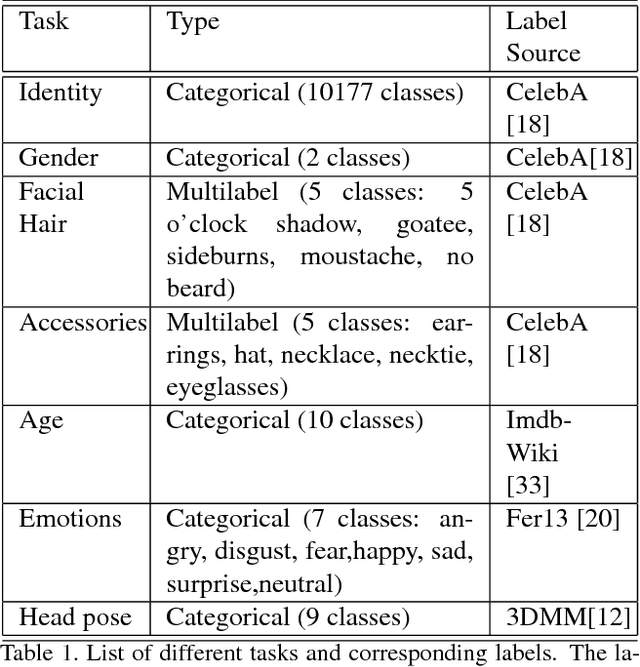
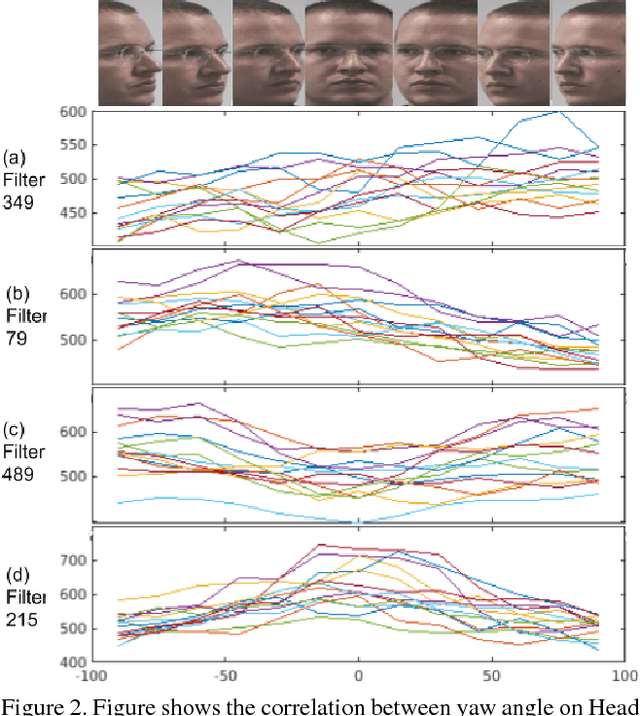

Do we know what the different filters of a face network represent? Can we use this filter information to train other tasks without transfer learning? For instance, can age, head pose, emotion and other face related tasks be learned from face recognition network without transfer learning? Understanding the role of these filters allows us to transfer knowledge across tasks and take advantage of large data sets in related tasks. Given a pretrained network, we can infer which tasks the network generalizes for and the best way to transfer the information to a new task.