 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUDA : Contrastive Learning in Unsupervised Domain Adaptation for Semantic Segmentation
Paper and Code
Aug 27, 2022
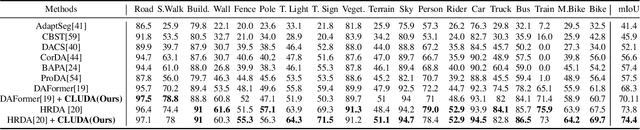
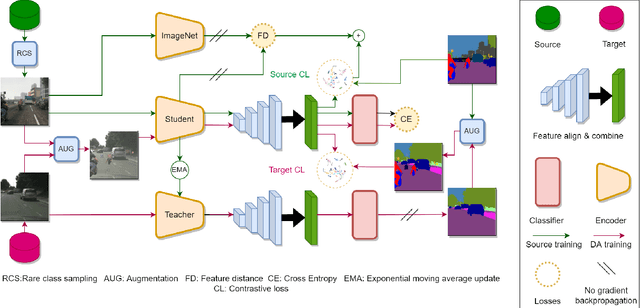
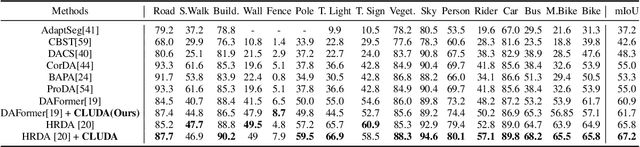
In this work, we propose CLUDA, a simple, yet novel method for performing unsupervised domain adaptation (UDA) for semantic segmentation by incorporating contrastive losses into a student-teacher learning paradigm, that makes use of pseudo-labels generated from the target domain by the teacher network. More specifically, we extract a multi-level fused-feature map from the encoder, and apply contrastive loss across different classes and different domains, via source-target mixing of images. We consistently improve performance on various feature encoder architectures and for different domain adaptation datasets in semantic segmentation. Furthermore, we introduce a learned-weighted contrastive loss to improve upon on a state-of-the-art multi-resolution training approach in UDA. We produce state-of-the-art results on GTA $\rightarrow$ Cityscapes (74.4 mIOU, +0.6) and Synthia $\rightarrow$ Cityscapes (67.2 mIOU, +1.4) datasets. CLUDA effectively demonstrates contrastive learning in UDA as a generic method, which can be easily integrated into any existing UDA for semantic segmentation tasks. Please refer to the supplementary material for the details on implementation.