 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Incremental Cross-Modal Hashing Approach
Feb 03, 2020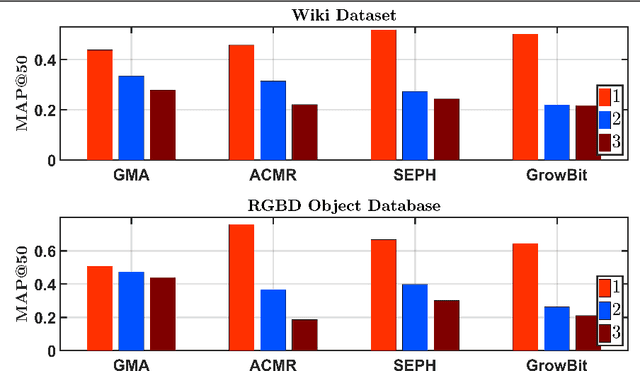
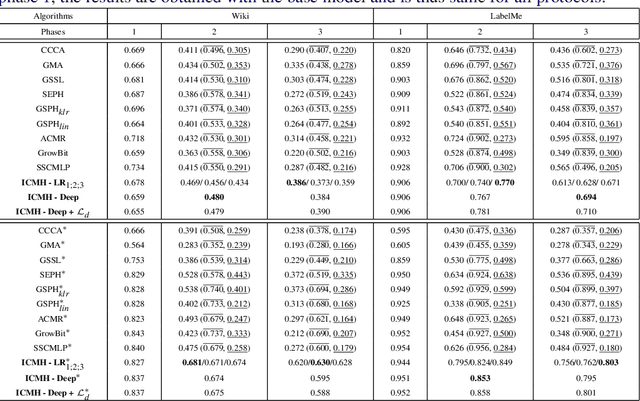
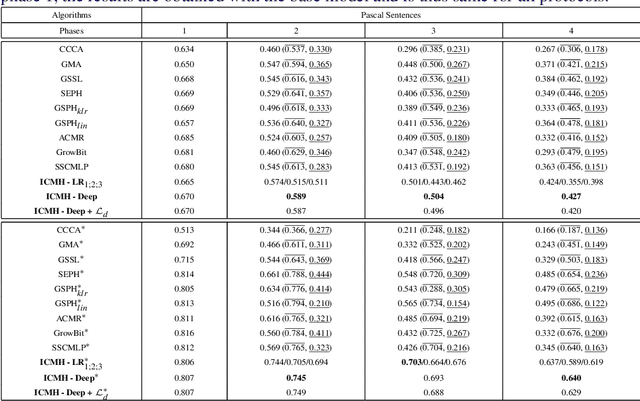
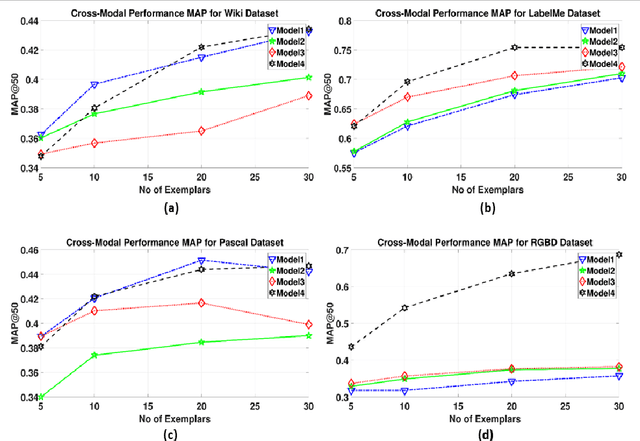
Cross-modal retrieval deals with retrieving relevant items from one modality, when provided with a search query from another modality. Hashing techniques, where the data is represented as binary bits have specifically gained importance due to the ease of storage, fast computations and high accuracy. In real world, the number of data categories is continuously increasing, which requires algorithms capable of handling this dynamic scenario. In this work, we propose a novel incremental cross-modal hashing algorithm termed "iCMH", which can adapt itself to handle incoming data of new categories. The proposed approach consists of two sequential stages, namely, learning the hash codes and training the hash functions. At every stage, a small amount of old category data termed "exemplars" is is used so as not to forget the old data while trying to learn for the new incoming data, i.e. to avoid catastrophic forgetting. In the first stage, the hash codes for the exemplars is used, and simultaneously, hash codes for the new data is computed such that it maintains the semantic relations with the existing data. For the second stage, we propose both a non-deep and deep architectures to learn the hash functions effectively. Extensive experiments across a variety of cross-modal datasets and comparisons with state-of-the-art cross-modal algorithms shows the usefulness of our approach.
What happens when self-supervision meets Noisy Labels?
Oct 26, 2019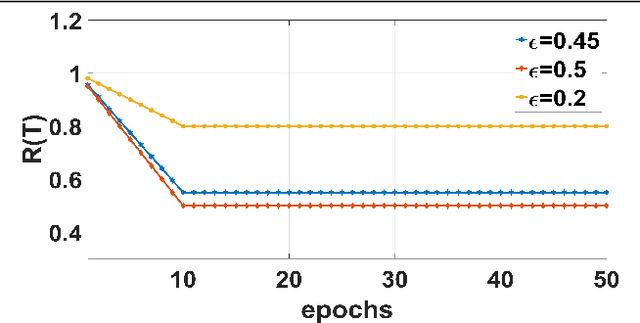
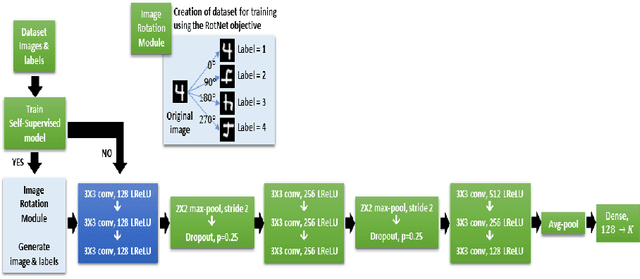
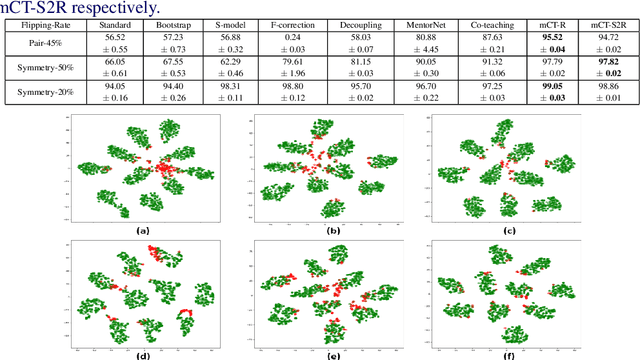

The major driving force behind the immense success of deep learning models is the availability of large datasets along with their clean labels. Unfortunately, this is very difficult to obtain, which has motivated research on the training of deep models in the presence of label noise and ways to avoid over-fitting on the noisy labels. In this work, we build upon the seminal work in this area, Co-teaching and propose a simple, yet efficient approach termed mCT-S2R (modified co-teaching with self-supervision and re-labeling) for this task. First, to deal with significant amount of noise in the labels, we propose to use self-supervision to generate robust features without using any labels. Next, using a parallel network architecture, an estimate of the clean labeled portion of the data is obtained. Finally, using this data, a portion of the estimated noisy labeled portion is re-labeled, before resuming the network training with the augmented data. Extensive experiments on three standard datasets show the effectiveness of the proposed framework.
Label Prediction Framework for Semi-Supervised Cross-Modal Retrieval
May 27, 2019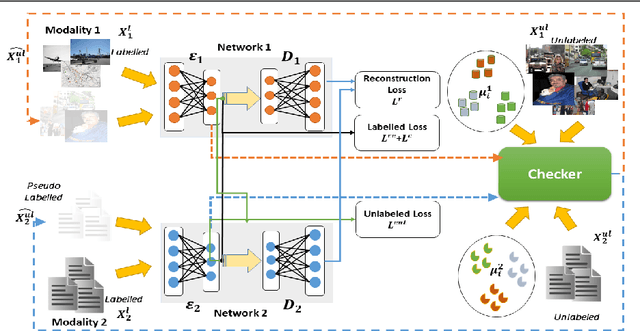
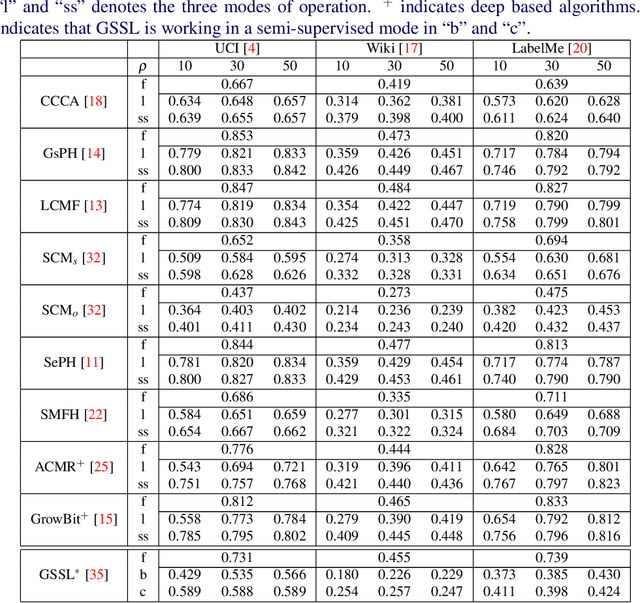
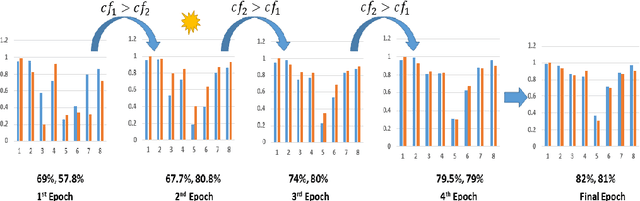
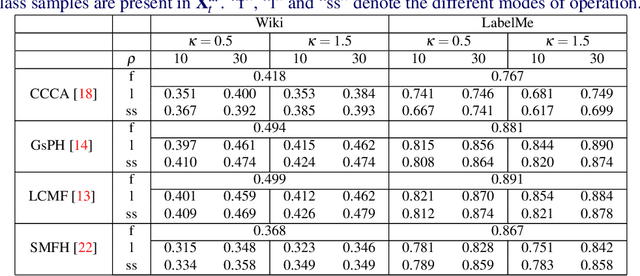
Cross-modal data matching refers to retrieval of data from one modality, when given a query from another modality. In general, supervised algorithms achieve better retrieval performance compared to their unsupervised counterpart, as they can learn better representative features by leveraging the available label information. However, this comes at the cost of requiring huge amount of labeled examples, which may not always be available. In this work, we propose a novel framework in a semi-supervised setting, which can predict the labels of the unlabeled data using complementary information from different modalities. The proposed framework can be used as an add-on with any baseline crossmodal algorithm to give significant performance improvement, even in case of limited labeled data. Finally, we analyze the challenging scenario where the unlabeled examples can even come from classes not in the training data and evaluate the performance of our algorithm under such setting. Extensive evaluation using several baseline algorithms across three different datasets shows the effectiveness of our label prediction framework.
Segregation Network for Multi-Class Novelty Detection
May 11, 2019
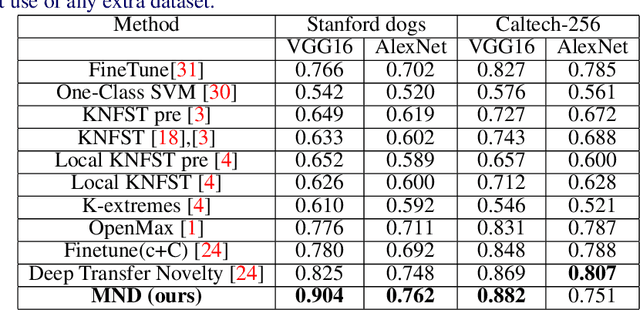
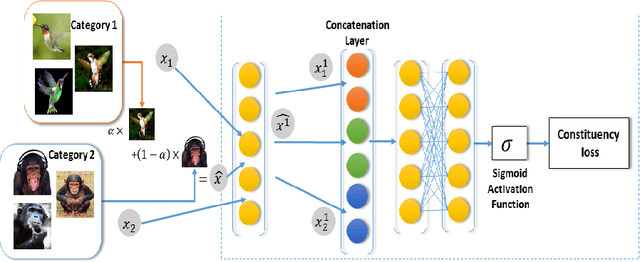
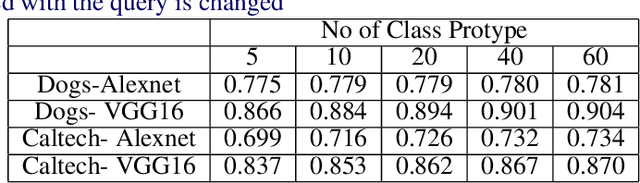
The problem of multiple class novelty detection is gaining increasing importance due to the large availability of multimedia data and the increasing requirement of the classification models to work in an open set scenario. To this end, novelty detection tries to answer this important question: given a test example should we even try to classify it? In this work, we design a novel deep learning framework, termed Segregation Network, which is trained using the mixup technique. We construct interpolated points using convex combinations of pairs of training data and use our novel loss function for prediction of its constituent classes. During testing, for each input query, mixed samples with the known class prototypes are generated and passed through the proposed network. The output of the network reveals the constituent classes which can be used to determine whether the incoming data is from the known class set or not. Our algorithm is trained using just the data from the known classes and does not require any auxiliary dataset or attributes. Extensive evaluation on two benchmark datasets namely Caltech-256 and Stanford Dogs and comparison with the state-of-the-art justifies the effectiveness of the proposed framework.
Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition
May 06, 2019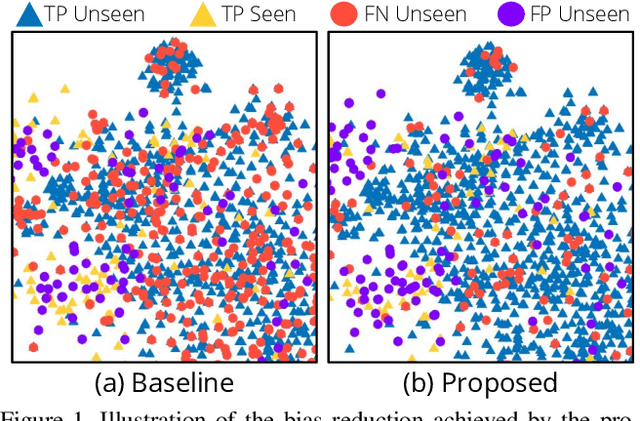
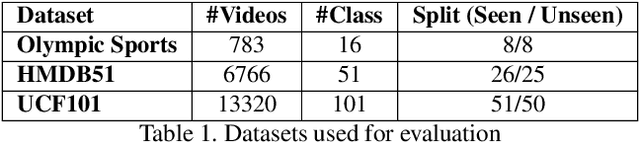
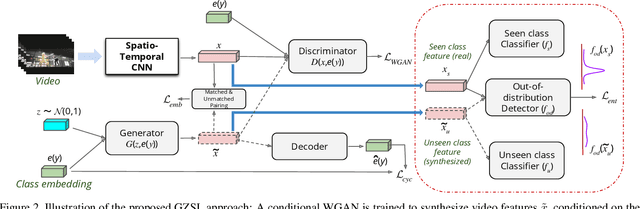
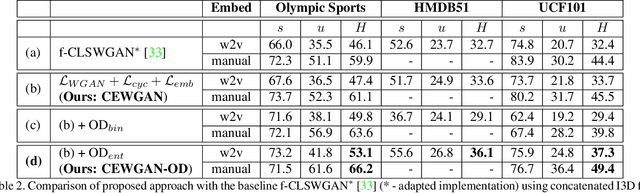
Generalized zero-shot action recognition is a challenging problem, where the task is to recognize new action categories that are unavailable during the training stage, in addition to the seen action categories. Existing approaches suffer from the inherent bias of the learned classifier towards the seen action categories. As a consequence, unseen category samples are incorrectly classified as belonging to one of the seen action categories. In this paper, we set out to tackle this issue by arguing for a separate treatment of seen and unseen action categories in generalized zero-shot action recognition. We introduce an out-of-distribution detector that determines whether the video features belong to a seen or unseen action category. To train our out-of-distribution detector, video features for unseen action categories are synthesized using generative adversarial networks trained on seen action category features. To the best of our knowledge, we are the first to propose an out-of-distribution detector based GZSL framework for action recognition in videos. Experiments are performed on three action recognition datasets: Olympic Sports, HMDB51 and UCF101. For generalized zero-shot action recognition, our proposed approach outperforms the baseline (f-CLSWGAN) with absolute gains (in classification accuracy) of 7.0%, 3.4%, and 4.9%, respectively, on these datasets.
A Deep Learning Framework for Semi-Supervised Cross-Modal Retrieval with Label Prediction
Dec 04, 2018
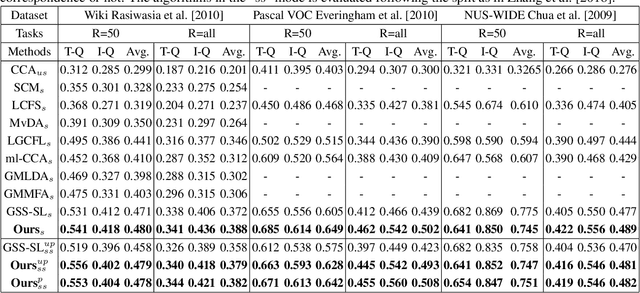
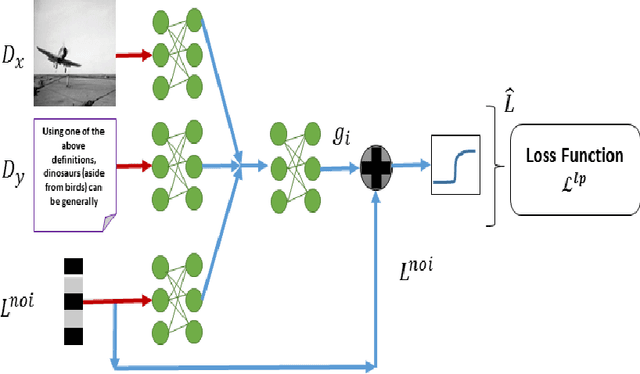
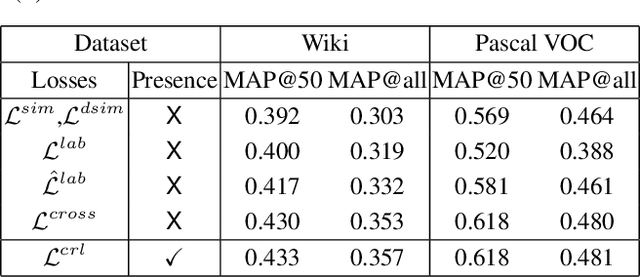
Due to abundance of data from multiple modalities, cross-modal retrieval tasks with image-text, audio-image, etc. are gaining increasing importance. Of the different approaches proposed, supervised methods usually give significant improvement over their unsupervised counterparts at the additional cost of labeling or annotation of the training data. Semi-supervised methods are recently becoming popular as they provide an elegant framework to balance the conflicting requirement of labeling cost and accuracy. In this work, we propose a novel deep semi-supervised framework which can seamlessly handle both labeled as well as unlabeled data. The network has two important components: (a) the label prediction component predicts the labels for the unlabeled portion of the data and then (b) a common modality-invariant representation is learned for cross-modal retrieval. The two parts of the network are trained sequentially one after the other. Extensive experiments on three standard benchmark datasets, Wiki, Pascal VOC and NUS-WIDE demonstrate that the proposed framework outperforms the state-of-the-art for both supervised and semi-supervised settings.