 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightAnyone: A Generalized Relightable 3D Gaussian Head Model
Jan 06, 20263D Gaussian Splatting (3DGS) has become a standard approach to reconstruct and render photorealistic 3D head avatars. A major challenge is to relight the avatars to match any scene illumination. For high quality relighting, existing methods require subjects to be captured under complex time-multiplexed illumination, such as one-light-at-a-time (OLAT). We propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. Our core idea is to learn a mapping from flat-lit 3DGS avatars to corresponding relightable Gaussian parameters for that avatar. Our model consists of two stages: a first stage that models flat-lit 3DGS avatars without OLAT lighting, and a second stage that learns the mapping to physically-based reflectance parameters for high-quality relighting. This two-stage design allows us to train the first stage across diverse existing multi-view datasets without OLAT lighting ensuring cross-subject generalization, where we learn a dataset-specific lighting code for self-supervised lighting alignment. Subsequently, the second stage can be trained on a significantly smaller dataset of subjects captured under OLAT illumination. Together, this allows our method to generalize well and relight any subject from the first stage as if we had captured them under OLAT lighting. Furthermore, we can fit our model to unseen subjects from as little as a single image, allowing several applications in novel view synthesis and relighting for digital avatars.
HumanOLAT: A Large-Scale Dataset for Full-Body Human Relighting and Novel-View Synthesis
Aug 12, 2025Simultaneous relighting and novel-view rendering of digital human representations is an important yet challenging task with numerous applications. Progress in this area has been significantly limited due to the lack of publicly available, high-quality datasets, especially for full-body human captures. To address this critical gap, we introduce the HumanOLAT dataset, the first publicly accessible large-scale dataset of multi-view One-Light-at-a-Time (OLAT) captures of full-body humans. The dataset includes HDR RGB frames under various illuminations, such as white light, environment maps, color gradients and fine-grained OLAT illuminations. Our evaluations of state-of-the-art relighting and novel-view synthesis methods underscore both the dataset's value and the significant challenges still present in modeling complex human-centric appearance and lighting interactions. We believe HumanOLAT will significantly facilitate future research, enabling rigorous benchmarking and advancements in both general and human-specific relighting and rendering techniques.
DiffAge3D: Diffusion-based 3D-aware Face Aging
Aug 28, 2024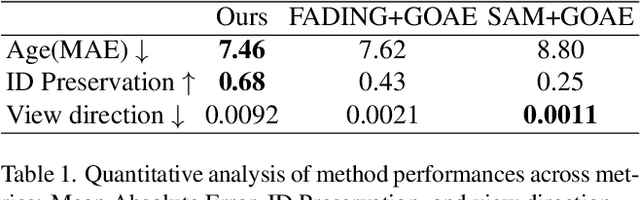
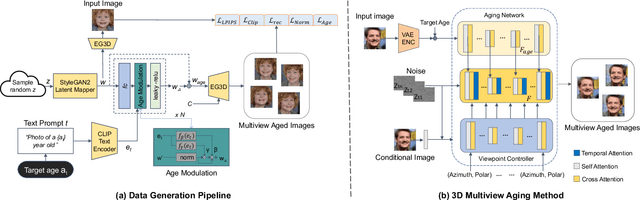
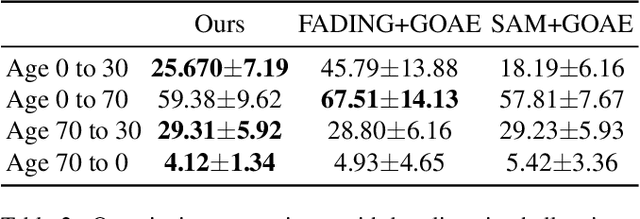

Face aging is the process of converting an individual's appearance to a younger or older version of themselves. Existing face aging techniques have been limited to 2D settings, which often weaken their applications as there is a growing demand for 3D face modeling. Moreover, existing aging methods struggle to perform faithful aging, maintain identity, and retain the fine details of the input images. Given these limitations and the need for a 3D-aware aging method, we propose DiffAge3D, the first 3D-aware aging framework that not only performs faithful aging and identity preservation but also operates in a 3D setting. Our aging framework allows to model the aging and camera pose separately by only taking a single image with a target age. Our framework includes a robust 3D-aware aging dataset generation pipeline by utilizing a pre-trained 3D GAN and the rich text embedding capabilities within CLIP model. Notably, we do not employ any inversion bottleneck in dataset generation. Instead, we randomly generate training samples from the latent space of 3D GAN, allowing us to manipulate the rich latent space of GAN to generate ages even with large gaps. With the generated dataset, we train a viewpoint-aware diffusion-based aging model to control the camera pose and facial age. Through quantitative and qualitative evaluations, we demonstrate that DiffAge3D outperforms existing methods, particularly in multiview-consistent aging and fine details preservation.
Lite2Relight: 3D-aware Single Image Portrait Relighting
Jul 15, 2024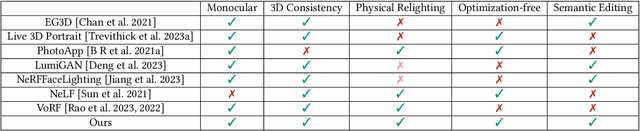
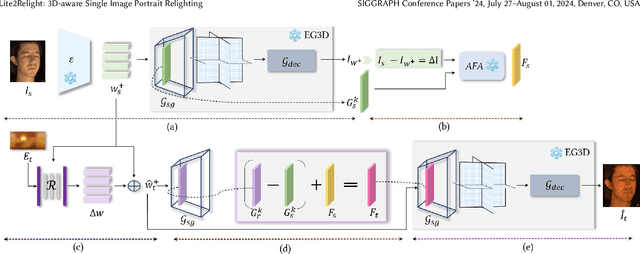
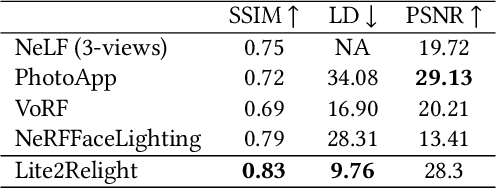

Achieving photorealistic 3D view synthesis and relighting of human portraits is pivotal for advancing AR/VR applications. Existing methodologies in portrait relighting demonstrate substantial limitations in terms of generalization and 3D consistency, coupled with inaccuracies in physically realistic lighting and identity preservation. Furthermore, personalization from a single view is difficult to achieve and often requires multiview images during the testing phase or involves slow optimization processes. This paper introduces Lite2Relight, a novel technique that can predict 3D consistent head poses of portraits while performing physically plausible light editing at interactive speed. Our method uniquely extends the generative capabilities and efficient volumetric representation of EG3D, leveraging a lightstage dataset to implicitly disentangle face reflectance and perform relighting under target HDRI environment maps. By utilizing a pre-trained geometry-aware encoder and a feature alignment module, we map input images into a relightable 3D space, enhancing them with a strong face geometry and reflectance prior. Through extensive quantitative and qualitative evaluations, we show that our method outperforms the state-of-the-art methods in terms of efficacy, photorealism, and practical application. This includes producing 3D-consistent results of the full head, including hair, eyes, and expressions. Lite2Relight paves the way for large-scale adoption of photorealistic portrait editing in various domains, offering a robust, interactive solution to a previously constrained problem. Project page: https://vcai.mpi-inf.mpg.de/projects/Lite2Relight/
Adaptive Name Entity Recognition under Highly Unbalanced Data
Mar 10, 2020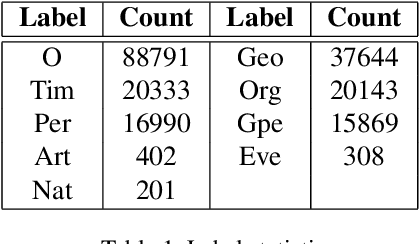
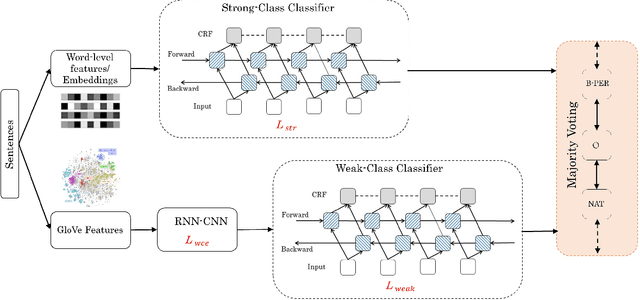
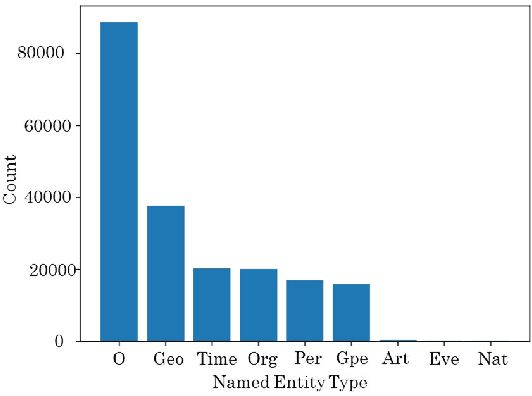
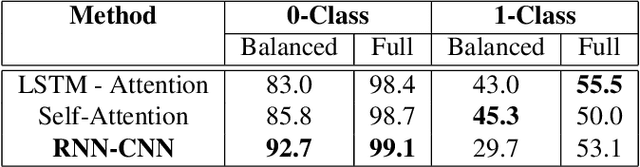
For several purposes in Natural Language Processing (NLP), such as Information Extraction, Sentiment Analysis or Chatbot, Named Entity Recognition (NER) holds an important role as it helps to determine and categorize entities in text into predefined groups such as the names of persons, locations, quantities, organizations or percentages, etc. In this report, we present our experiments on a neural architecture composed of a Conditional Random Field (CRF) layer stacked on top of a Bi-directional LSTM (BI-LSTM) layer for solving NER tasks. Besides, we also employ a fusion input of embedding vectors (Glove, BERT), which are pre-trained on the huge corpus to boost the generalization capacity of the model. Unfortunately, due to the heavy unbalanced distribution cross-training data, both approaches just attained a bad performance on less training samples classes. To overcome this challenge, we introduce an add-on classification model to split sentences into two different sets: Weak and Strong classes and then designing a couple of Bi-LSTM-CRF models properly to optimize performance on each set. We evaluated our models on the test set and discovered that our method can improve performance for Weak classes significantly by using a very small data set (approximately 0.45\%) compared to the rest classes.
Label Prediction Framework for Semi-Supervised Cross-Modal Retrieval
May 27, 2019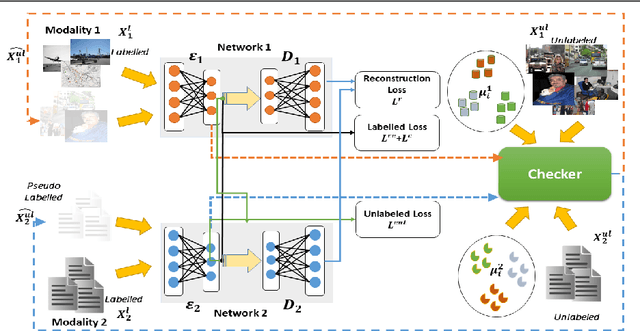
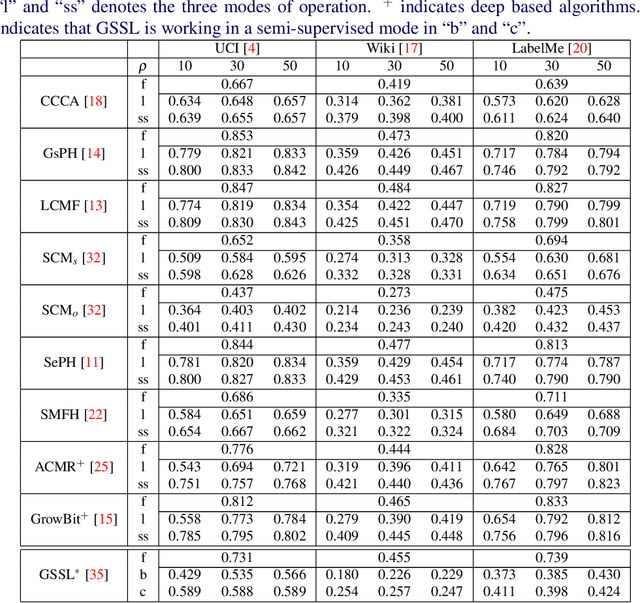
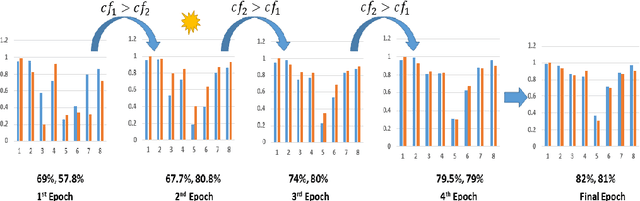
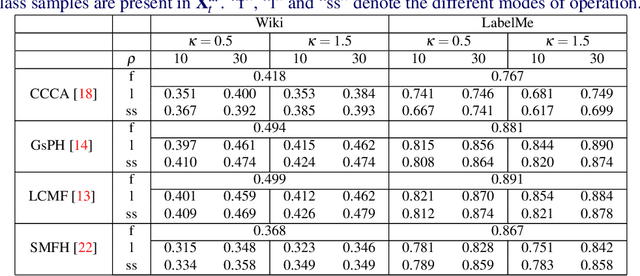
Cross-modal data matching refers to retrieval of data from one modality, when given a query from another modality. In general, supervised algorithms achieve better retrieval performance compared to their unsupervised counterpart, as they can learn better representative features by leveraging the available label information. However, this comes at the cost of requiring huge amount of labeled examples, which may not always be available. In this work, we propose a novel framework in a semi-supervised setting, which can predict the labels of the unlabeled data using complementary information from different modalities. The proposed framework can be used as an add-on with any baseline crossmodal algorithm to give significant performance improvement, even in case of limited labeled data. Finally, we analyze the challenging scenario where the unlabeled examples can even come from classes not in the training data and evaluate the performance of our algorithm under such setting. Extensive evaluation using several baseline algorithms across three different datasets shows the effectiveness of our label prediction framework.
A Deep Learning Framework for Semi-Supervised Cross-Modal Retrieval with Label Prediction
Dec 04, 2018
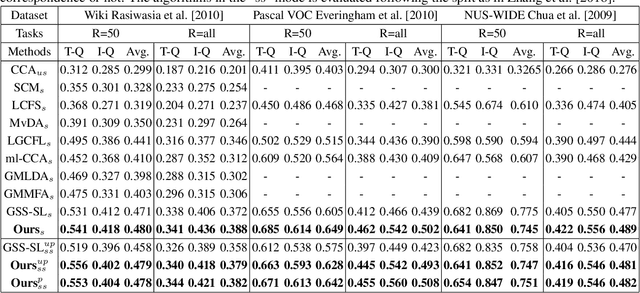
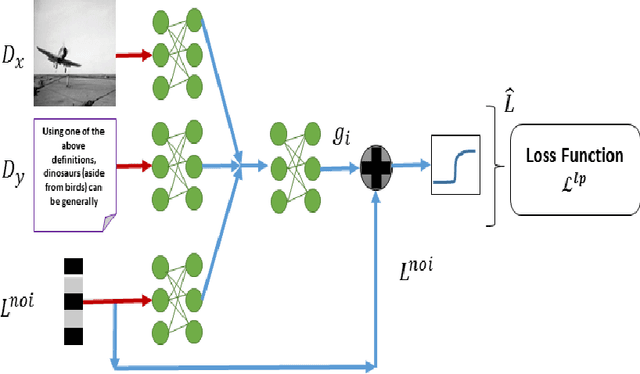
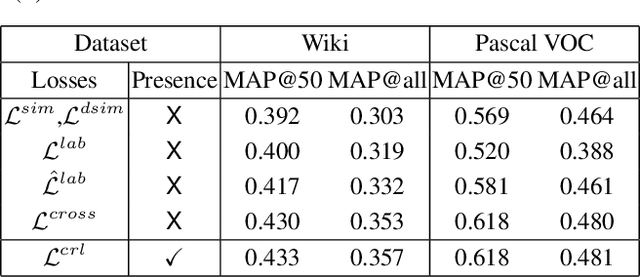
Due to abundance of data from multiple modalities, cross-modal retrieval tasks with image-text, audio-image, etc. are gaining increasing importance. Of the different approaches proposed, supervised methods usually give significant improvement over their unsupervised counterparts at the additional cost of labeling or annotation of the training data. Semi-supervised methods are recently becoming popular as they provide an elegant framework to balance the conflicting requirement of labeling cost and accuracy. In this work, we propose a novel deep semi-supervised framework which can seamlessly handle both labeled as well as unlabeled data. The network has two important components: (a) the label prediction component predicts the labels for the unlabeled portion of the data and then (b) a common modality-invariant representation is learned for cross-modal retrieval. The two parts of the network are trained sequentially one after the other. Extensive experiments on three standard benchmark datasets, Wiki, Pascal VOC and NUS-WIDE demonstrate that the proposed framework outperforms the state-of-the-art for both supervised and semi-supervised settings.