 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Prediction Framework for Semi-Supervised Cross-Modal Retrieval
Paper and Code
May 27, 2019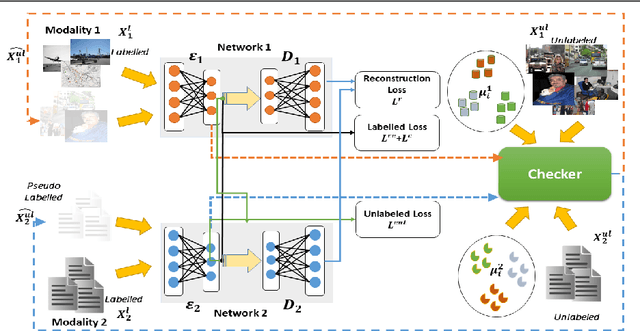
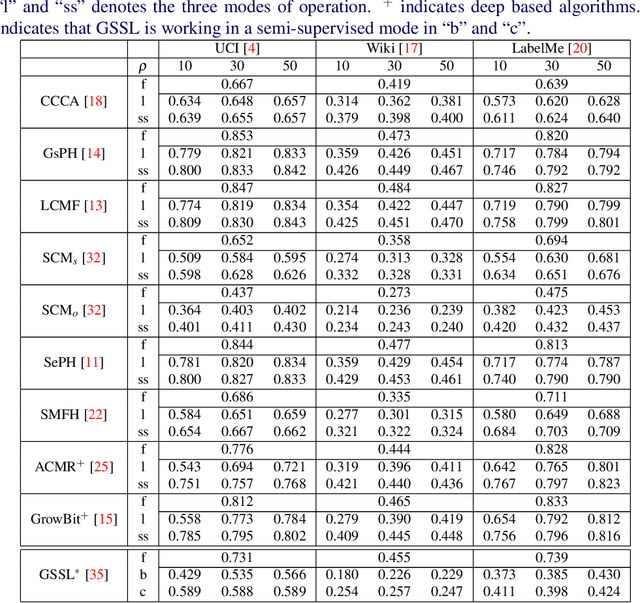
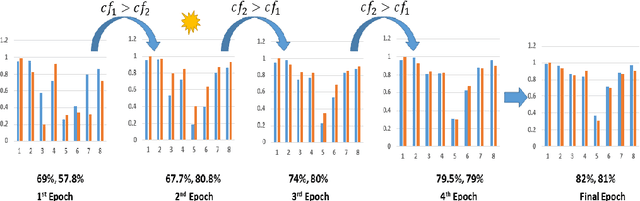
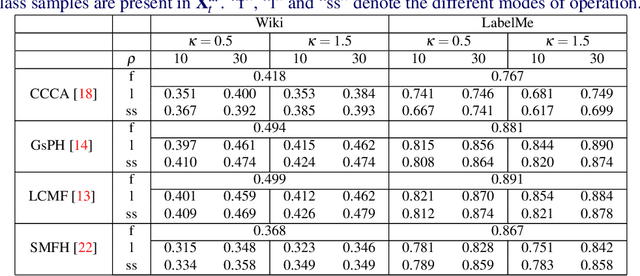
Cross-modal data matching refers to retrieval of data from one modality, when given a query from another modality. In general, supervised algorithms achieve better retrieval performance compared to their unsupervised counterpart, as they can learn better representative features by leveraging the available label information. However, this comes at the cost of requiring huge amount of labeled examples, which may not always be available. In this work, we propose a novel framework in a semi-supervised setting, which can predict the labels of the unlabeled data using complementary information from different modalities. The proposed framework can be used as an add-on with any baseline crossmodal algorithm to give significant performance improvement, even in case of limited labeled data. Finally, we analyze the challenging scenario where the unlabeled examples can even come from classes not in the training data and evaluate the performance of our algorithm under such setting. Extensive evaluation using several baseline algorithms across three different datasets shows the effectiveness of our label prediction framework.