 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Framework for Semi-Supervised Cross-Modal Retrieval with Label Prediction
Paper and Code
Dec 04, 2018
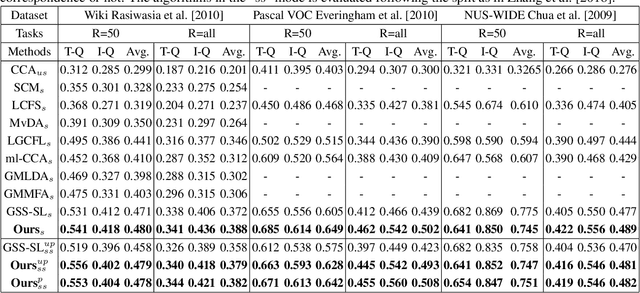
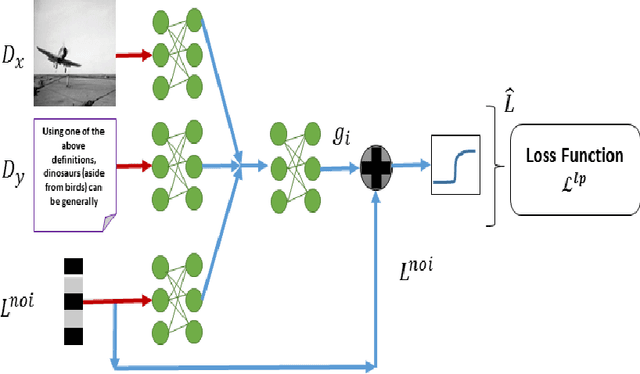
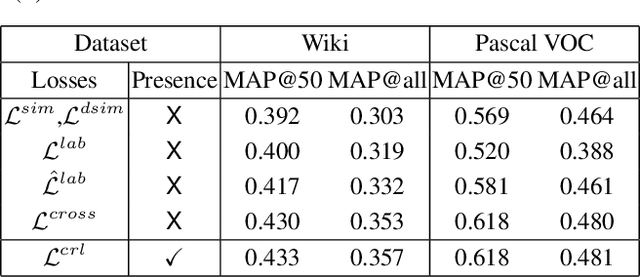
Due to abundance of data from multiple modalities, cross-modal retrieval tasks with image-text, audio-image, etc. are gaining increasing importance. Of the different approaches proposed, supervised methods usually give significant improvement over their unsupervised counterparts at the additional cost of labeling or annotation of the training data. Semi-supervised methods are recently becoming popular as they provide an elegant framework to balance the conflicting requirement of labeling cost and accuracy. In this work, we propose a novel deep semi-supervised framework which can seamlessly handle both labeled as well as unlabeled data. The network has two important components: (a) the label prediction component predicts the labels for the unlabeled portion of the data and then (b) a common modality-invariant representation is learned for cross-modal retrieval. The two parts of the network are trained sequentially one after the other. Extensive experiments on three standard benchmark datasets, Wiki, Pascal VOC and NUS-WIDE demonstrate that the proposed framework outperforms the state-of-the-art for both supervised and semi-supervised settings.