 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Incremental Cross-Modal Hashing Approach
Paper and Code
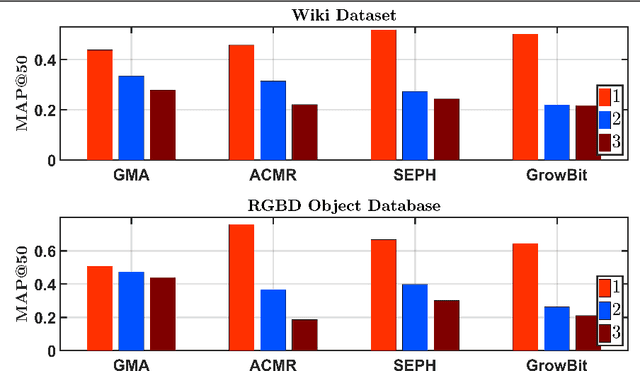
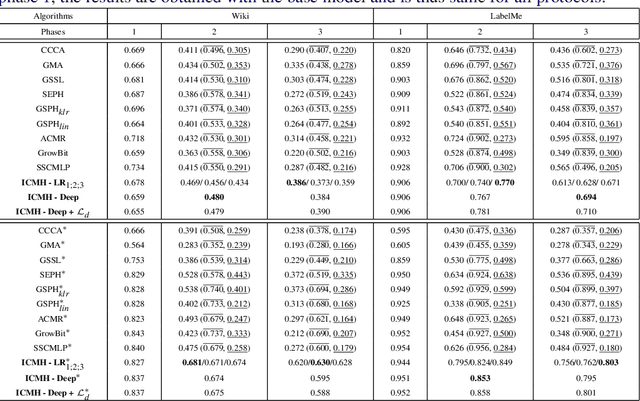
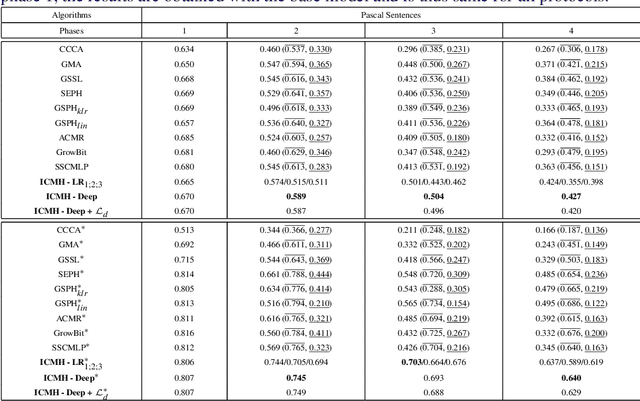
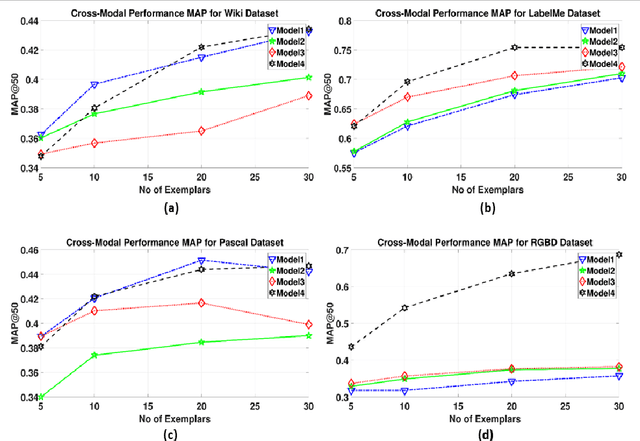
Cross-modal retrieval deals with retrieving relevant items from one modality, when provided with a search query from another modality. Hashing techniques, where the data is represented as binary bits have specifically gained importance due to the ease of storage, fast computations and high accuracy. In real world, the number of data categories is continuously increasing, which requires algorithms capable of handling this dynamic scenario. In this work, we propose a novel incremental cross-modal hashing algorithm termed "iCMH", which can adapt itself to handle incoming data of new categories. The proposed approach consists of two sequential stages, namely, learning the hash codes and training the hash functions. At every stage, a small amount of old category data termed "exemplars" is is used so as not to forget the old data while trying to learn for the new incoming data, i.e. to avoid catastrophic forgetting. In the first stage, the hash codes for the exemplars is used, and simultaneously, hash codes for the new data is computed such that it maintains the semantic relations with the existing data. For the second stage, we propose both a non-deep and deep architectures to learn the hash functions effectively. Extensive experiments across a variety of cross-modal datasets and comparisons with state-of-the-art cross-modal algorithms shows the usefulness of our approach.