 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat happens when self-supervision meets Noisy Labels?
Paper and Code
Oct 26, 2019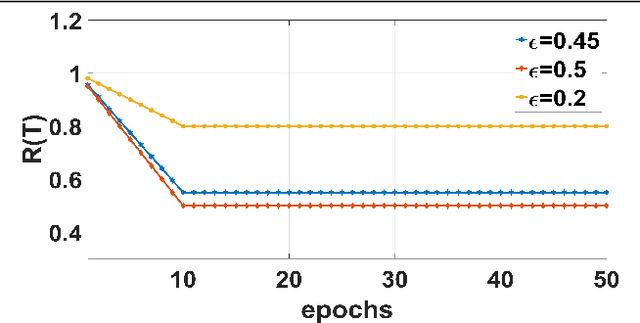
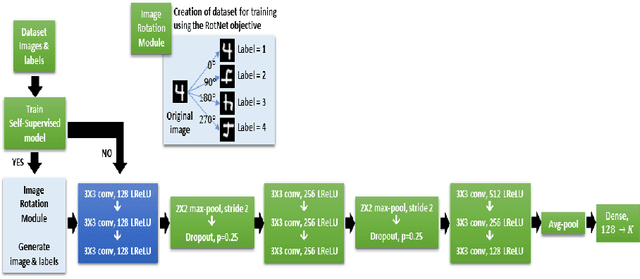
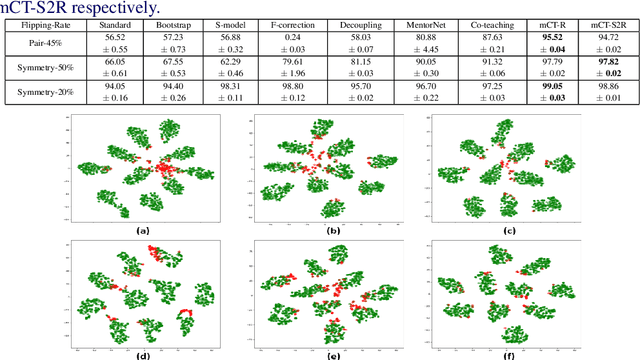

The major driving force behind the immense success of deep learning models is the availability of large datasets along with their clean labels. Unfortunately, this is very difficult to obtain, which has motivated research on the training of deep models in the presence of label noise and ways to avoid over-fitting on the noisy labels. In this work, we build upon the seminal work in this area, Co-teaching and propose a simple, yet efficient approach termed mCT-S2R (modified co-teaching with self-supervision and re-labeling) for this task. First, to deal with significant amount of noise in the labels, we propose to use self-supervision to generate robust features without using any labels. Next, using a parallel network architecture, an estimate of the clean labeled portion of the data is obtained. Finally, using this data, a portion of the estimated noisy labeled portion is re-labeled, before resuming the network training with the augmented data. Extensive experiments on three standard datasets show the effectiveness of the proposed framework.