 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose Estimation under limited supervision using Metric Learning
Aug 14, 2019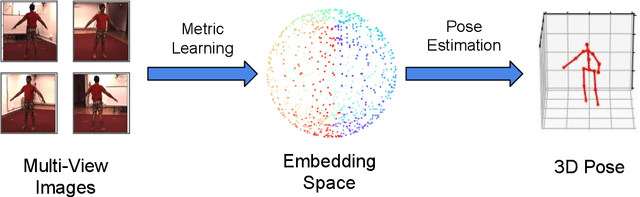
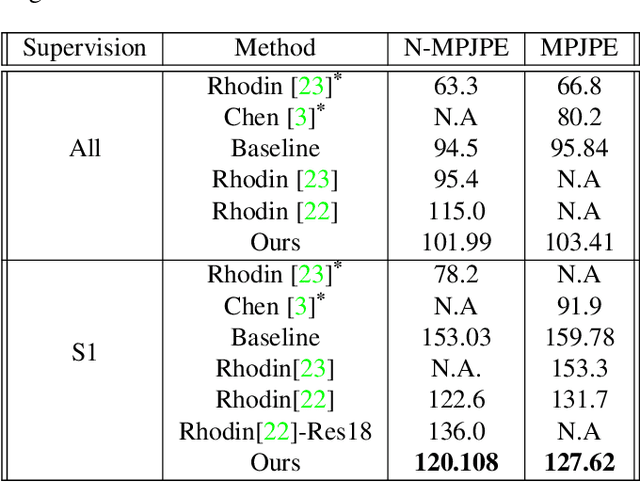
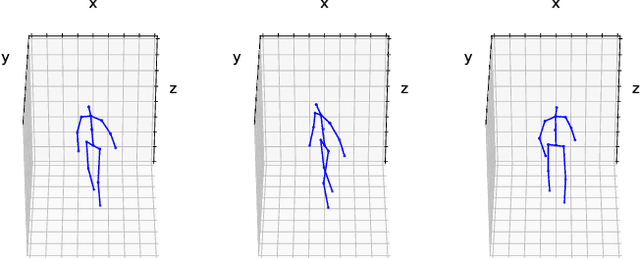

Estimating 3D human pose from monocular images demands large amounts of 3D pose and in-the-wild 2D pose annotated datasets which are costly and require sophisticated systems to acquire. In this regard, we propose a metric learning based approach to jointly learn a rich embedding and 3D pose regression from the embedding using multi-view synchronised videos of human motions and very limited 3D pose annotations. The inclusion of metric learning to the baseline pose estimation framework improves the performance by 21\% when 3D supervision is limited. In addition, we make use of a person-identity based adversarial loss as additional weak supervision to outperform state-of-the-art whilst using a much smaller network. Lastly, but importantly, we demonstrate the advantages of the learned embedding and establish view-invariant pose retrieval benchmarks on two popular, publicly available multi-view human pose datasets, Human 3.6M and MPI-INF-3DHP, to facilitate future research.