 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose Estimation under limited supervision using Metric Learning
Aug 14, 2019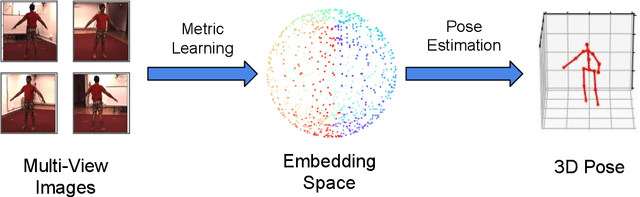
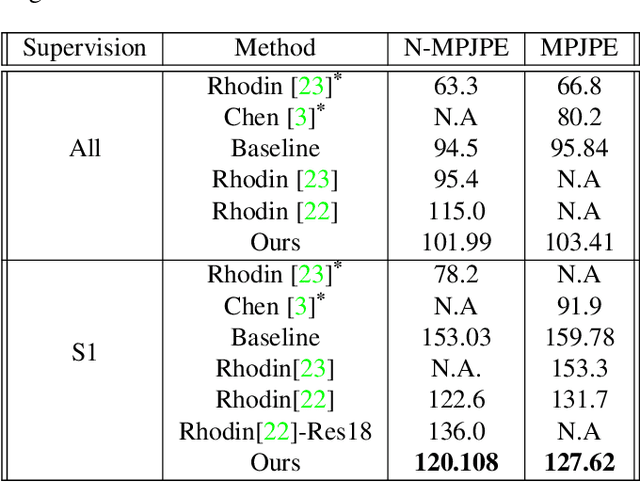
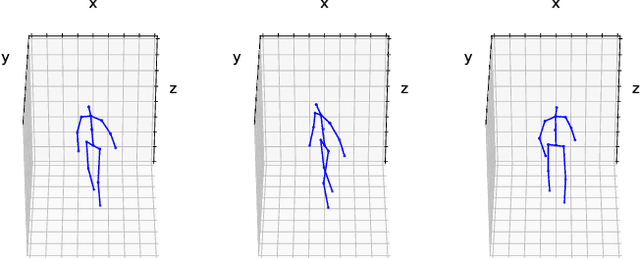

Estimating 3D human pose from monocular images demands large amounts of 3D pose and in-the-wild 2D pose annotated datasets which are costly and require sophisticated systems to acquire. In this regard, we propose a metric learning based approach to jointly learn a rich embedding and 3D pose regression from the embedding using multi-view synchronised videos of human motions and very limited 3D pose annotations. The inclusion of metric learning to the baseline pose estimation framework improves the performance by 21\% when 3D supervision is limited. In addition, we make use of a person-identity based adversarial loss as additional weak supervision to outperform state-of-the-art whilst using a much smaller network. Lastly, but importantly, we demonstrate the advantages of the learned embedding and establish view-invariant pose retrieval benchmarks on two popular, publicly available multi-view human pose datasets, Human 3.6M and MPI-INF-3DHP, to facilitate future research.
Relation Networks for Optic Disc and Fovea Localization in Retinal Images
Nov 23, 2018

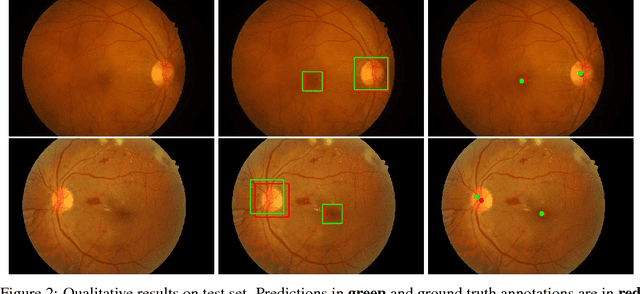
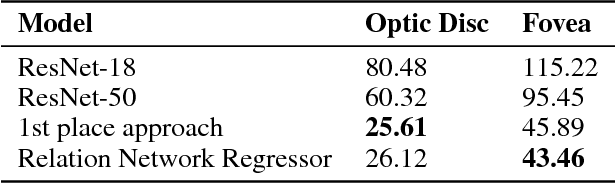
Diabetic Retinopathy is the leading cause of blindness in the world. At least 90\% of new cases can be reduced with proper treatment and monitoring of the eyes. However, scanning the entire population of patients is a difficult endeavor. Computer-aided diagnosis tools in retinal image analysis can make the process scalable and efficient. In this work, we focus on the problem of localizing the centers of the Optic disc and Fovea, a task crucial to the analysis of retinal scans. Current systems recognize the Optic disc and Fovea individually, without exploiting their relations during learning. We propose a novel approach to localizing the centers of the Optic disc and Fovea by simultaneously processing them and modeling their relative geometry and appearance. We show that our approach improves localization and recognition by incorporating object-object relations efficiently, and achieves highly competitive results.
Slum Segmentation and Change Detection : A Deep Learning Approach
Nov 19, 2018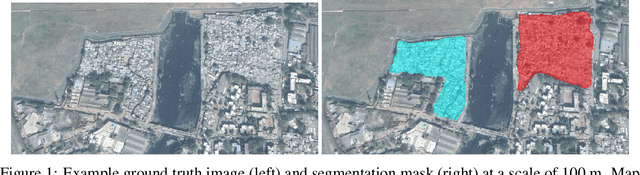
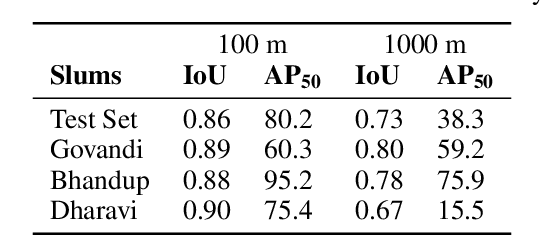
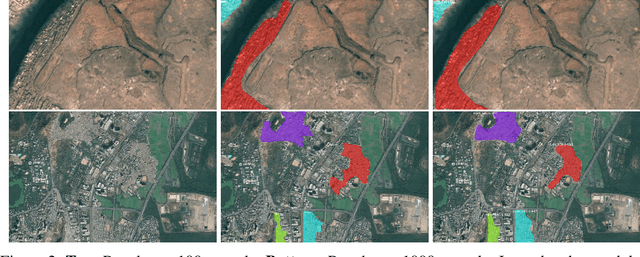

More than one billion people live in slums around the world. In some developing countries, slum residents make up for more than half of the population and lack reliable sanitation services, clean water, electricity, other basic services. Thus, slum rehabilitation and improvement is an important global challenge, and a significant amount of effort and resources have been put into this endeavor. These initiatives rely heavily on slum mapping and monitoring, and it is essential to have robust and efficient methods for mapping and monitoring existing slum settlements. In this work, we introduce an approach to segment and map individual slums from satellite imagery, leveraging regional convolutional neural networks for instance segmentation using transfer learning. In addition, we also introduce a method to perform change detection and monitor slum change over time. We show that our approach effectively learns slum shape and appearance, and demonstrates strong quantitative results, resulting in a maximum AP of 80.0.