 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language to Code Using Transformers
Feb 01, 2022We tackle the problem of generating code snippets from natural language descriptions using the CoNaLa dataset. We use the self-attention based transformer architecture and show that it performs better than recurrent attention-based encoder decoder. Furthermore, we develop a modified form of back translation and use cycle consistent losses to train the model in an end-to-end fashion. We achieve a BLEU score of 16.99 beating the previously reported baseline of the CoNaLa challenge.
Normal Assisted Stereo Depth Estimation
Dec 23, 2019


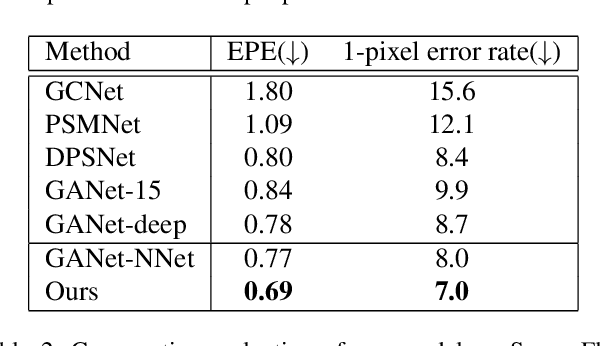
Accurate stereo depth estimation plays a critical role in various 3D tasks in both indoor and outdoor environments. Recently, learning-based multi-view stereo methods have demonstrated competitive performance with limited number of views. However, in challenging scenarios, especially when building cross-view correspondences is hard, these methods still cannot produce satisfying results. In this paper, we study how to enforce the consistency between surface normal and depth at training time to improve the performance. We couple the learning of a multi-view normal estimation module and a multi-view depth estimation module. In addition, we propose a novel consistency loss to train an independent consistency module that refines the depths from depth/normal pairs. We find that the joint learning can improve both the prediction of normal and depth, and the accuracy and smoothness can be further improved by enforcing the consistency. Experiments on MVS, SUN3D, RGBD and Scenes11 demonstrate the effectiveness of our method and state-of-the-art performance.
Learning 3D Human Pose from Structure and Motion
Jul 03, 2018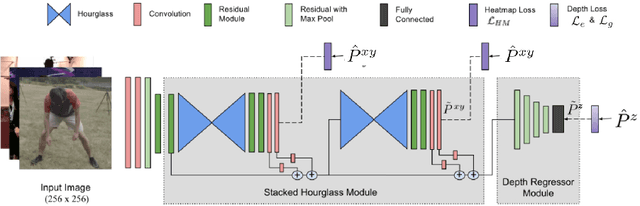
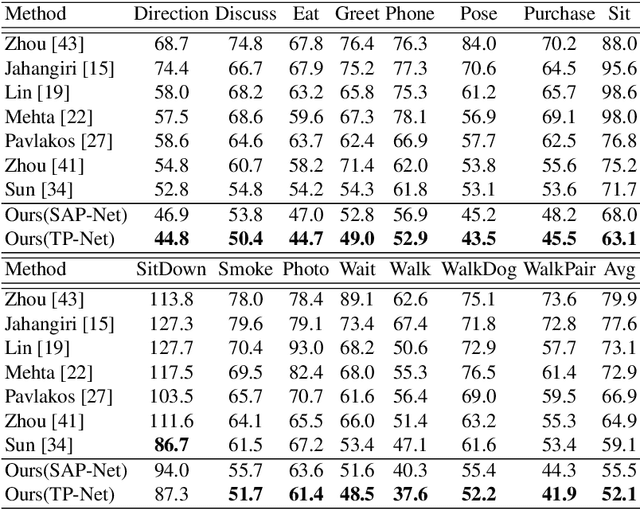
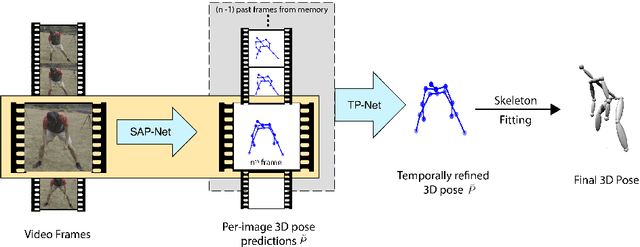
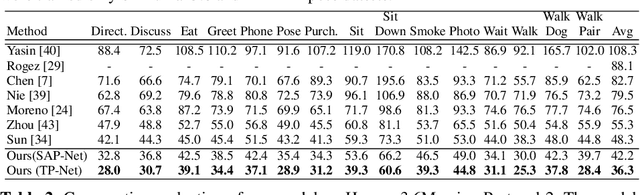
3D human pose estimation from a single image is a challenging problem, especially for in-the-wild settings due to the lack of 3D annotated data. We propose two anatomically inspired loss functions and use them with a weakly-supervised learning framework to jointly learn from large-scale in-the-wild 2D and indoor/synthetic 3D data. We also present a simple temporal network that exploits temporal and structural cues present in predicted pose sequences to temporally harmonize the pose estimations. We carefully analyze the proposed contributions through loss surface visualizations and sensitivity analysis to facilitate deeper understanding of their working mechanism. Our complete pipeline improves the state-of-the-art by 11.8% and 12% on Human3.6M and MPI-INF-3DHP, respectively, and runs at 30 FPS on a commodity graphics card.