 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Spaces for Creatively Connecting and Expressing Visual Concepts
Dec 16, 2025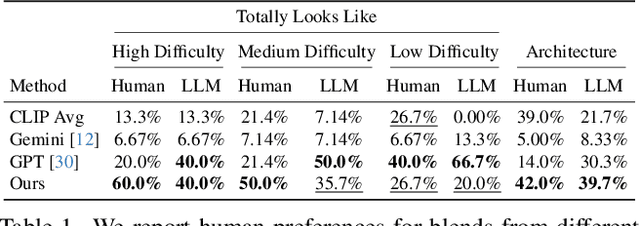

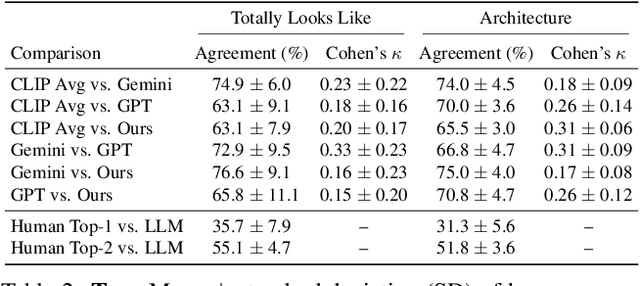
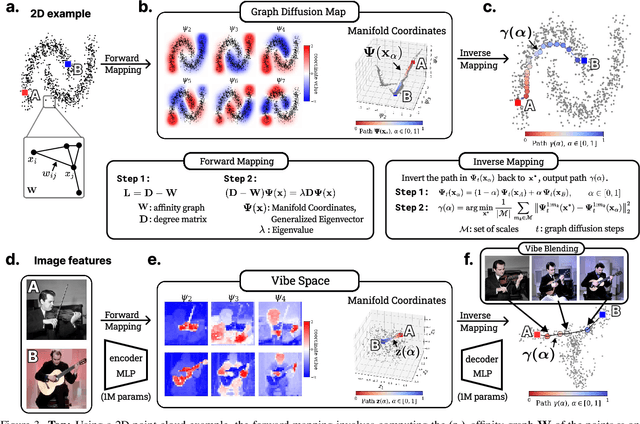
Creating new visual concepts often requires connecting distinct ideas through their most relevant shared attributes -- their vibe. We introduce Vibe Blending, a novel task for generating coherent and meaningful hybrids that reveals these shared attributes between images. Achieving such blends is challenging for current methods, which struggle to identify and traverse nonlinear paths linking distant concepts in latent space. We propose Vibe Space, a hierarchical graph manifold that learns low-dimensional geodesics in feature spaces like CLIP, enabling smooth and semantically consistent transitions between concepts. To evaluate creative quality, we design a cognitively inspired framework combining human judgments, LLM reasoning, and a geometric path-based difficulty score. We find that Vibe Space produces blends that humans consistently rate as more creative and coherent than current methods.
"I Know It When I See It": Mood Spaces for Connecting and Expressing Visual Concepts
Apr 21, 2025



Expressing complex concepts is easy when they can be labeled or quantified, but many ideas are hard to define yet instantly recognizable. We propose a Mood Board, where users convey abstract concepts with examples that hint at the intended direction of attribute changes. We compute an underlying Mood Space that 1) factors out irrelevant features and 2) finds the connections between images, thus bringing relevant concepts closer. We invent a fibration computation to compress/decompress pre-trained features into/from a compact space, 50-100x smaller. The main innovation is learning to mimic the pairwise affinity relationship of the image tokens across exemplars. To focus on the coarse-to-fine hierarchical structures in the Mood Space, we compute the top eigenvector structure from the affinity matrix and define a loss in the eigenvector space. The resulting Mood Space is locally linear and compact, allowing image-level operations, such as object averaging, visual analogy, and pose transfer, to be performed as a simple vector operation in Mood Space. Our learning is efficient in computation without any fine-tuning, needs only a few (2-20) exemplars, and takes less than a minute to learn.
AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space
Jun 26, 2024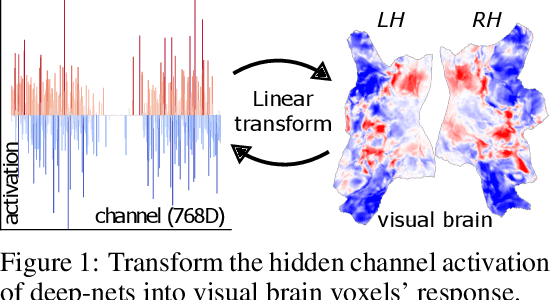
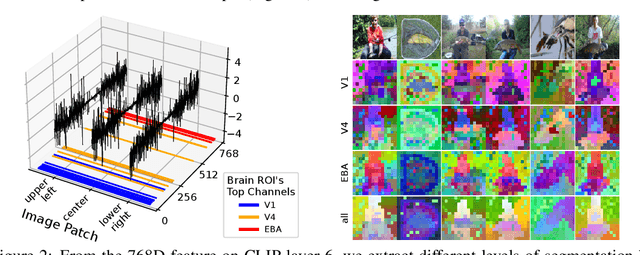

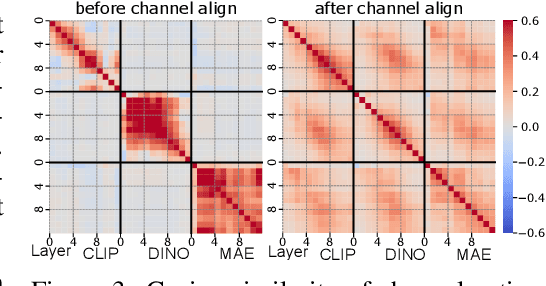
We study the intriguing connection between visual data, deep networks, and the brain. Our method creates a universal channel alignment by using brain voxel fMRI response prediction as the training objective. We discover that deep networks, trained with different objectives, share common feature channels across various models. These channels can be clustered into recurring sets, corresponding to distinct brain regions, indicating the formation of visual concepts. Tracing the clusters of channel responses onto the images, we see semantically meaningful object segments emerge, even without any supervised decoder. Furthermore, the universal feature alignment and the clustering of channels produce a picture and quantification of how visual information is processed through the different network layers, which produces precise comparisons between the networks.
Brain Decodes Deep Nets
Dec 03, 2023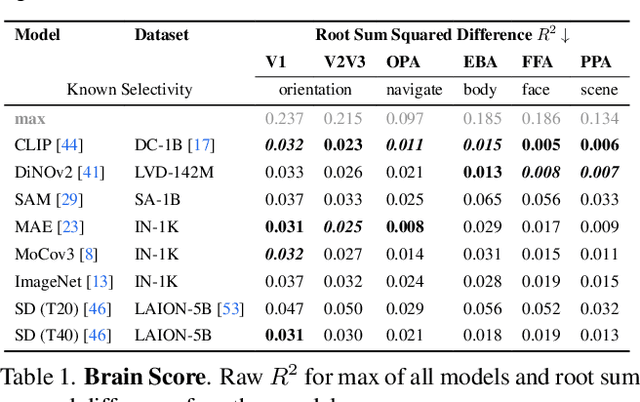
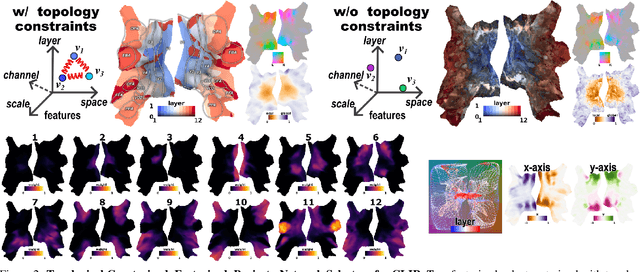

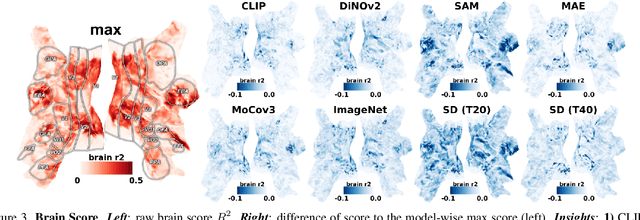
We developed a tool for visualizing and analyzing large pre-trained vision models by mapping them onto the brain, thus exposing their hidden inside. Our innovation arises from a surprising usage of brain encoding: predicting brain fMRI measurements in response to images. We report two findings. First, explicit mapping between the brain and deep-network features across dimensions of space, layers, scales, and channels is crucial. This mapping method, FactorTopy, is plug-and-play for any deep-network; with it, one can paint a picture of the network onto the brain (literally!). Second, our visualization shows how different training methods matter: they lead to remarkable differences in hierarchical organization and scaling behavior, growing with more data or network capacity. It also provides insight into finetuning: how pre-trained models change when adapting to small datasets. Our method is practical: only 3K images are enough to learn a network-to-brain mapping.
Memory Encoding Model
Aug 02, 2023



We explore a new class of brain encoding model by adding memory-related information as input. Memory is an essential brain mechanism that works alongside visual stimuli. During a vision-memory cognitive task, we found the non-visual brain is largely predictable using previously seen images. Our Memory Encoding Model (Mem) won the Algonauts 2023 visual brain competition even without model ensemble (single model score 66.8, ensemble score 70.8). Our ensemble model without memory input (61.4) can also stand a 3rd place. Furthermore, we observe periodic delayed brain response correlated to 6th-7th prior image, and hippocampus also showed correlated activity timed with this periodicity. We conjuncture that the periodic replay could be related to memory mechanism to enhance the working memory.
Retinotopy Inspired Brain Encoding Model and the All-for-One Training Recipe
Jul 26, 2023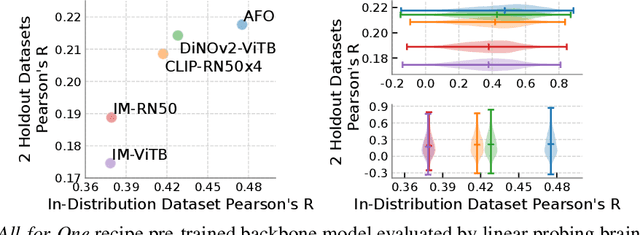
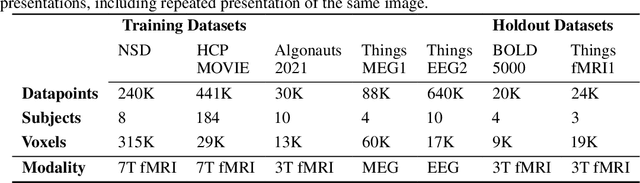
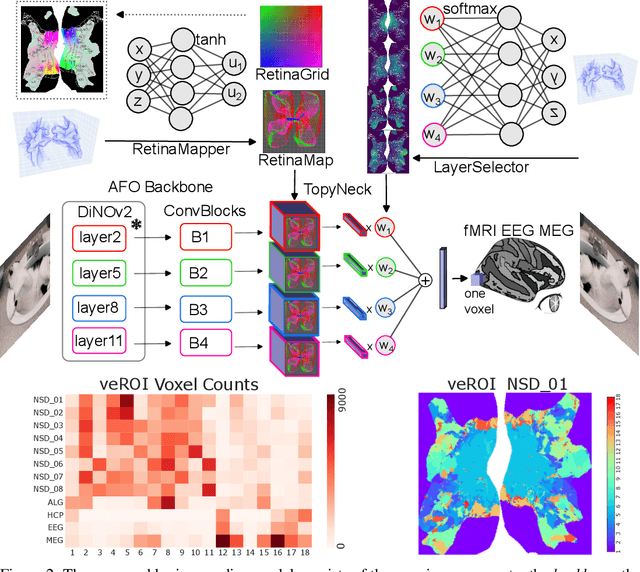
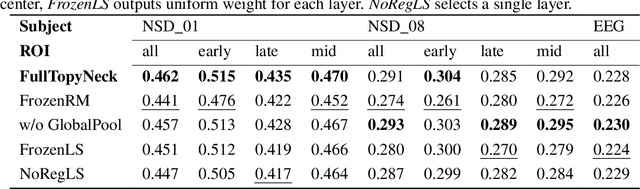
Brain encoding models aim to predict brain voxel-wise responses to stimuli images, replicating brain signals captured by neuroimaging techniques. There is a large volume of publicly available data, but training a comprehensive brain encoding model is challenging. The main difficulties stem from a) diversity within individual brain, with functional heterogeneous brain regions; b) diversity of brains from different subjects, due to genetic and developmental differences; c) diversity of imaging modalities and processing pipelines. We use this diversity to our advantage by introducing the All-for-One training recipe, which divides the challenging one-big-model problem into multiple small models, with the small models aggregating the knowledge while preserving the distinction between the different functional regions. Agnostic of the training recipe, we use biological knowledge of the brain, specifically retinotopy, to introduce inductive bias to learn a 3D brain-to-image mapping that ensures a) each neuron knows which image regions and semantic levels to gather information, and b) no neurons are left behind in the model. We pre-trained a brain encoding model using over one million data points from five public datasets spanning three imaging modalities. To the best of our knowledge, this is the most comprehensive brain encoding model to the date. We demonstrate the effectiveness of the pre-trained model as a drop-in replacement for commonly used vision backbone models. Furthermore, we demonstrate the application of the model to brain decoding. Code and the model checkpoint will be made available.