 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinotopy Inspired Brain Encoding Model and the All-for-One Training Recipe
Paper and Code
Jul 26, 2023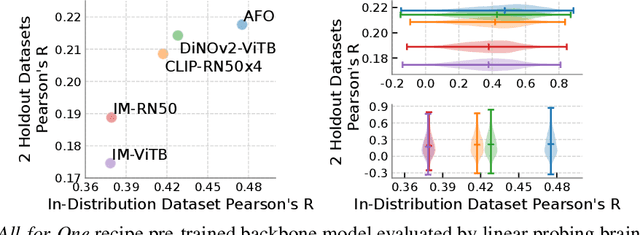
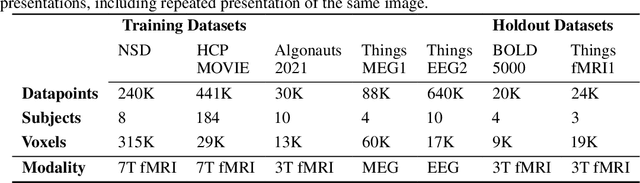
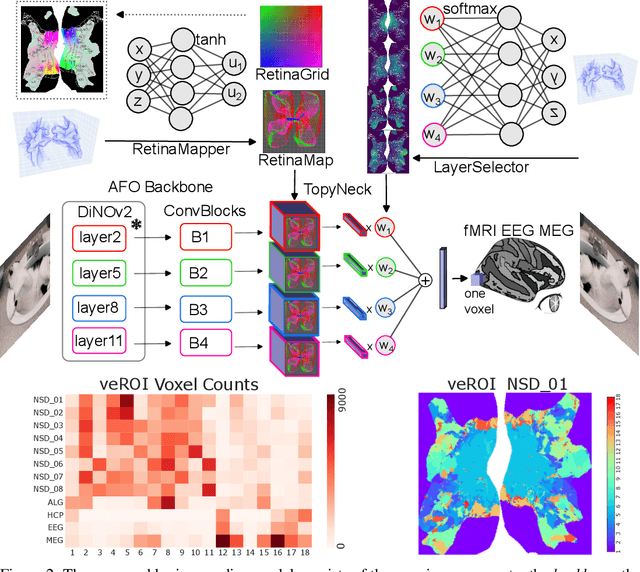
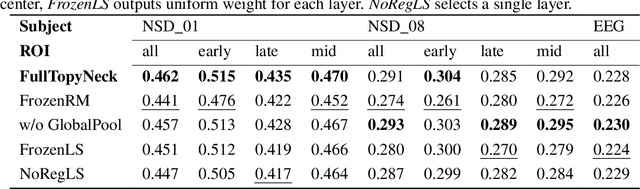
Brain encoding models aim to predict brain voxel-wise responses to stimuli images, replicating brain signals captured by neuroimaging techniques. There is a large volume of publicly available data, but training a comprehensive brain encoding model is challenging. The main difficulties stem from a) diversity within individual brain, with functional heterogeneous brain regions; b) diversity of brains from different subjects, due to genetic and developmental differences; c) diversity of imaging modalities and processing pipelines. We use this diversity to our advantage by introducing the All-for-One training recipe, which divides the challenging one-big-model problem into multiple small models, with the small models aggregating the knowledge while preserving the distinction between the different functional regions. Agnostic of the training recipe, we use biological knowledge of the brain, specifically retinotopy, to introduce inductive bias to learn a 3D brain-to-image mapping that ensures a) each neuron knows which image regions and semantic levels to gather information, and b) no neurons are left behind in the model. We pre-trained a brain encoding model using over one million data points from five public datasets spanning three imaging modalities. To the best of our knowledge, this is the most comprehensive brain encoding model to the date. We demonstrate the effectiveness of the pre-trained model as a drop-in replacement for commonly used vision backbone models. Furthermore, we demonstrate the application of the model to brain decoding. Code and the model checkpoint will be made available.