 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Visual Place Recognition with Structural Cues
Paper and Code
Feb 29, 2020
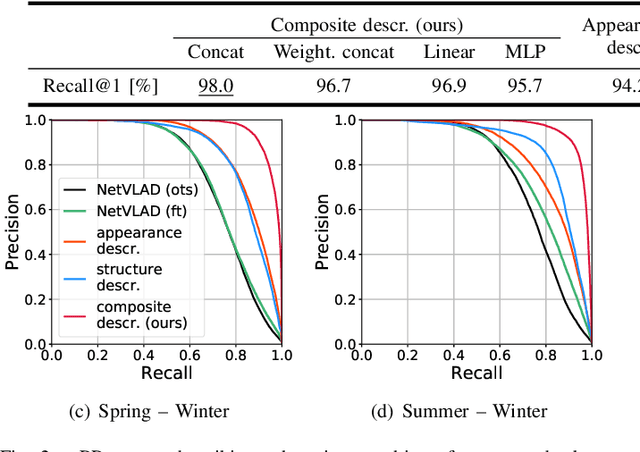
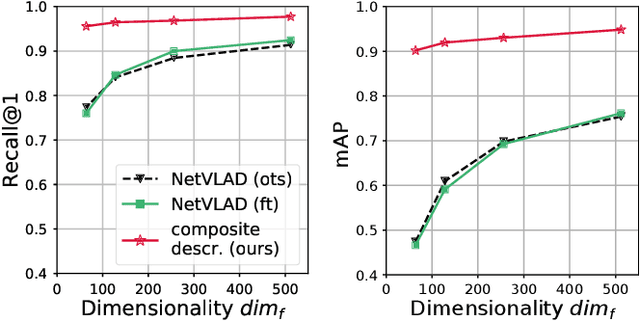
In this paper, we propose to augment image-based place recognition with structural cues. Specifically, these structural cues are obtained using structure-from-motion, such that no additional sensors are needed for place recognition. This is achieved by augmenting the 2D convolutional neural network (CNN) typically used for image-based place recognition with a 3D CNN that takes as input a voxel grid derived from the structure-from-motion point cloud. We evaluate different methods for fusing the 2D and 3D features and obtain best performance with global average pooling and simple concatenation. The resulting descriptor exhibits superior recognition performance compared to descriptors extracted from only one of the input modalities, including state-of-the-art image-based descriptors. Especially at low descriptor dimensionalities, we outperform state-of-the-art descriptors by up to 90%.