 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCracking Double-Blind Review: Authorship Attribution with Deep Learning
Paper and Code
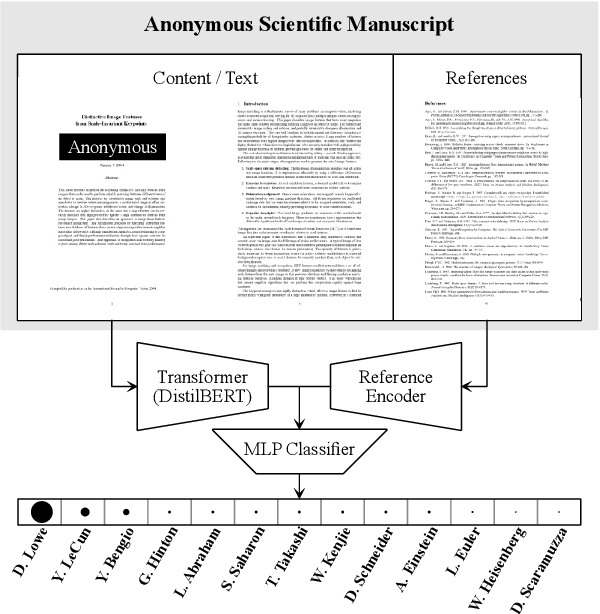



Double-blind peer review is considered a pillar of academic research because it is perceived to ensure a fair, unbiased, and fact-centered scientific discussion. Yet, experienced researchers can often correctly guess from which research group an anonymous submission originates, biasing the peer-review process. In this work, we present a transformer-based, neural-network architecture that only uses the text content and the author names in the bibliography to atttribute an anonymous manuscript to an author. To train and evaluate our method, we created the largest authorship-identification dataset to date. It leverages all research papers publicly available on arXiv amounting to over 2 million manuscripts. In arXiv-subsets with up to 2,000 different authors, our method achieves an unprecedented authorship attribution accuracy, where up to 95% of papers are attributed correctly. Thanks to our method, we are not only able to predict the author of an anonymous work but we also identify weaknesses of the double-blind review process by finding the key aspects that make a paper attributable. We believe that this work gives precious insights into how a submission can remain anonymous in order to support an unbiased double-blind review process.