 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal OnTheFly Feedback Control of Event Sensors
Aug 23, 2024

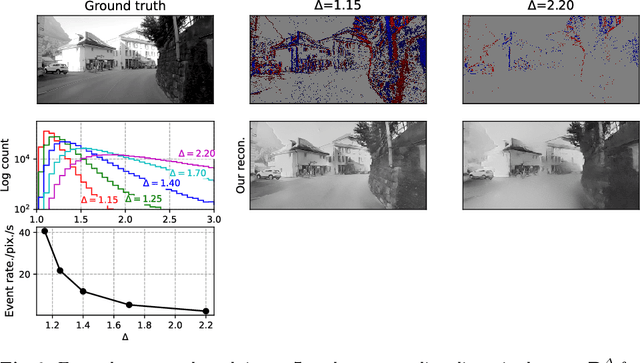
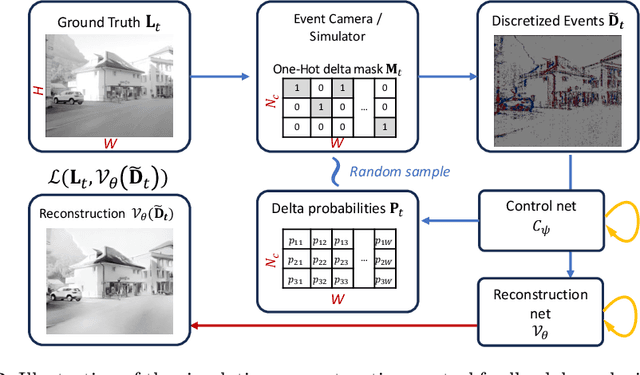
Event-based vision sensors produce an asynchronous stream of events which are triggered when the pixel intensity variation exceeds a predefined threshold. Such sensors offer significant advantages, including reduced data redundancy, micro-second temporal resolution, and low power consumption, making them valuable for applications in robotics and computer vision. In this work, we consider the problem of video reconstruction from events, and propose an approach for dynamic feedback control of activation thresholds, in which a controller network analyzes the past emitted events and predicts the optimal distribution of activation thresholds for the following time segment. Additionally, we allow a user-defined target peak-event-rate for which the control network is conditioned and optimized to predict per-column activation thresholds that would eventually produce the best possible video reconstruction. The proposed OnTheFly control scheme is data-driven and trained in an end-to-end fashion using probabilistic relaxation of the discrete event representation. We demonstrate that our approach outperforms both fixed and randomly-varying threshold schemes by 6-12% in terms of LPIPS perceptual image dissimilarity metric, and by 49% in terms of event rate, achieving superior reconstruction quality while enabling a fine-tuned balance between performance accuracy and the event rate. Additionally, we show that sampling strategies provided by our OnTheFly control are interpretable and reflect the characteristics of the scene. Our results, derived from a physically-accurate simulator, underline the promise of the proposed methodology in enhancing the utility of event cameras for image reconstruction and other downstream tasks, paving the way for hardware implementation of dynamic feedback EVS control in silicon.
Event-based Shape from Polarization
Jan 17, 2023State-of-the-art solutions for Shape-from-Polarization (SfP) suffer from a speed-resolution tradeoff: they either sacrifice the number of polarization angles measured or necessitate lengthy acquisition times due to framerate constraints, thus compromising either accuracy or latency. We tackle this tradeoff using event cameras. Event cameras operate at microseconds resolution with negligible motion blur, and output a continuous stream of events that precisely measures how light changes over time asynchronously. We propose a setup that consists of a linear polarizer rotating at high-speeds in front of an event camera. Our method uses the continuous event stream caused by the rotation to reconstruct relative intensities at multiple polarizer angles. Experiments demonstrate that our method outperforms physics-based baselines using frames, reducing the MAE by 25% in synthetic and real-world dataset. In the real world, we observe, however, that the challenging conditions (i.e., when few events are generated) harm the performance of physics-based solutions. To overcome this, we propose a learning-based approach that learns to estimate surface normals even at low event-rates, improving the physics-based approach by 52% on the real world dataset. The proposed system achieves an acquisition speed equivalent to 50 fps (>twice the framerate of the commercial polarization sensor) while retaining the spatial resolution of 1MP. Our evaluation is based on the first large-scale dataset for event-based SfP
Event Guided Depth Sensing
Oct 20, 2021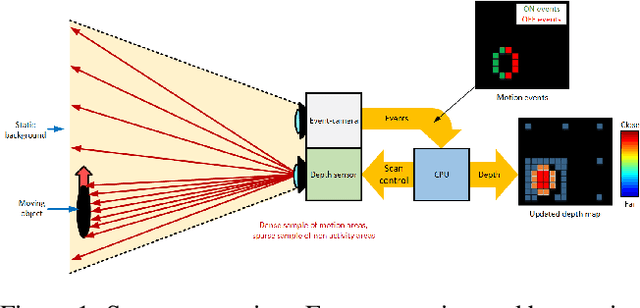


Active depth sensors like structured light, lidar, and time-of-flight systems sample the depth of the entire scene uniformly at a fixed scan rate. This leads to limited spatio-temporal resolution where redundant static information is over-sampled and precious motion information might be under-sampled. In this paper, we present an efficient bio-inspired event-camera-driven depth estimation algorithm. In our approach, we dynamically illuminate areas of interest densely, depending on the scene activity detected by the event camera, and sparsely illuminate areas in the field of view with no motion. The depth estimation is achieved by an event-based structured light system consisting of a laser point projector coupled with a second event-based sensor tuned to detect the reflection of the laser from the scene. We show the feasibility of our approach in a simulated autonomous driving scenario and real indoor sequences using our prototype. We show that, in natural scenes like autonomous driving and indoor environments, moving edges correspond to less than 10% of the scene on average. Thus our setup requires the sensor to scan only 10% of the scene, which could lead to almost 90% less power consumption by the illumination source. While we present the evaluation and proof-of-concept for an event-based structured-light system, the ideas presented here are applicable for a wide range of depth-sensing modalities like LIDAR, time-of-flight, and standard stereo.
PRED18: Dataset and Further Experiments with DAVIS Event Camera in Predator-Prey Robot Chasing
Jul 02, 2018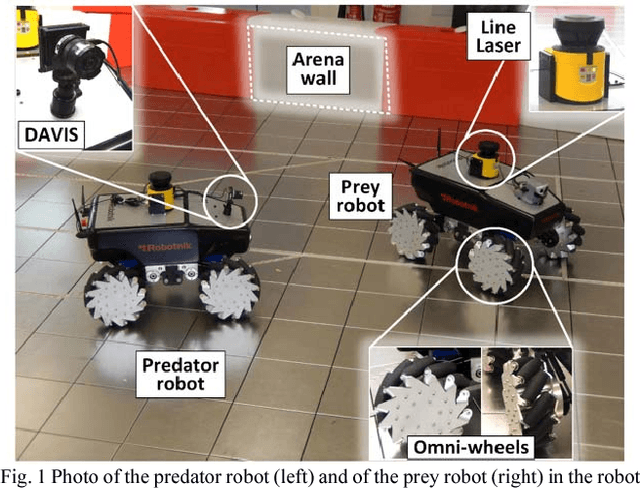
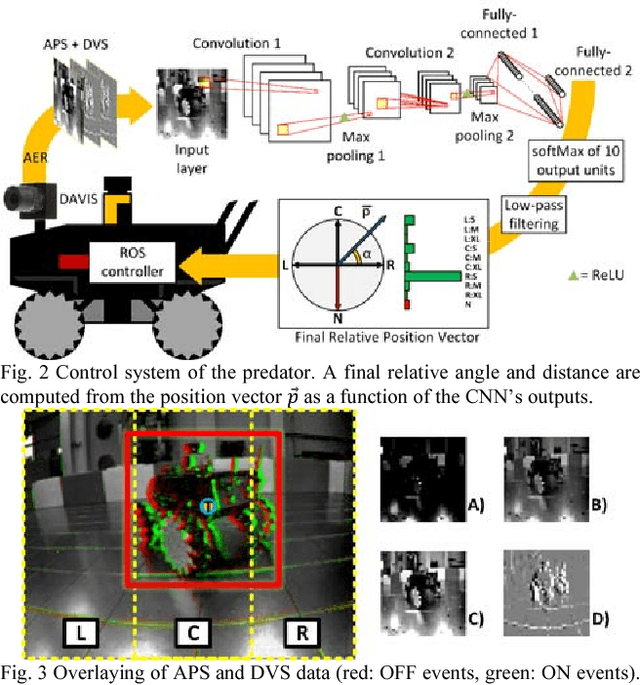

Machine vision systems using convolutional neural networks (CNNs) for robotic applications are increasingly being developed. Conventional vision CNNs are driven by camera frames at constant sample rate, thus achieving a fixed latency and power consumption tradeoff. This paper describes further work on the first experiments of a closed-loop robotic system integrating a CNN together with a Dynamic and Active Pixel Vision Sensor (DAVIS) in a predator/prey scenario. The DAVIS, mounted on the predator Summit XL robot, produces frames at a fixed 15 Hz frame-rate and Dynamic Vision Sensor (DVS) histograms containing 5k ON and OFF events at a variable frame-rate ranging from 15-500 Hz depending on the robot speeds. In contrast to conventional frame-based systems, the latency and processing cost depends on the rate of change of the image. The CNN is trained offline on the 1.25h labeled dataset to recognize the position and size of the prey robot, in the field of view of the predator. During inference, combining the ten output classes of the CNN allows extracting the analog position vector of the prey relative to the predator with a mean 8.7% error in angular estimation. The system is compatible with conventional deep learning technology, but achieves a variable latency-power tradeoff that adapts automatically to the dynamics. Finally, investigations on the robustness of the algorithm, a human performance comparison and a deconvolution analysis are also explored.
* 8 pages
Steering a Predator Robot using a Mixed Frame/Event-Driven Convolutional Neural Network
Jun 30, 2016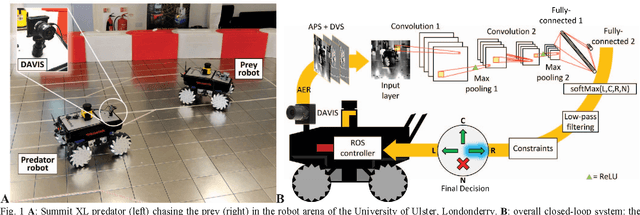


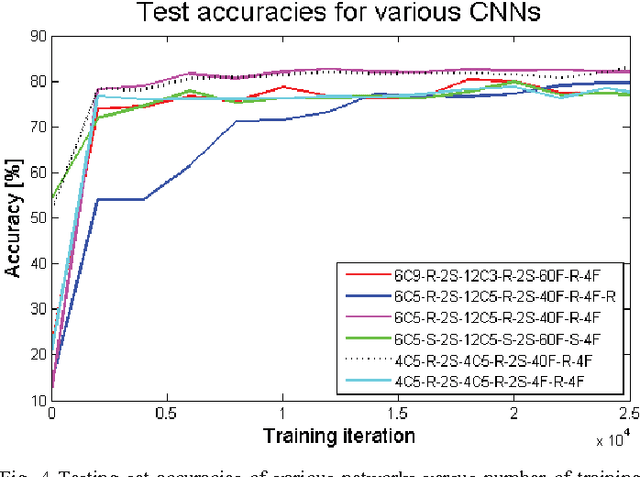
This paper describes the application of a Convolutional Neural Network (CNN) in the context of a predator/prey scenario. The CNN is trained and run on data from a Dynamic and Active Pixel Sensor (DAVIS) mounted on a Summit XL robot (the predator), which follows another one (the prey). The CNN is driven by both conventional image frames and dynamic vision sensor "frames" that consist of a constant number of DAVIS ON and OFF events. The network is thus "data driven" at a sample rate proportional to the scene activity, so the effective sample rate varies from 15 Hz to 240 Hz depending on the robot speeds. The network generates four outputs: steer right, left, center and non-visible. After off-line training on labeled data, the network is imported on the on-board Summit XL robot which runs jAER and receives steering directions in real time. Successful results on closed-loop trials, with accuracies up to 87% or 92% (depending on evaluation criteria) are reported. Although the proposed approach discards the precise DAVIS event timing, it offers the significant advantage of compatibility with conventional deep learning technology without giving up the advantage of data-driven computing.