 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowMRI-Net: A generalizable self-supervised physics-driven 4D Flow MRI reconstruction network for aortic and cerebrovascular applications
Oct 11, 2024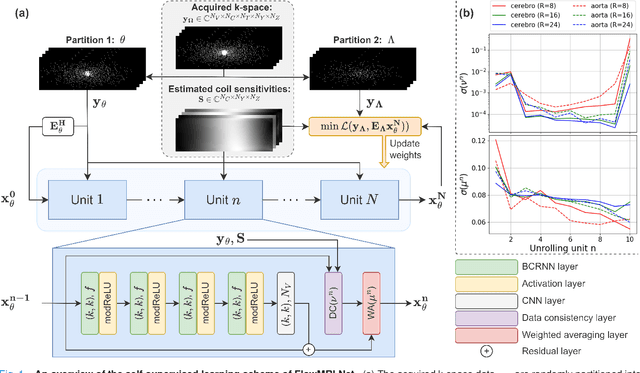
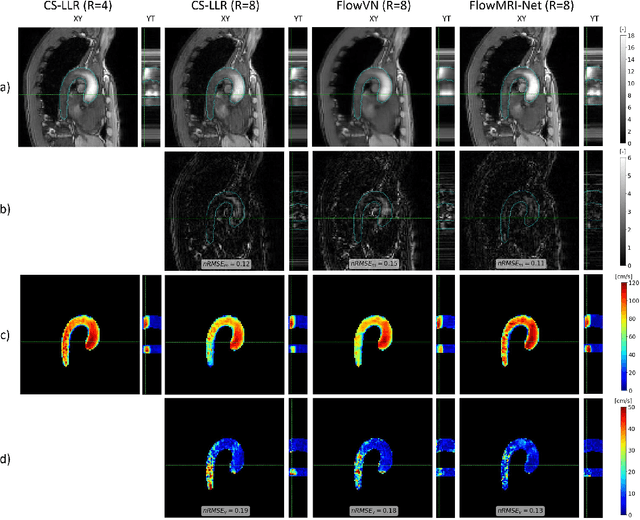
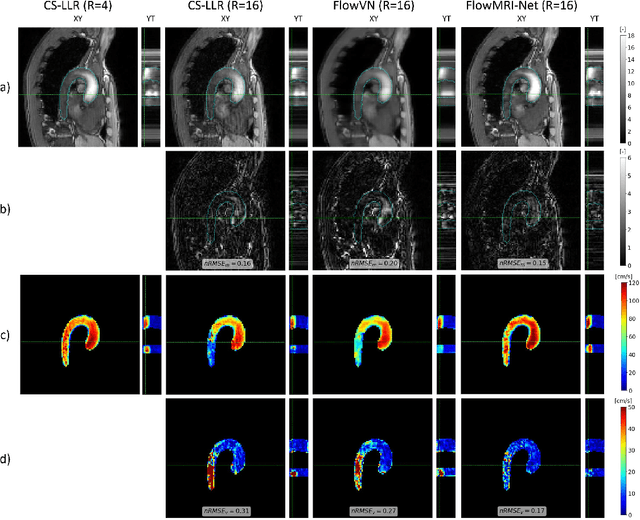
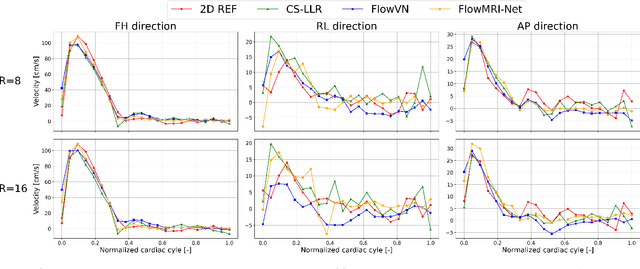
In this work, we propose FlowMRI-Net, a novel deep learning-based framework for fast reconstruction of accelerated 4D flow magnetic resonance imaging (MRI) using physics-driven unrolled optimization and a complexvalued convolutional recurrent neural network trained in a self-supervised manner. The generalizability of the framework is evaluated using aortic and cerebrovascular 4D flow MRI acquisitions acquired on systems from two different vendors for various undersampling factors (R=8,16,24) and compared to state-of-the-art compressed sensing (CS-LLR) and deep learning-based (FlowVN) reconstructions. Evaluation includes quantitative analysis of image magnitudes, velocity magnitudes, and peak velocity curves. FlowMRINet outperforms CS-LLR and FlowVN for aortic 4D flow MRI reconstruction, resulting in vectorial normalized root mean square errors of $0.239\pm0.055$, $0.308\pm0.066$, and $0.302\pm0.085$ and mean directional errors of $0.023\pm0.015$, $0.036\pm0.018$, and $0.039\pm0.025$ for velocities in the thoracic aorta for R=16, respectively. Furthermore, FlowMRI-Net outperforms CS-LLR for cerebrovascular 4D flow MRI reconstruction, where no FlowVN can be trained due to the lack of a highquality reference, resulting in a consistent increase in SNR of around 6 dB and more accurate peak velocity curves for R=8,16,24. Reconstruction times ranged from 1 to 7 minutes on commodity CPU/GPU hardware. FlowMRI-Net enables fast and accurate quantification of aortic and cerebrovascular flow dynamics, with possible applications to other vascular territories. This will improve clinical adaptation of 4D flow MRI and hence may aid in the diagnosis and therapeutic management of cardiovascular diseases.
Optimal OnTheFly Feedback Control of Event Sensors
Aug 23, 2024

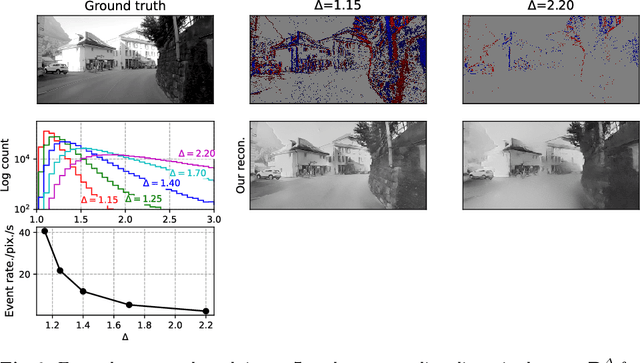
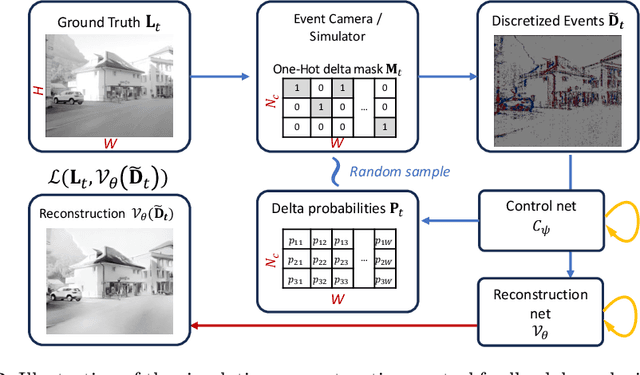
Event-based vision sensors produce an asynchronous stream of events which are triggered when the pixel intensity variation exceeds a predefined threshold. Such sensors offer significant advantages, including reduced data redundancy, micro-second temporal resolution, and low power consumption, making them valuable for applications in robotics and computer vision. In this work, we consider the problem of video reconstruction from events, and propose an approach for dynamic feedback control of activation thresholds, in which a controller network analyzes the past emitted events and predicts the optimal distribution of activation thresholds for the following time segment. Additionally, we allow a user-defined target peak-event-rate for which the control network is conditioned and optimized to predict per-column activation thresholds that would eventually produce the best possible video reconstruction. The proposed OnTheFly control scheme is data-driven and trained in an end-to-end fashion using probabilistic relaxation of the discrete event representation. We demonstrate that our approach outperforms both fixed and randomly-varying threshold schemes by 6-12% in terms of LPIPS perceptual image dissimilarity metric, and by 49% in terms of event rate, achieving superior reconstruction quality while enabling a fine-tuned balance between performance accuracy and the event rate. Additionally, we show that sampling strategies provided by our OnTheFly control are interpretable and reflect the characteristics of the scene. Our results, derived from a physically-accurate simulator, underline the promise of the proposed methodology in enhancing the utility of event cameras for image reconstruction and other downstream tasks, paving the way for hardware implementation of dynamic feedback EVS control in silicon.
Training Variational Networks with Multi-Domain Simulations: Speed-of-Sound Image Reconstruction
Jun 25, 2020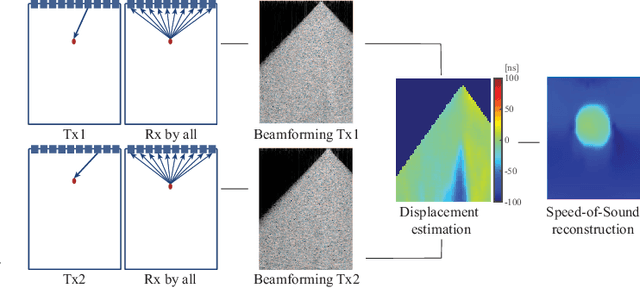
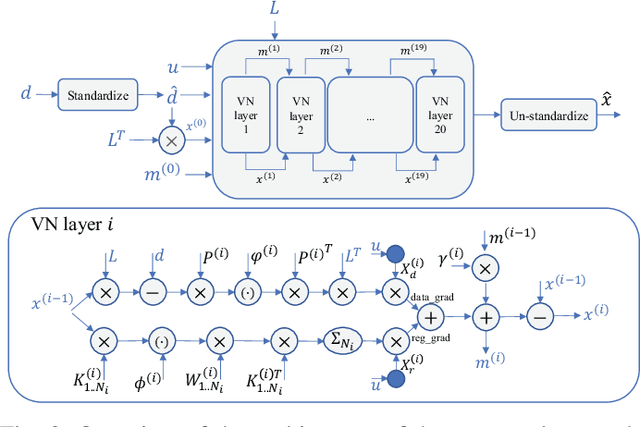
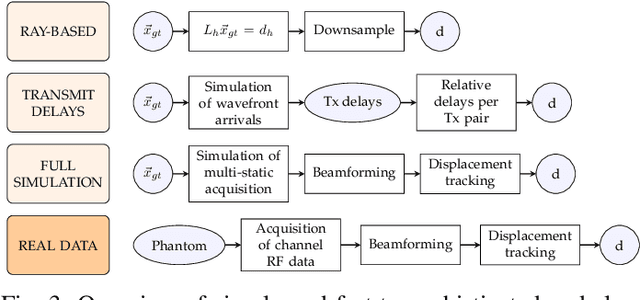

Speed-of-sound has been shown as a potential biomarker for breast cancer imaging, successfully differentiating malignant tumors from benign ones. Speed-of-sound images can be reconstructed from time-of-flight measurements from ultrasound images acquired using conventional handheld ultrasound transducers. Variational Networks (VN) have recently been shown to be a potential learning-based approach for optimizing inverse problems in image reconstruction. Despite earlier promising results, these methods however do not generalize well from simulated to acquired data, due to the domain shift. In this work, we present for the first time a VN solution for a pulse-echo SoS image reconstruction problem using diverging waves with conventional transducers and single-sided tissue access. This is made possible by incorporating simulations with varying complexity into training. We use loop unrolling of gradient descent with momentum, with an exponentially weighted loss of outputs at each unrolled iteration in order to regularize training. We learn norms as activation functions regularized to have smooth forms for robustness to input distribution variations. We evaluate reconstruction quality on ray-based and full-wave simulations as well as on tissue-mimicking phantom data, in comparison to a classical iterative (L-BFGS) optimization of this image reconstruction problem. We show that the proposed regularization techniques combined with multi-source domain training yield substantial improvements in the domain adaptation capabilities of VN, reducing median RMSE by 54% on a wave-based simulation dataset compared to the baseline VN. We also show that on data acquired from a tissue-mimicking breast phantom the proposed VN provides improved reconstruction in 12 milliseconds.
Deep Network for Scatterer Distribution Estimation for Ultrasound Image Simulation
Jun 17, 2020


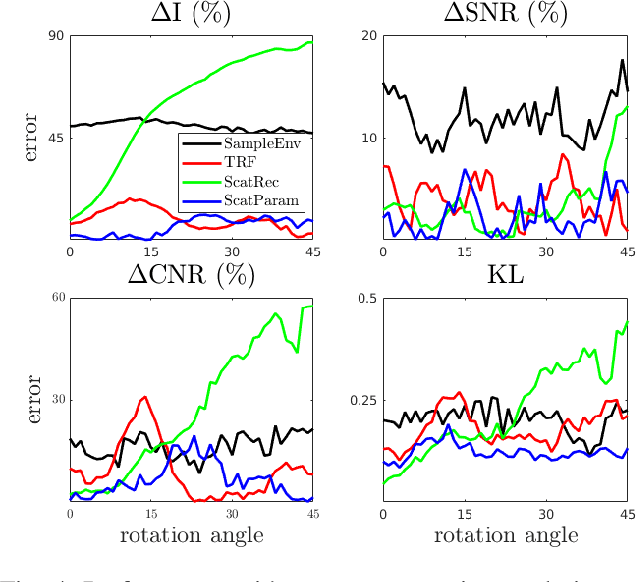
Simulation-based ultrasound training can be an essential educational tool. Realistic ultrasound image appearance with typical speckle texture can be modeled as convolution of a point spread function with point scatterers representing tissue microstructure. Such scatterer distribution, however, is in general not known and its estimation for a given tissue type is fundamentally an ill-posed inverse problem. In this paper, we demonstrate a convolutional neural network approach for probabilistic scatterer estimation from observed ultrasound data. We herein propose to impose a known statistical distribution on scatterers and learn the mapping between ultrasound image and distribution parameter map by training a convolutional neural network on synthetic images. In comparison with several existing approaches, we demonstrate in numerical simulations and with in-vivo images that the synthesized images from scatterer representations estimated with our approach closely match the observations with varying acquisition parameters such as compression and rotation of the imaged domain.
Deep variational network for rapid 4D flow MRI reconstruction
Apr 20, 2020
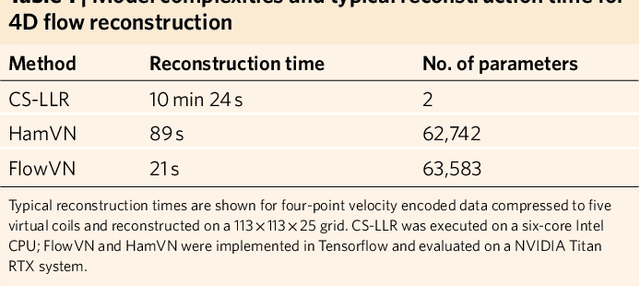
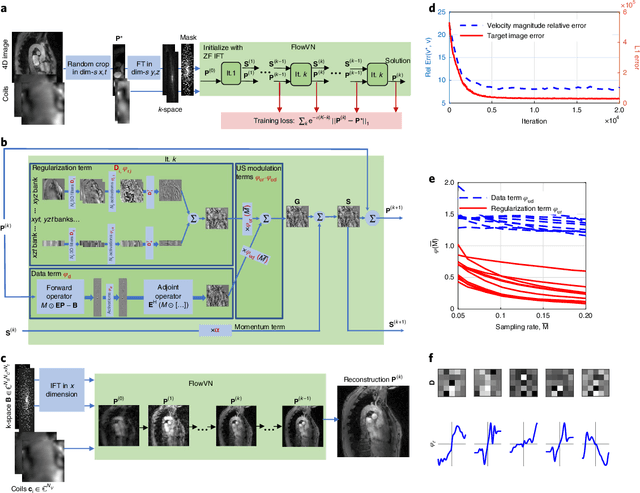
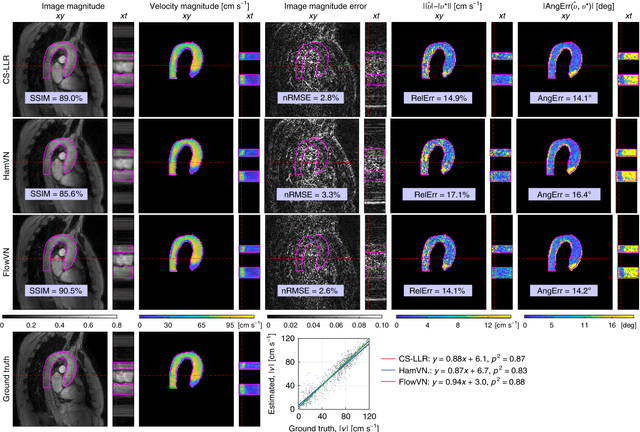
Phase-contrast magnetic resonance imaging (MRI) provides time-resolved quantification of blood flow dynamics that can aid clinical diagnosis. Long in vivo scan times due to repeated three-dimensional (3D) volume sampling over cardiac phases and breathing cycles necessitate accelerated imaging techniques that leverage data correlations. Standard compressed sensing reconstruction methods require tuning of hyperparameters and are computationally expensive, which diminishes the potential reduction of examination times. We propose an efficient model-based deep neural reconstruction network and evaluate its performance on clinical aortic flow data. The network is shown to reconstruct undersampled 4D flow MRI data in under a minute on standard consumer hardware. Remarkably, the relatively low amounts of tunable parameters allowed the network to be trained on images from 11 reference scans while generalizing well to retrospective and prospective undersampled data for various acceleration factors and anatomies.
* 15 pages, 6 figures
Deep Variational Networks with Exponential Weighting for Learning Computed Tomography
Jun 13, 2019


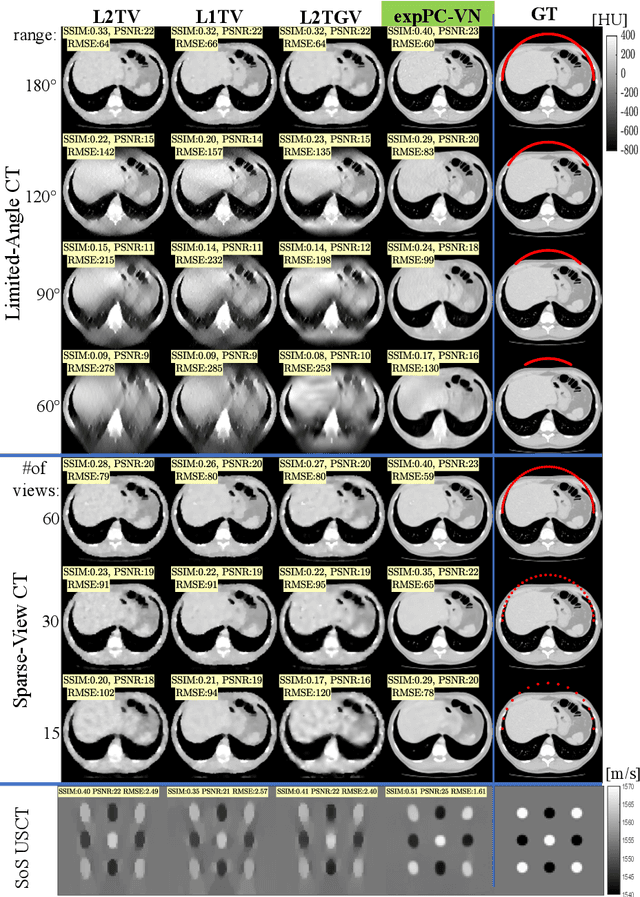
Tomographic image reconstruction is relevant for many medical imaging modalities including X-ray, ultrasound (US) computed tomography (CT) and photoacoustics, for which the access to full angular range tomographic projections might be not available in clinical practice due to physical or time constraints. Reconstruction from incomplete data in low signal-to-noise ratio regime is a challenging and ill-posed inverse problem that usually leads to unsatisfactory image quality. While informative image priors may be learned using generic deep neural network architectures, the artefacts caused by an ill-conditioned design matrix often have global spatial support and cannot be efficiently filtered out by means of convolutions. In this paper we propose to learn an inverse mapping in an end-to-end fashion via unrolling optimization iterations of a prototypical reconstruction algorithm. We herein introduce a network architecture that performs filtering jointly in both sinogram and spatial domains. To efficiently train such deep network we propose a novel regularization approach based on deep exponential weighting. Experiments on US and X-ray CT data show that our proposed method is qualitatively and quantitatively superior to conventional non-linear reconstruction methods as well as state-of-the-art deep networks for image reconstruction. Fast inference time of the proposed algorithm allows for sophisticated reconstructions in real-time critical settings, demonstrated with US SoS imaging of an ex vivo bovine phantom.
Implicit Modeling with Uncertainty Estimation for Intravoxel Incoherent Motion Imaging
Oct 22, 2018

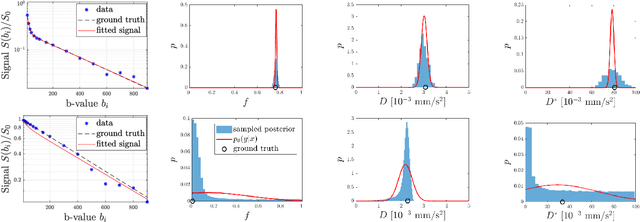

Intravoxel incoherent motion (IVIM) imaging allows contrast-agent free in vivo perfusion quantification with magnetic resonance imaging (MRI). However, its use is limited by typically low accuracy due to low signal-to-noise ratio (SNR) at large gradient encoding magnitudes as well as dephasing artefacts caused by subject motion, which is particularly challenging in fetal MRI. To mitigate this problem, we propose an implicit IVIM signal acquisition model with which we learn full posterior distribution of perfusion parameters using artificial neural networks. This posterior then encapsulates the uncertainty of the inferred parameter estimates, which we validate herein via numerical experiments with rejection-based Bayesian sampling. Compared to state-of-the-art IVIM estimation method of segmented least-squares fitting, our proposed approach improves parameter estimation accuracy by 65% on synthetic anisotropic perfusion data. On paired rescans of in vivo fetal MRI, our method increases repeatability of parameter estimation in placenta by 46%.
Image Reconstruction via Variational Network for Real-Time Hand-Held Sound-Speed Imaging
Jul 19, 2018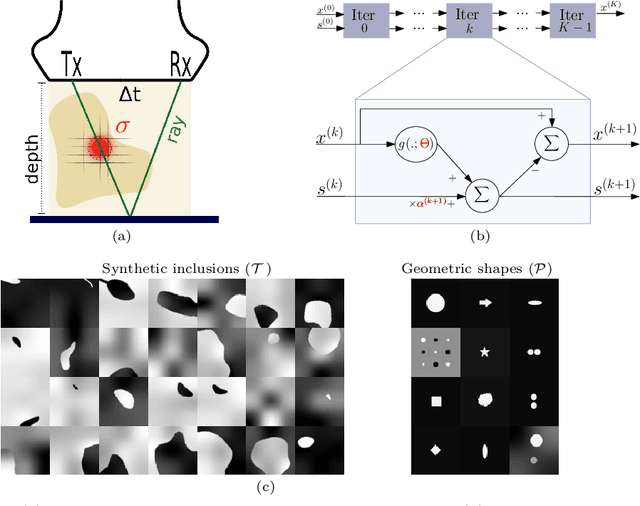

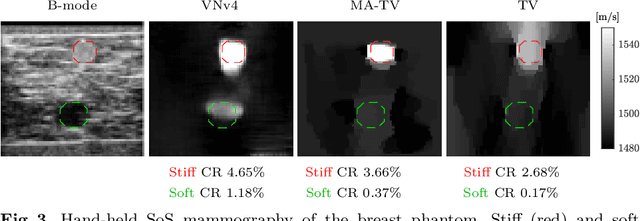
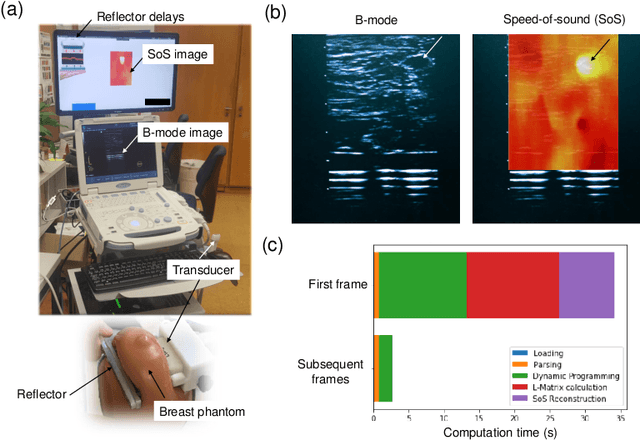
Speed-of-sound is a biomechanical property for quantitative tissue differentiation, with great potential as a new ultrasound-based image modality. A conventional ultrasound array transducer can be used together with an acoustic mirror, or so-called reflector, to reconstruct sound-speed images from time-of-flight measurements to the reflector collected between transducer element pairs, which constitutes a challenging problem of limited-angle computed tomography. For this problem, we herein present a variational network based image reconstruction architecture that is based on optimization loop unrolling, and provide an efficient training protocol of this network architecture on fully synthetic inclusion data. Our results indicate that the learned model presents good generalization ability, being able to reconstruct images with significantly different statistics compared to the training set. Complex inclusion geometries were shown to be successfully reconstructed, also improving over the prior-art by 23% in reconstruction error and by 10% in contrast on synthetic data. In a phantom study, we demonstrated the detection of multiple inclusions that were not distinguishable by prior-art reconstruction, meanwhile improving the contrast by 27% for a stiff inclusion and by 219% for a soft inclusion. Our reconstruction algorithm takes approximately 10ms, enabling its use as a real-time imaging method on an ultrasound machine, for which we are demonstrating an example preliminary setup herein.