 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Imaging Model of Speed-of-Sound Reconstruction via a Convolutional Formulation
Sep 01, 2023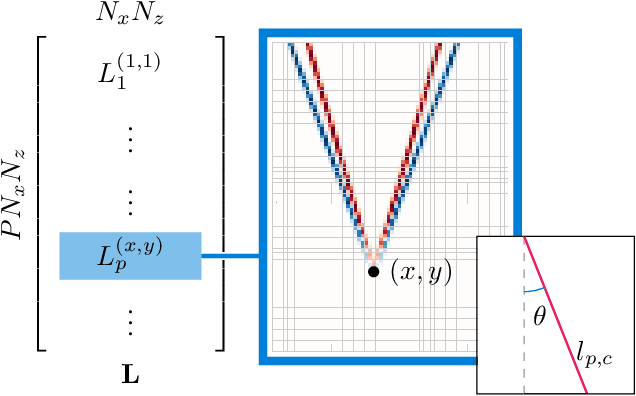
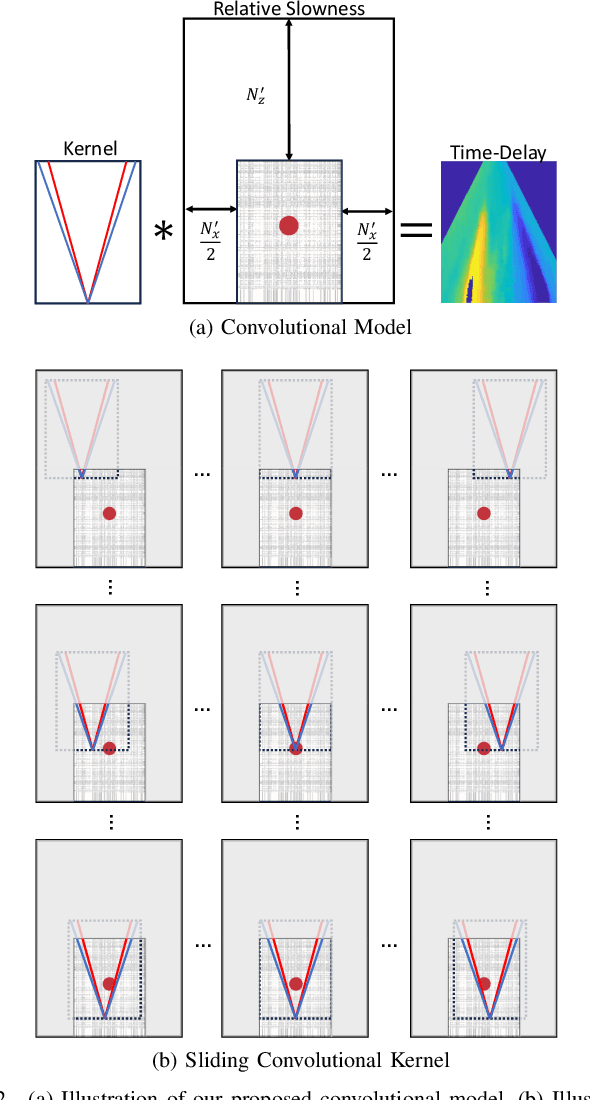
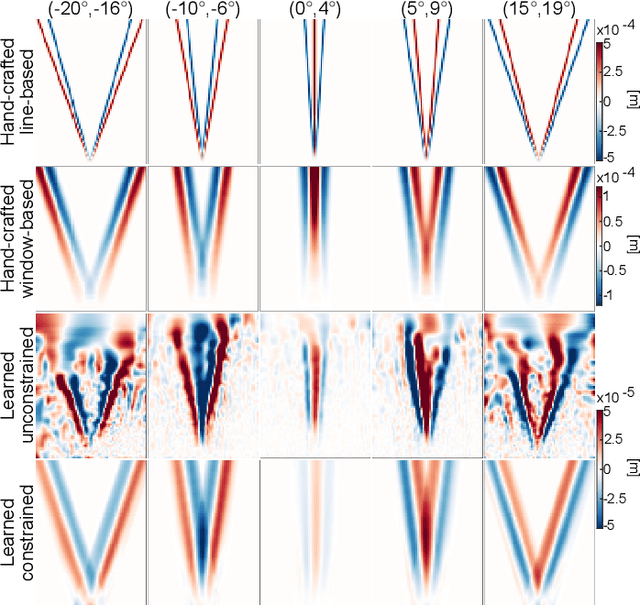
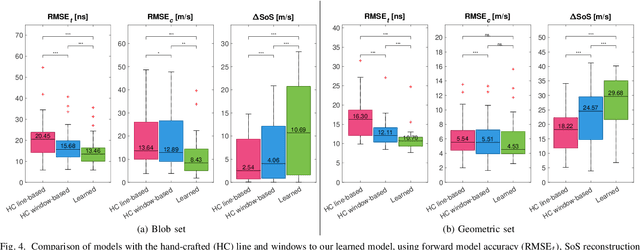
Speed-of-sound (SoS) is an emerging ultrasound contrast modality, where pulse-echo techniques using conventional transducers offer multiple benefits. For estimating tissue SoS distributions, spatial domain reconstruction from relative speckle shifts between different beamforming sequences is a promising approach. This operates based on a forward model that relates the sought local values of SoS to observed speckle shifts, for which the associated image reconstruction inverse problem is solved. The reconstruction accuracy thus highly depends on the hand-crafted forward imaging model. In this work, we propose to learn the SoS imaging model based on data. We introduce a convolutional formulation of the pulse-echo SoS imaging problem such that the entire field-of-view requires a single unified kernel, the learning of which is then tractable and robust. We present least-squares estimation of such convolutional kernel, which can further be constrained and regularized for numerical stability. In experiments, we show that a forward model learned from k-Wave simulations improves the median contrast of SoS reconstructions by 63%, compared to a conventional hand-crafted line-based wave-path model. This simulation-learned model generalizes successfully to acquired phantom data, nearly doubling the SoS contrast compared to the conventional hand-crafted alternative. We demonstrate equipment-specific and small-data regime feasibility by learning a forward model from a single phantom image, where our learned model quadruples the SoS contrast compared to the conventional hand-crafted model. On in-vivo data, the simulation- and phantom-learned models respectively exhibit impressive 7 and 10 folds contrast improvements over the conventional model.
Robust Imaging of Speed-of-Sound Using Virtual Source Transmission
Mar 20, 2023Speed-of-sound (SoS) is a novel imaging biomarker for assessing biomechanical characteristics of soft tissues. SoS imaging in pulse-echo mode using conventional ultrasound systems with hand-held transducers has the potential to enable new clinical uses. Recent work demonstrated diverging waves from single-element (SE) transmits to outperform plane-wave sequences. However, single-element transmits have severely limited power and hence produce low signal-to-noise ratio (SNR) in echo data. We herein propose Walsh-Hadamard (WH) coded and virtual-source (VS) transmit sequences for improved SNR in SoS imaging. We additionally present an iterative method of estimating beamforming SoS in the medium, which otherwise confound SoS reconstructions due to beamforming inaccuracies in the images used for reconstruction. Through numerical simulations, phantom experiments, and in-vivo imaging data, we show that WH is not robust against motion, which is often unavoidable in clinical imaging scenarios. Our proposed virtual-source sequence is shown to provide the highest SoS reconstruction performance, especially robust to motion artifacts. In phantom experiments, despite having a comparable SoS root-mean-square-error (RMSE) of 17.5 to 18.0 m/s at rest, with a minor axial probe motion of ~0.67 mm/s the RMSE for SE, WH, and VS already deteriorate to 20.2, 105.4, 19.0 m/s, respectively; showing that WH produces unacceptable results, not robust to motion. In the clinical data, the high SNR and motion-resilience of VS sequence is seen to yield superior contrast compared to SE and WH sequences.
Training Variational Networks with Multi-Domain Simulations: Speed-of-Sound Image Reconstruction
Jun 25, 2020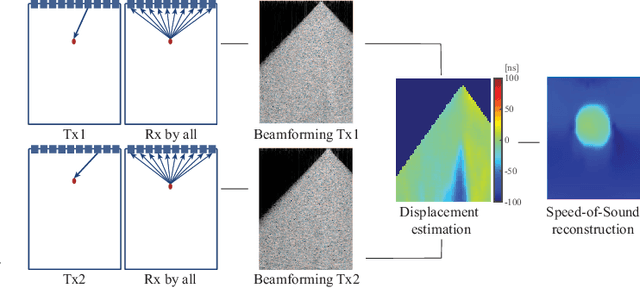
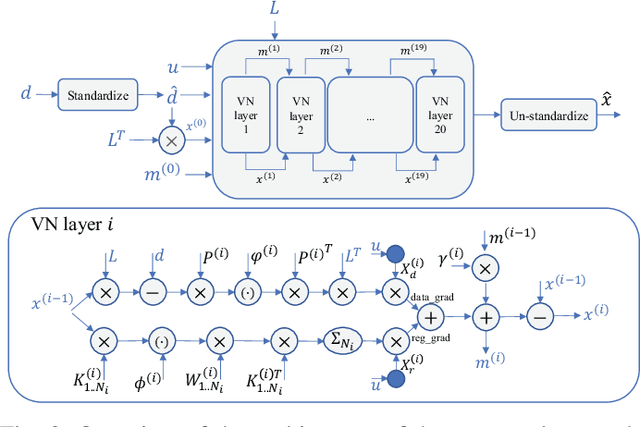
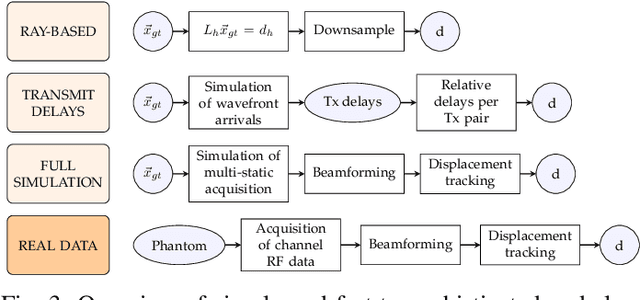

Speed-of-sound has been shown as a potential biomarker for breast cancer imaging, successfully differentiating malignant tumors from benign ones. Speed-of-sound images can be reconstructed from time-of-flight measurements from ultrasound images acquired using conventional handheld ultrasound transducers. Variational Networks (VN) have recently been shown to be a potential learning-based approach for optimizing inverse problems in image reconstruction. Despite earlier promising results, these methods however do not generalize well from simulated to acquired data, due to the domain shift. In this work, we present for the first time a VN solution for a pulse-echo SoS image reconstruction problem using diverging waves with conventional transducers and single-sided tissue access. This is made possible by incorporating simulations with varying complexity into training. We use loop unrolling of gradient descent with momentum, with an exponentially weighted loss of outputs at each unrolled iteration in order to regularize training. We learn norms as activation functions regularized to have smooth forms for robustness to input distribution variations. We evaluate reconstruction quality on ray-based and full-wave simulations as well as on tissue-mimicking phantom data, in comparison to a classical iterative (L-BFGS) optimization of this image reconstruction problem. We show that the proposed regularization techniques combined with multi-source domain training yield substantial improvements in the domain adaptation capabilities of VN, reducing median RMSE by 54% on a wave-based simulation dataset compared to the baseline VN. We also show that on data acquired from a tissue-mimicking breast phantom the proposed VN provides improved reconstruction in 12 milliseconds.
Deep Variational Networks with Exponential Weighting for Learning Computed Tomography
Jun 13, 2019


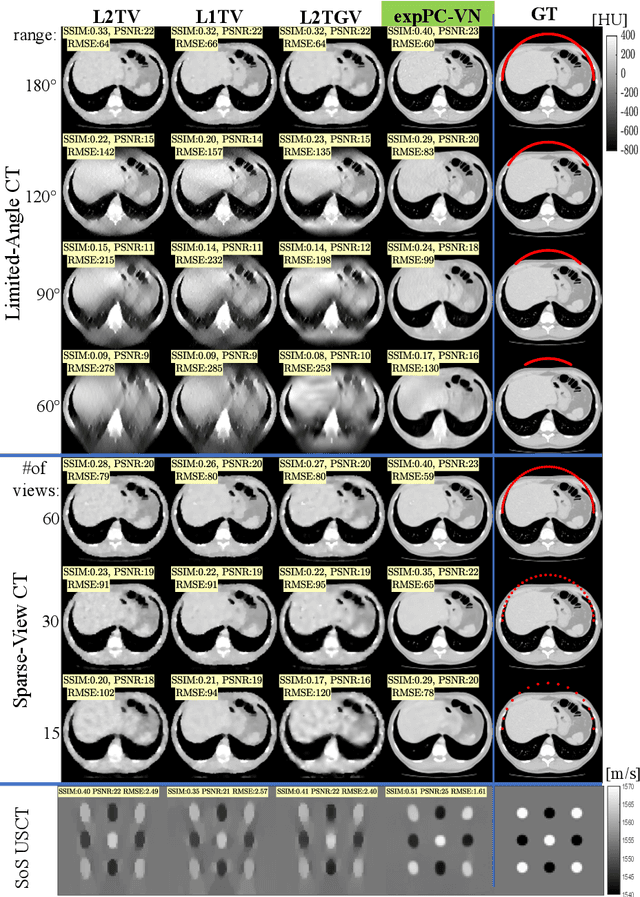
Tomographic image reconstruction is relevant for many medical imaging modalities including X-ray, ultrasound (US) computed tomography (CT) and photoacoustics, for which the access to full angular range tomographic projections might be not available in clinical practice due to physical or time constraints. Reconstruction from incomplete data in low signal-to-noise ratio regime is a challenging and ill-posed inverse problem that usually leads to unsatisfactory image quality. While informative image priors may be learned using generic deep neural network architectures, the artefacts caused by an ill-conditioned design matrix often have global spatial support and cannot be efficiently filtered out by means of convolutions. In this paper we propose to learn an inverse mapping in an end-to-end fashion via unrolling optimization iterations of a prototypical reconstruction algorithm. We herein introduce a network architecture that performs filtering jointly in both sinogram and spatial domains. To efficiently train such deep network we propose a novel regularization approach based on deep exponential weighting. Experiments on US and X-ray CT data show that our proposed method is qualitatively and quantitatively superior to conventional non-linear reconstruction methods as well as state-of-the-art deep networks for image reconstruction. Fast inference time of the proposed algorithm allows for sophisticated reconstructions in real-time critical settings, demonstrated with US SoS imaging of an ex vivo bovine phantom.