 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenOiS: Dual-Domain Denoising of Observation and Solution in Ultrasound Image Reconstruction
Apr 02, 2026Medical imaging aims to recover underlying tissue properties, using inexact (simplified/linearized) imaging models and often from inaccurate and incomplete measurements. Analytical reconstruction methods rely on hand-crafted regularization, sensitive to noise assumptions and parameter tuning. Among deep learning alternatives, plug-and-play (PnP) approaches learn regularization while incorporating imaging physics during inference, outperforming purely data-driven methods. The performance of all these approaches, however, still strongly depends on measurement quality and imaging model accuracy. In this work, we propose DenOiS, a framework that denoises both input observations and resulting solution in their respective domains. It consists of an observation refinement strategy that corrects degraded measurements while compensating for imaging model simplifications, and a diffusion-based PnP reconstruction approach that remains robust under missing measurements. DenOiS enables generalization to real data from training only in simulations, resulting in high-fidelity image reconstruction with noisy observations and inexact imaging models. We demonstrate this for speed-of-sound imaging as a challenging setting of quantitative ultrasound image reconstruction.
Uncertainty Estimation for Trust Attribution to Speed-of-Sound Reconstruction with Variational Networks
Apr 15, 2025Speed-of-sound (SoS) is a biomechanical characteristic of tissue, and its imaging can provide a promising biomarker for diagnosis. Reconstructing SoS images from ultrasound acquisitions can be cast as a limited-angle computed-tomography problem, with Variational Networks being a promising model-based deep learning solution. Some acquired data frames may, however, get corrupted by noise due to, e.g., motion, lack of contact, and acoustic shadows, which in turn negatively affects the resulting SoS reconstructions. We propose to use the uncertainty in SoS reconstructions to attribute trust to each individual acquired frame. Given multiple acquisitions, we then use an uncertainty based automatic selection among these retrospectively, to improve diagnostic decisions. We investigate uncertainty estimation based on Monte Carlo Dropout and Bayesian Variational Inference. We assess our automatic frame selection method for differential diagnosis of breast cancer, distinguishing between benign fibroadenoma and malignant carcinoma. We evaluate 21 lesions classified as BI-RADS~4, which represents suspicious cases for probable malignancy. The most trustworthy frame among four acquisitions of each lesion was identified using uncertainty based criteria. Selecting a frame informed by uncertainty achieved an area under curve of 76% and 80% for Monte Carlo Dropout and Bayesian Variational Inference, respectively, superior to any uncertainty-uninformed baselines with the best one achieving 64%. A novel use of uncertainty estimation is proposed for selecting one of multiple data acquisitions for further processing and decision making.
FGGP: Fixed-Rate Gradient-First Gradual Pruning
Nov 08, 2024In recent years, the increasing size of deep learning models and their growing demand for computational resources have drawn significant attention to the practice of pruning neural networks, while aiming to preserve their accuracy. In unstructured gradual pruning, which sparsifies a network by gradually removing individual network parameters until a targeted network sparsity is reached, recent works show that both gradient and weight magnitudes should be considered. In this work, we show that such mechanism, e.g., the order of prioritization and selection criteria, is essential. We introduce a gradient-first magnitude-next strategy for choosing the parameters to prune, and show that a fixed-rate subselection criterion between these steps works better, in contrast to the annealing approach in the literature. We validate this on CIFAR-10 dataset, with multiple randomized initializations on both VGG-19 and ResNet-50 network backbones, for pruning targets of 90, 95, and 98% sparsity and for both initially dense and 50% sparse networks. Our proposed fixed-rate gradient-first gradual pruning (FGGP) approach outperforms its state-of-the-art alternatives in most of the above experimental settings, even occasionally surpassing the upperbound of corresponding dense network results, and having the highest ranking across the considered experimental settings.
Learning the Imaging Model of Speed-of-Sound Reconstruction via a Convolutional Formulation
Sep 01, 2023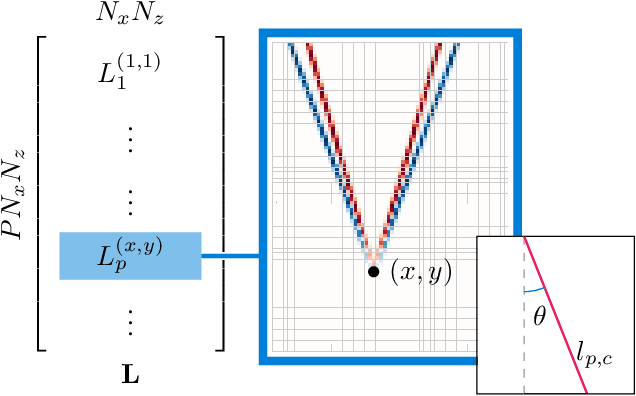
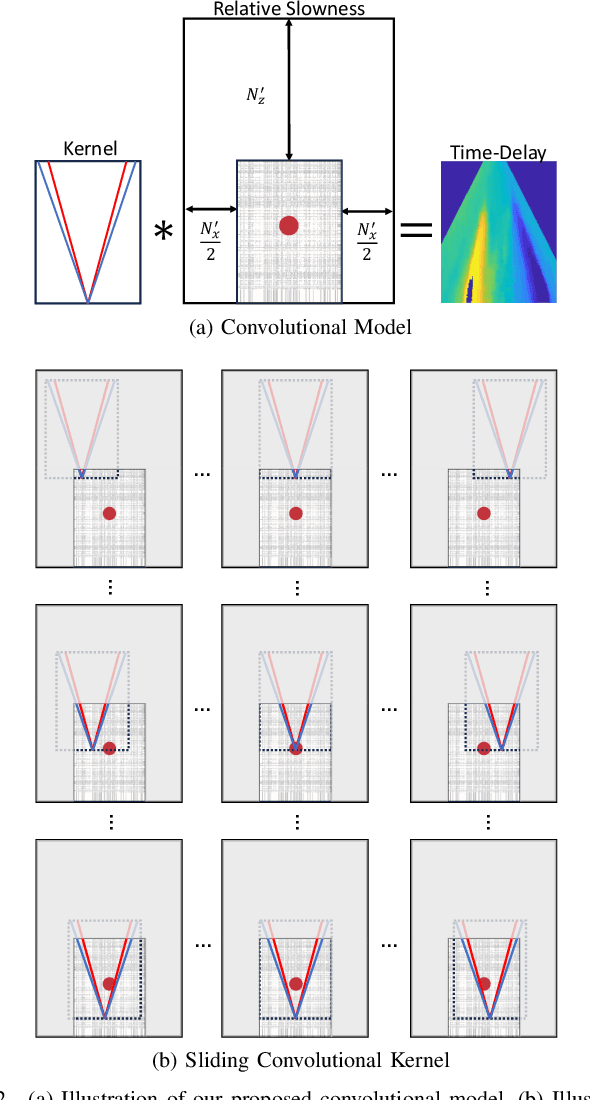
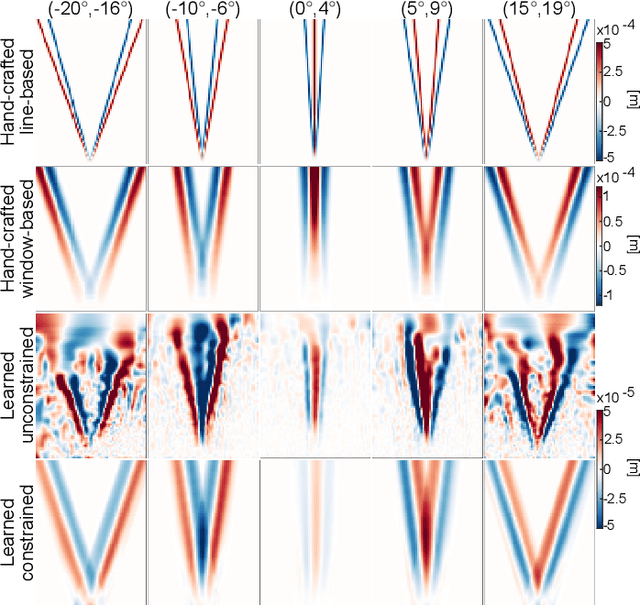
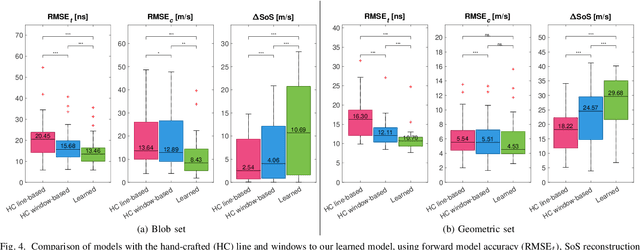
Speed-of-sound (SoS) is an emerging ultrasound contrast modality, where pulse-echo techniques using conventional transducers offer multiple benefits. For estimating tissue SoS distributions, spatial domain reconstruction from relative speckle shifts between different beamforming sequences is a promising approach. This operates based on a forward model that relates the sought local values of SoS to observed speckle shifts, for which the associated image reconstruction inverse problem is solved. The reconstruction accuracy thus highly depends on the hand-crafted forward imaging model. In this work, we propose to learn the SoS imaging model based on data. We introduce a convolutional formulation of the pulse-echo SoS imaging problem such that the entire field-of-view requires a single unified kernel, the learning of which is then tractable and robust. We present least-squares estimation of such convolutional kernel, which can further be constrained and regularized for numerical stability. In experiments, we show that a forward model learned from k-Wave simulations improves the median contrast of SoS reconstructions by 63%, compared to a conventional hand-crafted line-based wave-path model. This simulation-learned model generalizes successfully to acquired phantom data, nearly doubling the SoS contrast compared to the conventional hand-crafted alternative. We demonstrate equipment-specific and small-data regime feasibility by learning a forward model from a single phantom image, where our learned model quadruples the SoS contrast compared to the conventional hand-crafted model. On in-vivo data, the simulation- and phantom-learned models respectively exhibit impressive 7 and 10 folds contrast improvements over the conventional model.
Robust Imaging of Speed-of-Sound Using Virtual Source Transmission
Mar 20, 2023Speed-of-sound (SoS) is a novel imaging biomarker for assessing biomechanical characteristics of soft tissues. SoS imaging in pulse-echo mode using conventional ultrasound systems with hand-held transducers has the potential to enable new clinical uses. Recent work demonstrated diverging waves from single-element (SE) transmits to outperform plane-wave sequences. However, single-element transmits have severely limited power and hence produce low signal-to-noise ratio (SNR) in echo data. We herein propose Walsh-Hadamard (WH) coded and virtual-source (VS) transmit sequences for improved SNR in SoS imaging. We additionally present an iterative method of estimating beamforming SoS in the medium, which otherwise confound SoS reconstructions due to beamforming inaccuracies in the images used for reconstruction. Through numerical simulations, phantom experiments, and in-vivo imaging data, we show that WH is not robust against motion, which is often unavoidable in clinical imaging scenarios. Our proposed virtual-source sequence is shown to provide the highest SoS reconstruction performance, especially robust to motion artifacts. In phantom experiments, despite having a comparable SoS root-mean-square-error (RMSE) of 17.5 to 18.0 m/s at rest, with a minor axial probe motion of ~0.67 mm/s the RMSE for SE, WH, and VS already deteriorate to 20.2, 105.4, 19.0 m/s, respectively; showing that WH produces unacceptable results, not robust to motion. In the clinical data, the high SNR and motion-resilience of VS sequence is seen to yield superior contrast compared to SE and WH sequences.
Analytical Estimation of Beamforming Speed-of-Sound Using Transmission Geometry
Nov 21, 2022Most ultrasound imaging techniques necessitate the fundamental step of converting temporal signals received from transducer elements into a spatial echogenecity map. This beamforming (BF) step requires the knowledge of speed-of-sound (SoS) value in the imaged medium. An incorrect assumption of BF SoS leads to aberration artifacts, not only deteriorating the quality and resolution of conventional brightness mode (B-mode) images, hence limiting their clinical usability, but also impairing other ultrasound modalities such as elastography and spatial SoS reconstructions, which rely on faithfully beamformed images as their input. In this work, we propose an analytical method for estimating BF SoS. We show that pixel-wise relative shifts between frames beamformed with an assumed SoS is a function of geometric disparities of the transmission paths and the error in such SoS assumption. Using this relation, we devise an analytical model, the closed form solution of which yields the difference between the assumed and the true SoS in the medium. Based on this, we correct the BF SoS, which can also be applied iteratively. Both in simulations and experiments, lateral B-mode resolution is shown to be improved by $\approx$25% compared to that with an initial SoS assumption error of 3.3% (50 m/s), while localization artifacts from beamforming are also corrected. After 5 iterations, our method achieves BF SoS errors of under 0.6 m/s in simulations and under 1 m/s in experimental phantom data. Residual time-delay errors in beamforming 32 numerical phantoms are shown to reduce down to 0.07 $\mu$s, with average improvements of up to 21 folds compared to initial inaccurate assumptions. We additionally show the utility of the proposed method in imaging local SoS maps, where using our correction method reduces reconstruction root-mean-square errors substantially, down to their lower-bound with actual BF SoS.
Global Speed-of-Sound Prediction Using Transmission Geometry
Aug 17, 2022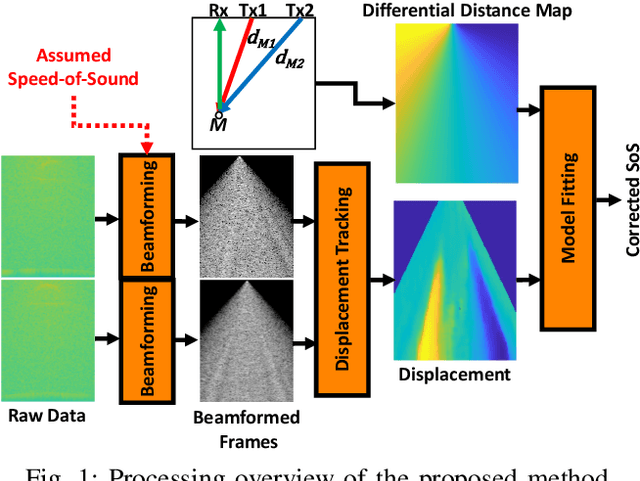
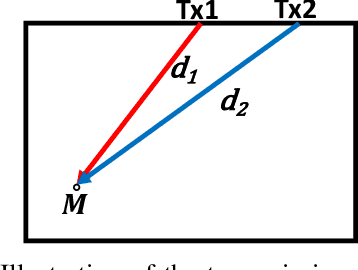
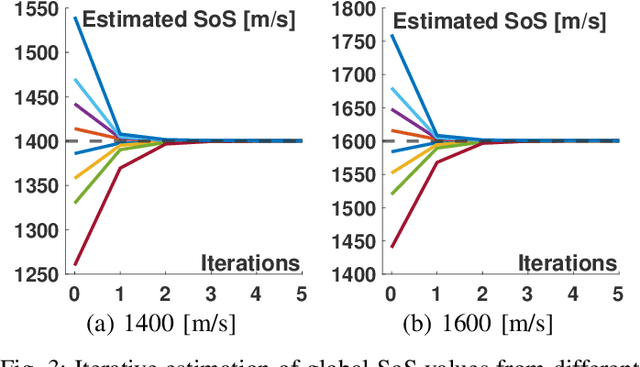
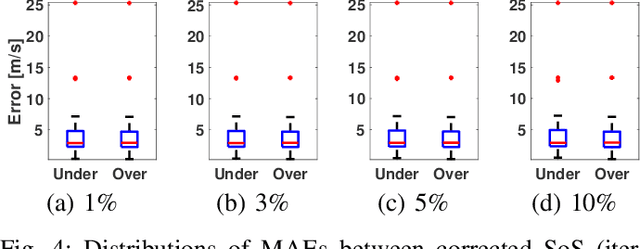
Most ultrasound (US) imaging techniques use spatially-constant speed-of-sound (SoS) values for beamforming. Having a discrepancy between the actual and used SoS value leads to aberration artifacts, e.g., reducing the image resolution, which may affect diagnostic usability. Accuracy and quality of different US imaging modalities, such as tomographic reconstruction of local SoS maps, also depend on a good initial beamforming SoS. In this work, we develop an analytical method for estimating mean SoS in an imaged medium. We show that the relative shifts between beamformed frames depend on the SoS offset and the geometric disparities in transmission paths. Using this relation, we estimate a correction factor and hence a corrected mean SoS in the medium. We evaluated our proposed method on a set of numerical simulations, demonstrating its utility both for global SoS prediction and for local SoS tomographic reconstruction. For our evaluation dataset, for an initial SoS under- and over-assumption of 5% the medium SoS, our method is able to predict the actual mean SoS within 0.3% accuracy. For the tomographic reconstruction of local SoS maps, the reconstruction accuracy is improved on average by 78.5% and 87%, respectively, compared to an initial SoS under- and over-assumption of 5%.