 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressive Power and Limitations of Multi-Layer SSMs
Apr 16, 2026We study the expressive power and limitations of multi-layer state-space models (SSMs). First, we show that multi-layer SSMs face fundamental limitations in compositional tasks, revealing an inherent gap between SSMs and streaming models. Then, we examine the role of chain-of-thought (CoT), showing that offline CoT does not fundamentally increase the expressiveness, while online CoT can substantially increase its power. Indeed, with online CoT, multi-layer SSMs become equivalent in power to streaming algorithms. Finally, we investigate the tradeoff between width and precision, showing that these resources are not interchangeable in the base model, but admit a clean equivalence once online CoT is allowed. Overall, our results offer a unified perspective on how depth, finite precision, and CoT shape the power and limits of SSMs.
Maximizing Asynchronicity in Event-based Neural Networks
May 16, 2025Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
Regularity and Stability Properties of Selective SSMs with Discontinuous Gating
May 16, 2025Deep Selective State-Space Models (SSMs), characterized by input-dependent, time-varying parameters, offer significant expressive power but pose challenges for stability analysis, especially with discontinuous gating signals. In this paper, we investigate the stability and regularity properties of continuous-time selective SSMs through the lens of passivity and Input-to-State Stability (ISS). We establish that intrinsic energy dissipation guarantees exponential forgetting of past states. Crucially, we prove that the unforced system dynamics possess an underlying minimal quadratic energy function whose defining matrix exhibits robust $\text{AUC}_{\text{loc}}$ regularity, accommodating discontinuous gating. Furthermore, assuming a universal quadratic storage function ensures passivity across all inputs, we derive parametric LMI conditions and kernel constraints that limit gating mechanisms, formalizing "irreversible forgetting" of recurrent models. Finally, we provide sufficient conditions for global ISS, linking uniform local dissipativity to overall system robustness. Our findings offer a rigorous framework for understanding and designing stable and reliable deep selective SSMs.
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
Apr 14, 2025With their motion-responsive nature, event-based cameras offer significant advantages over traditional cameras for optical flow estimation. While deep learning has improved upon traditional methods, current neural networks adopted for event-based optical flow still face temporal and spatial reasoning limitations. We propose Perturbed State Space Feature Encoders (P-SSE) for multi-frame optical flow with event cameras to address these challenges. P-SSE adaptively processes spatiotemporal features with a large receptive field akin to Transformer-based methods, while maintaining the linear computational complexity characteristic of SSMs. However, the key innovation that enables the state-of-the-art performance of our model lies in our perturbation technique applied to the state dynamics matrix governing the SSM system. This approach significantly improves the stability and performance of our model. We integrate P-SSE into a framework that leverages bi-directional flows and recurrent connections, expanding the temporal context of flow prediction. Evaluations on DSEC-Flow and MVSEC datasets showcase P-SSE's superiority, with 8.48% and 11.86% improvements in EPE performance, respectively.
* 10 pages, 4 figures, 4 tables. Equal contribution by Gokul Raju Govinda Raju and Nikola Zubi\'c
GG-SSMs: Graph-Generating State Space Models
Dec 17, 2024State Space Models (SSMs) are powerful tools for modeling sequential data in computer vision and time series analysis domains. However, traditional SSMs are limited by fixed, one-dimensional sequential processing, which restricts their ability to model non-local interactions in high-dimensional data. While methods like Mamba and VMamba introduce selective and flexible scanning strategies, they rely on predetermined paths, which fails to efficiently capture complex dependencies. We introduce Graph-Generating State Space Models (GG-SSMs), a novel framework that overcomes these limitations by dynamically constructing graphs based on feature relationships. Using Chazelle's Minimum Spanning Tree algorithm, GG-SSMs adapt to the inherent data structure, enabling robust feature propagation across dynamically generated graphs and efficiently modeling complex dependencies. We validate GG-SSMs on 11 diverse datasets, including event-based eye-tracking, ImageNet classification, optical flow estimation, and six time series datasets. GG-SSMs achieve state-of-the-art performance across all tasks, surpassing existing methods by significant margins. Specifically, GG-SSM attains a top-1 accuracy of 84.9% on ImageNet, outperforming prior SSMs by 1%, reducing the KITTI-15 error rate to 2.77%, and improving eye-tracking detection rates by up to 0.33% with fewer parameters. These results demonstrate that dynamic scanning based on feature relationships significantly improves SSMs' representational power and efficiency, offering a versatile tool for various applications in computer vision and beyond.
S7: Selective and Simplified State Space Layers for Sequence Modeling
Oct 04, 2024A central challenge in sequence modeling is efficiently handling tasks with extended contexts. While recent state-space models (SSMs) have made significant progress in this area, they often lack input-dependent filtering or require substantial increases in model complexity to handle input variability. We address this gap by introducing S7, a simplified yet powerful SSM that can handle input dependence while incorporating stable reparameterization and specific design choices to dynamically adjust state transitions based on input content, maintaining efficiency and performance. We prove that this reparameterization ensures stability in long-sequence modeling by keeping state transitions well-behaved over time. Additionally, it controls the gradient norm, enabling efficient training and preventing issues like exploding or vanishing gradients. S7 significantly outperforms baselines across various sequence modeling tasks, including neuromorphic event-based datasets, Long Range Arena benchmarks, and various physical and biological time series. Overall, S7 offers a more straightforward approach to sequence modeling without relying on complex, domain-specific inductive biases, achieving significant improvements across key benchmarks.
Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory
May 26, 2024



Deep learning models have achieved significant success across various applications but continue to struggle with tasks requiring complex reasoning over sequences, such as function composition and compositional tasks. Despite advancements, models like Structured State Space Models (SSMs) and Transformers underperform in deep compositionality tasks due to inherent architectural and training limitations. Maintaining accuracy over multiple reasoning steps remains a primary challenge, as current models often rely on shortcuts rather than genuine multi-step reasoning, leading to performance degradation as task complexity increases. Existing research highlights these shortcomings but lacks comprehensive theoretical and empirical analysis for SSMs. Our contributions address this gap by providing a theoretical framework based on complexity theory to explain SSMs' limitations. Moreover, we present extensive empirical evidence demonstrating how these limitations impair function composition and algorithmic task performance. Our experiments reveal significant performance drops as task complexity increases, even with Chain-of-Thought (CoT) prompting. Models frequently resort to shortcuts, leading to errors in multi-step reasoning. This underscores the need for innovative solutions beyond current deep learning paradigms to achieve reliable multi-step reasoning and compositional task-solving in practical applications.
State Space Models for Event Cameras
Feb 23, 2024Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.31 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
From Chaos Comes Order: Ordering Event Representations for Object Detection
Apr 27, 2023

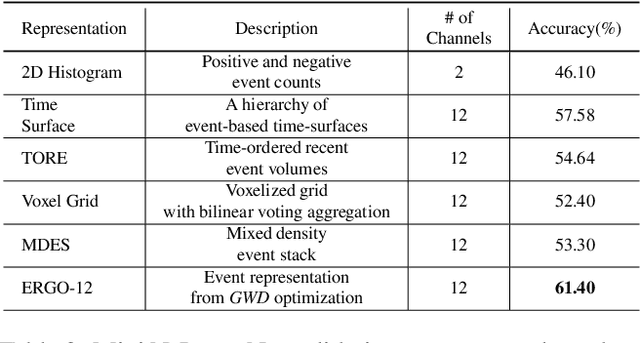

Today, state-of-the-art deep neural networks that process events first convert them into dense, grid-like input representations before using an off-the-shelf network. However, selecting the appropriate representation for the task traditionally requires training a neural network for each representation and selecting the best one based on the validation score, which is very time-consuming. In this work, we eliminate this bottleneck by selecting the best representation based on the Gromov-Wasserstein Discrepancy (GWD) between the raw events and their representation. It is approximately 200 times faster to compute than training a neural network and preserves the task performance ranking of event representations across multiple representations, network backbones, and datasets. This means that finding a representation with a high task score is equivalent to finding a representation with a low GWD. We use this insight to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful representations that exceed the state-of-the-art. On object detection, our optimized representation outperforms existing representations by 1.9% mAP on the 1 Mpx dataset and 8.6% mAP on the Gen1 dataset and even outperforms the state-of-the-art by 1.8% mAP on Gen1 and state-of-the-art feed-forward methods by 6.0% mAP on the 1 Mpx dataset. This work opens a new unexplored field of explicit representation optimization for event-based learning methods.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering
Mar 05, 2021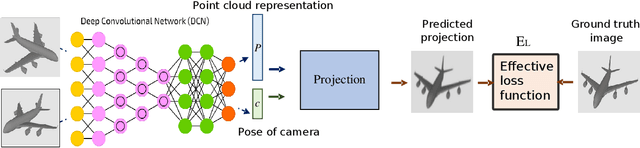
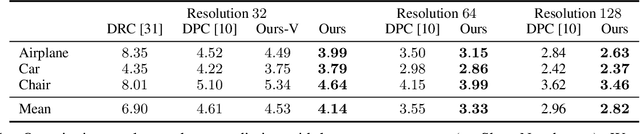


Differentiable rendering is a very successful technique that applies to a Single-View 3D Reconstruction. Current renderers use losses based on pixels between a rendered image of some 3D reconstructed object and ground-truth images from given matched viewpoints to optimise parameters of the 3D shape. These models require a rendering step, along with visibility handling and evaluation of the shading model. The main goal of this paper is to demonstrate that we can avoid these steps and still get reconstruction results as other state-of-the-art models that are equal or even better than existing category-specific reconstruction methods. First, we use the same CNN architecture for the prediction of a point cloud shape and pose prediction like the one used by Insafutdinov \& Dosovitskiy. Secondly, we propose the novel effective loss function that evaluates how well the projections of reconstructed 3D point clouds cover the ground truth object's silhouette. Then we use Poisson Surface Reconstruction to transform the reconstructed point cloud into a 3D mesh. Finally, we perform a GAN-based texture mapping on a particular 3D mesh and produce a textured 3D mesh from a single 2D image. We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.