 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering
Paper and Code
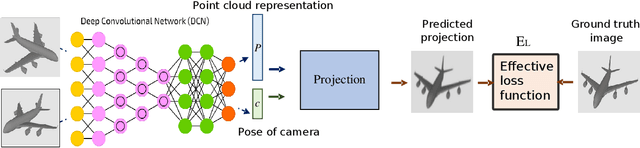
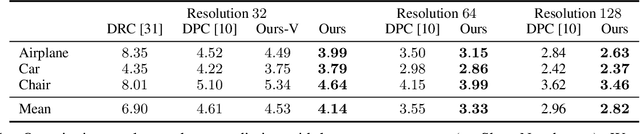


Differentiable rendering is a very successful technique that applies to a Single-View 3D Reconstruction. Current renderers use losses based on pixels between a rendered image of some 3D reconstructed object and ground-truth images from given matched viewpoints to optimise parameters of the 3D shape. These models require a rendering step, along with visibility handling and evaluation of the shading model. The main goal of this paper is to demonstrate that we can avoid these steps and still get reconstruction results as other state-of-the-art models that are equal or even better than existing category-specific reconstruction methods. First, we use the same CNN architecture for the prediction of a point cloud shape and pose prediction like the one used by Insafutdinov \& Dosovitskiy. Secondly, we propose the novel effective loss function that evaluates how well the projections of reconstructed 3D point clouds cover the ground truth object's silhouette. Then we use Poisson Surface Reconstruction to transform the reconstructed point cloud into a 3D mesh. Finally, we perform a GAN-based texture mapping on a particular 3D mesh and produce a textured 3D mesh from a single 2D image. We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.