 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAudio Listens to the Sound of the Graph
Jul 19, 2024
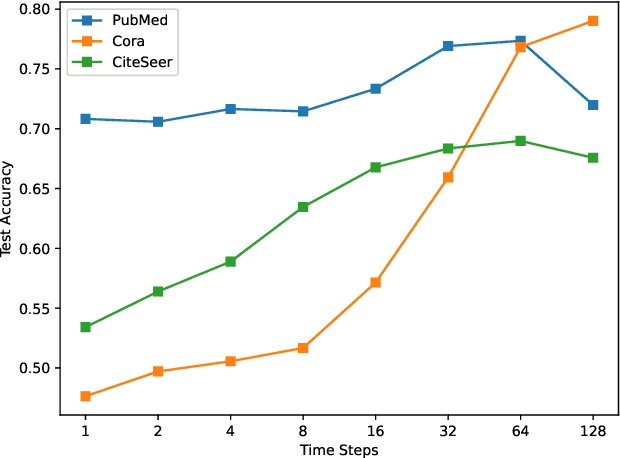
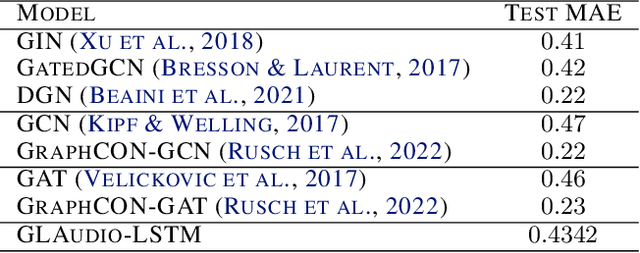

We propose GLAudio: Graph Learning on Audio representation of the node features and the connectivity structure. This novel architecture propagates the node features through the graph network according to the discrete wave equation and then employs a sequence learning architecture to learn the target node function from the audio wave signal. This leads to a new paradigm of learning on graph-structured data, in which information propagation and information processing are separated into two distinct steps. We theoretically characterize the expressivity of our model, introducing the notion of the receptive field of a vertex, and investigate our model's susceptibility to over-smoothing and over-squashing both theoretically as well as experimentally on various graph datasets.
Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory
May 26, 2024



Deep learning models have achieved significant success across various applications but continue to struggle with tasks requiring complex reasoning over sequences, such as function composition and compositional tasks. Despite advancements, models like Structured State Space Models (SSMs) and Transformers underperform in deep compositionality tasks due to inherent architectural and training limitations. Maintaining accuracy over multiple reasoning steps remains a primary challenge, as current models often rely on shortcuts rather than genuine multi-step reasoning, leading to performance degradation as task complexity increases. Existing research highlights these shortcomings but lacks comprehensive theoretical and empirical analysis for SSMs. Our contributions address this gap by providing a theoretical framework based on complexity theory to explain SSMs' limitations. Moreover, we present extensive empirical evidence demonstrating how these limitations impair function composition and algorithmic task performance. Our experiments reveal significant performance drops as task complexity increases, even with Chain-of-Thought (CoT) prompting. Models frequently resort to shortcuts, leading to errors in multi-step reasoning. This underscores the need for innovative solutions beyond current deep learning paradigms to achieve reliable multi-step reasoning and compositional task-solving in practical applications.
Dynablox: Real-time Detection of Diverse Dynamic Objects in Complex Environments
Apr 21, 2023



Real-time detection of moving objects is an essential capability for robots acting autonomously in dynamic environments. We thus propose Dynablox, a novel online mapping-based approach for robust moving object detection in complex environments. The central idea of our approach is to incrementally estimate high confidence free-space areas by modeling and accounting for sensing, state estimation, and mapping limitations during online robot operation. The spatio-temporally conservative free space estimate enables robust detection of moving objects without making any assumptions on the appearance of objects or environments. This allows deployment in complex scenes such as multi-storied buildings or staircases, and for diverse moving objects such as people carrying various items, doors swinging or even balls rolling around. We thoroughly evaluate our approach on real-world data sets, achieving 86% IoU at 17 FPS in typical robotic settings. The method outperforms a recent appearance-based classifier and approaches the performance of offline methods. We demonstrate its generality on a novel data set with rare moving objects in complex environments. We make our efficient implementation and the novel data set available as open-source.