 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAudio Listens to the Sound of the Graph
Paper and Code
Jul 19, 2024
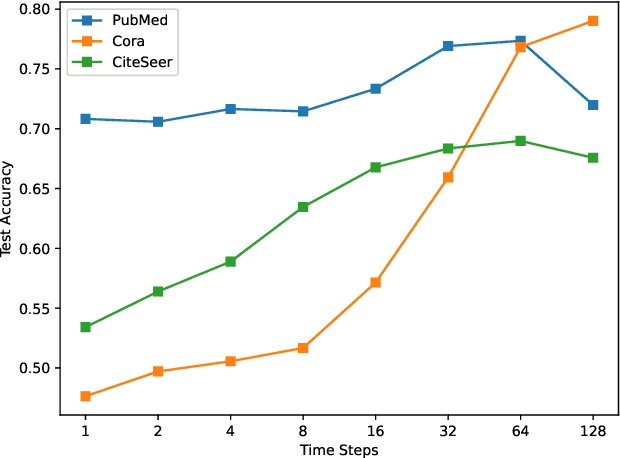
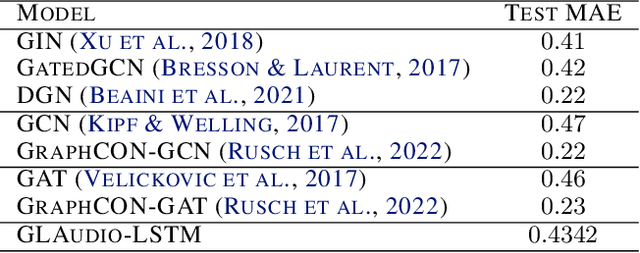

We propose GLAudio: Graph Learning on Audio representation of the node features and the connectivity structure. This novel architecture propagates the node features through the graph network according to the discrete wave equation and then employs a sequence learning architecture to learn the target node function from the audio wave signal. This leads to a new paradigm of learning on graph-structured data, in which information propagation and information processing are separated into two distinct steps. We theoretically characterize the expressivity of our model, introducing the notion of the receptive field of a vertex, and investigate our model's susceptibility to over-smoothing and over-squashing both theoretically as well as experimentally on various graph datasets.