 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Asynchronicity in Event-based Neural Networks
May 16, 2025Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
MSS-DepthNet: Depth Prediction with Multi-Step Spiking Neural Network
Nov 22, 2022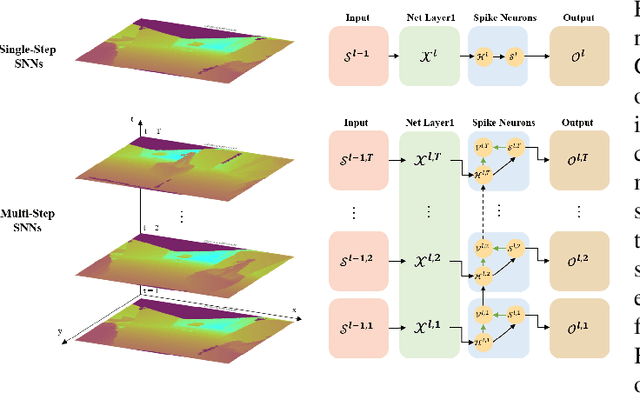

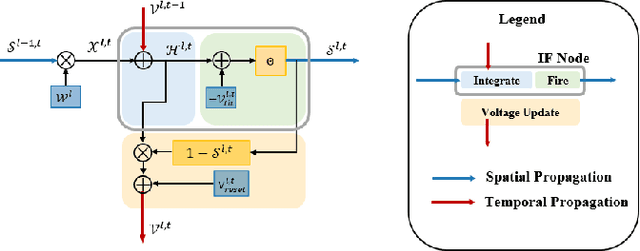
Event cameras are considered to have great potential for computer vision and robotics applications because of their high temporal resolution and low power consumption characteristics. However, the event stream output from event cameras has asynchronous, sparse characteristics that existing computer vision algorithms cannot handle. Spiking neural network is a novel event-based computational paradigm that is considered to be well suited for processing event camera tasks. However, direct training of deep SNNs suffers from degradation problems. This work addresses these problems by proposing a spiking neural network architecture with a novel residual block designed and multi-dimension attention modules combined, focusing on the problem of depth prediction. In addition, a novel event stream representation method is explicitly proposed for SNNs. This model outperforms previous ANN networks of the same size on the MVSEC dataset and shows great computational efficiency.
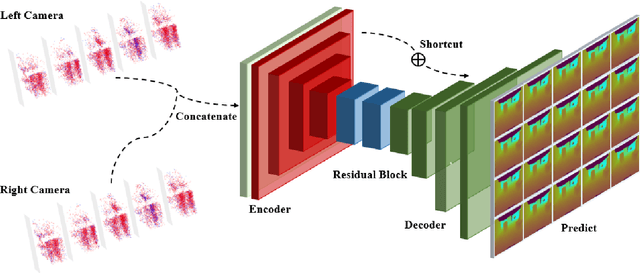
Video Interpolation by Event-driven Anisotropic Adjustment of Optical Flow
Aug 19, 2022
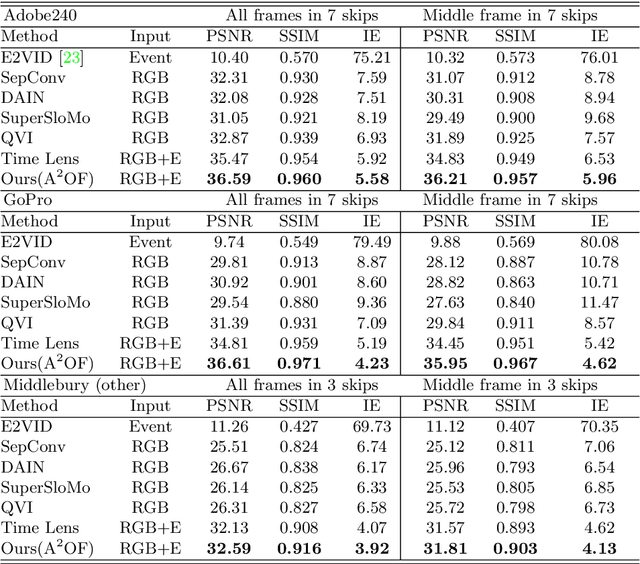
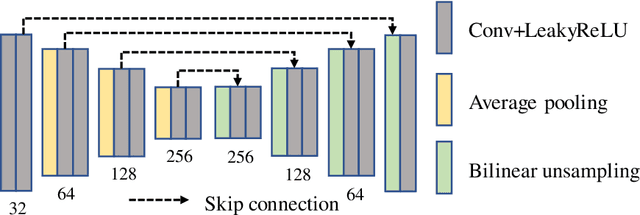
Video frame interpolation is a challenging task due to the ever-changing real-world scene. Previous methods often calculate the bi-directional optical flows and then predict the intermediate optical flows under the linear motion assumptions, leading to isotropic intermediate flow generation. Follow-up research obtained anisotropic adjustment through estimated higher-order motion information with extra frames. Based on the motion assumptions, their methods are hard to model the complicated motion in real scenes. In this paper, we propose an end-to-end training method A^2OF for video frame interpolation with event-driven Anisotropic Adjustment of Optical Flows. Specifically, we use events to generate optical flow distribution masks for the intermediate optical flow, which can model the complicated motion between two frames. Our proposed method outperforms the previous methods in video frame interpolation, taking supervised event-based video interpolation to a higher stage.
TimeReplayer: Unlocking the Potential of Event Cameras for Video Interpolation
Mar 25, 2022

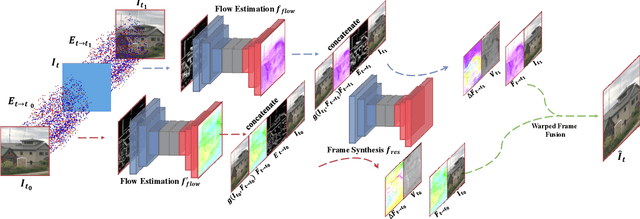
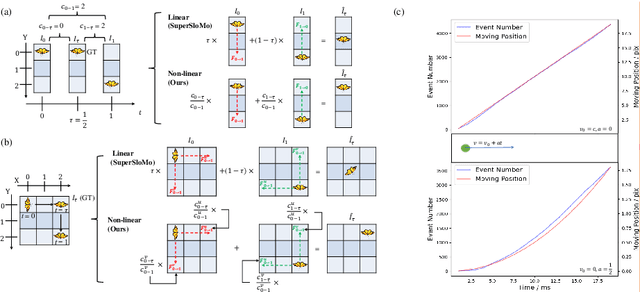
Recording fast motion in a high FPS (frame-per-second) requires expensive high-speed cameras. As an alternative, interpolating low-FPS videos from commodity cameras has attracted significant attention. If only low-FPS videos are available, motion assumptions (linear or quadratic) are necessary to infer intermediate frames, which fail to model complex motions. Event camera, a new camera with pixels producing events of brightness change at the temporal resolution of $\mu s$ $(10^{-6}$ second $)$, is a game-changing device to enable video interpolation at the presence of arbitrarily complex motion. Since event camera is a novel sensor, its potential has not been fulfilled due to the lack of processing algorithms. The pioneering work Time Lens introduced event cameras to video interpolation by designing optical devices to collect a large amount of paired training data of high-speed frames and events, which is too costly to scale. To fully unlock the potential of event cameras, this paper proposes a novel TimeReplayer algorithm to interpolate videos captured by commodity cameras with events. It is trained in an unsupervised cycle-consistent style, canceling the necessity of high-speed training data and bringing the additional ability of video extrapolation. Its state-of-the-art results and demo videos in supplementary reveal the promising future of event-based vision.
Comparing SNNs and RNNs on Neuromorphic Vision Datasets: Similarities and Differences
May 02, 2020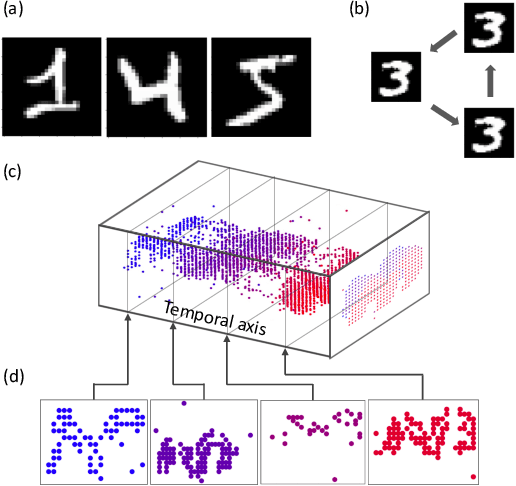
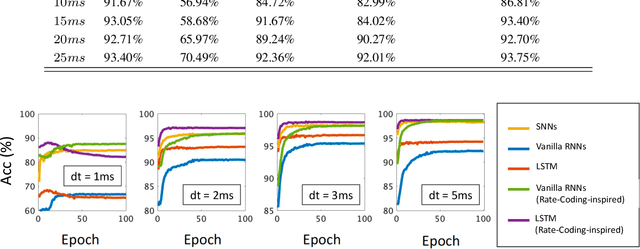
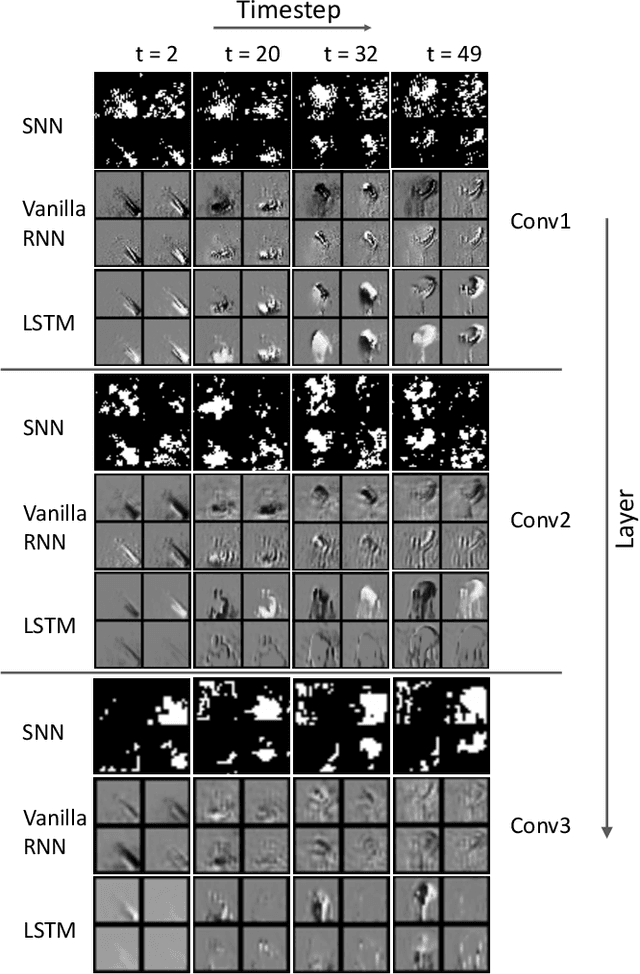
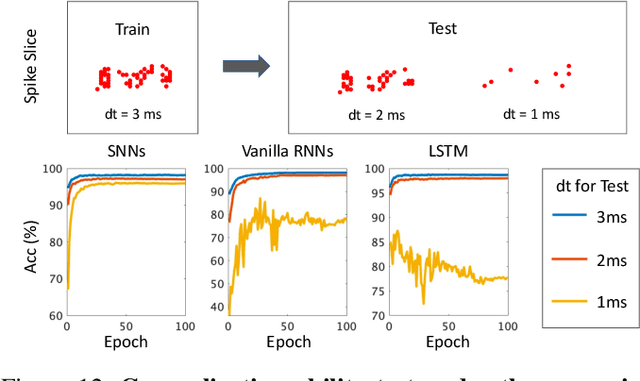
Neuromorphic data, recording frameless spike events, have attracted considerable attention for the spatiotemporal information components and the event-driven processing fashion. Spiking neural networks (SNNs) represent a family of event-driven models with spatiotemporal dynamics for neuromorphic computing, which are widely benchmarked on neuromorphic data. Interestingly, researchers in the machine learning community can argue that recurrent (artificial) neural networks (RNNs) also have the capability to extract spatiotemporal features although they are not event-driven. Thus, the question of "what will happen if we benchmark these two kinds of models together on neuromorphic data" comes out but remains unclear. In this work, we make a systematic study to compare SNNs and RNNs on neuromorphic data, taking the vision datasets as a case study. First, we identify the similarities and differences between SNNs and RNNs (including the vanilla RNNs and LSTM) from the modeling and learning perspectives. To improve comparability and fairness, we unify the supervised learning algorithm based on backpropagation through time (BPTT), the loss function exploiting the outputs at all timesteps, the network structure with stacked fully-connected or convolutional layers, and the hyper-parameters during training. Especially, given the mainstream loss function used in RNNs, we modify it inspired by the rate coding scheme to approach that of SNNs. Furthermore, we tune the temporal resolution of datasets to test model robustness and generalization. At last, a series of contrast experiments are conducted on two types of neuromorphic datasets: DVS-converted (N-MNIST) and DVS-captured (DVS Gesture).