 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing SNNs and RNNs on Neuromorphic Vision Datasets: Similarities and Differences
Paper and Code
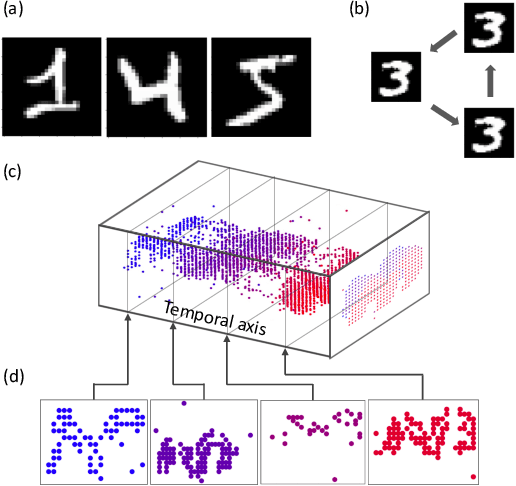
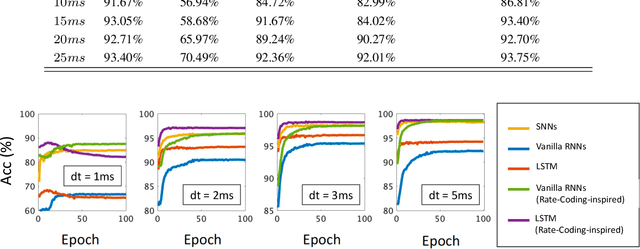
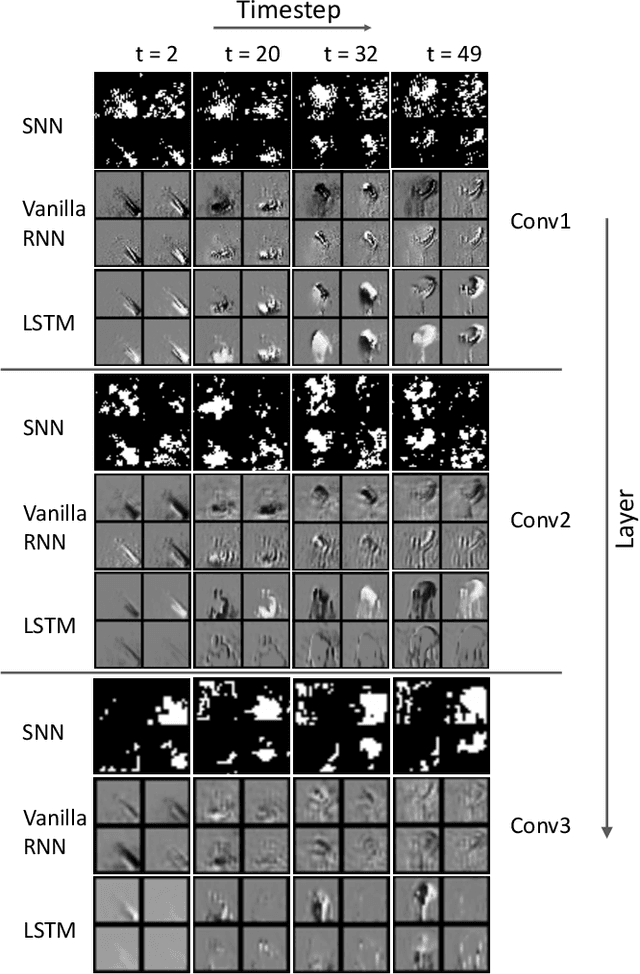
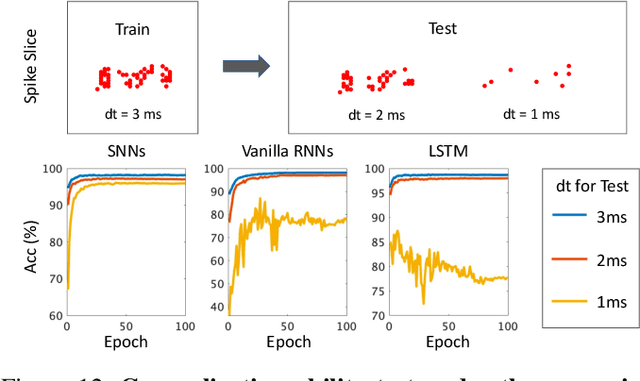
Neuromorphic data, recording frameless spike events, have attracted considerable attention for the spatiotemporal information components and the event-driven processing fashion. Spiking neural networks (SNNs) represent a family of event-driven models with spatiotemporal dynamics for neuromorphic computing, which are widely benchmarked on neuromorphic data. Interestingly, researchers in the machine learning community can argue that recurrent (artificial) neural networks (RNNs) also have the capability to extract spatiotemporal features although they are not event-driven. Thus, the question of "what will happen if we benchmark these two kinds of models together on neuromorphic data" comes out but remains unclear. In this work, we make a systematic study to compare SNNs and RNNs on neuromorphic data, taking the vision datasets as a case study. First, we identify the similarities and differences between SNNs and RNNs (including the vanilla RNNs and LSTM) from the modeling and learning perspectives. To improve comparability and fairness, we unify the supervised learning algorithm based on backpropagation through time (BPTT), the loss function exploiting the outputs at all timesteps, the network structure with stacked fully-connected or convolutional layers, and the hyper-parameters during training. Especially, given the mainstream loss function used in RNNs, we modify it inspired by the rate coding scheme to approach that of SNNs. Furthermore, we tune the temporal resolution of datasets to test model robustness and generalization. At last, a series of contrast experiments are conducted on two types of neuromorphic datasets: DVS-converted (N-MNIST) and DVS-captured (DVS Gesture).