 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-MPPI: Perception-Aware Model Predictive Path Integral Control for Quadrotor Navigation in Unknown Environments
Sep 18, 2025Quadrotor navigation in unknown environments is critical for practical missions such as search-and-rescue. Solving it requires addressing three key challenges: the non-convexity of free space due to obstacles, quadrotor-specific dynamics and objectives, and the need for exploration of unknown regions to find a path to the goal. Recently, the Model Predictive Path Integral (MPPI) method has emerged as a promising solution that solves the first two challenges. By leveraging sampling-based optimization, it can effectively handle non-convex free space while directly optimizing over the full quadrotor dynamics, enabling the inclusion of quadrotor-specific costs such as energy consumption. However, its performance in unknown environments is limited, as it lacks the ability to explore unknown regions when blocked by large obstacles. To solve this issue, we introduce Perception-Aware MPPI (PA-MPPI). Here, perception-awareness is defined as adapting the trajectory online based on perception objectives. Specifically, when the goal is occluded, PA-MPPI's perception cost biases trajectories that can perceive unknown regions. This expands the mapped traversable space and increases the likelihood of finding alternative paths to the goal. Through hardware experiments, we demonstrate that PA-MPPI, running at 50 Hz with our efficient perception and mapping module, performs up to 100% better than the baseline in our challenging settings where the state-of-the-art MPPI fails. In addition, we demonstrate that PA-MPPI can be used as a safe and robust action policy for navigation foundation models, which often provide goal poses that are not directly reachable.
ExT: Towards Scalable Autonomous Excavation via Large-Scale Multi-Task Pretraining and Fine-Tuning
Sep 18, 2025



Scaling up the deployment of autonomous excavators is of great economic and societal importance. Yet it remains a challenging problem, as effective systems must robustly handle unseen worksite conditions and new hardware configurations. Current state-of-the-art approaches rely on highly engineered, task-specific controllers, which require extensive manual tuning for each new scenario. In contrast, recent advances in large-scale pretrained models have shown remarkable adaptability across tasks and embodiments in domains such as manipulation and navigation, but their applicability to heavy construction machinery remains largely unexplored. In this work, we introduce ExT, a unified open-source framework for large-scale demonstration collection, pretraining, and fine-tuning of multitask excavation policies. ExT policies are first trained on large-scale demonstrations collected from a mix of experts, then fine-tuned either with supervised fine-tuning (SFT) or reinforcement learning fine-tuning (RLFT) to specialize to new tasks or operating conditions. Through both simulation and real-world experiments, we show that pretrained ExT policies can execute complete excavation cycles with centimeter-level accuracy, successfully transferring from simulation to real machine with performance comparable to specialized single-task controllers. Furthermore, in simulation, we demonstrate that ExT's fine-tuning pipelines allow rapid adaptation to new tasks, out-of-distribution conditions, and machine configurations, while maintaining strong performance on previously learned tasks. These results highlight the potential of ExT to serve as a foundation for scalable and generalizable autonomous excavation.
Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
Aug 28, 2025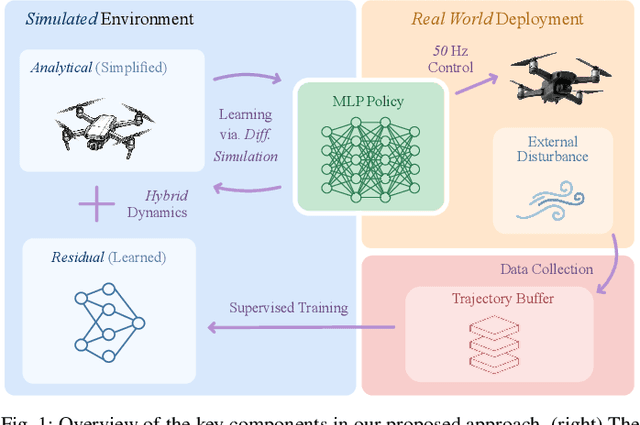

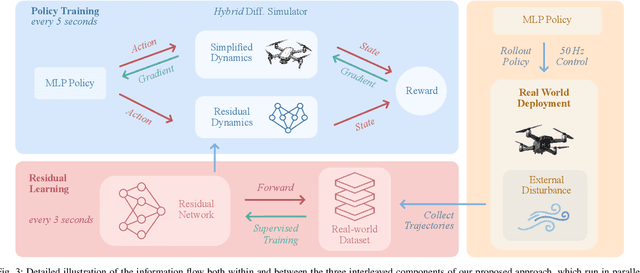
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.
Large Scale Robotic Material Handling: Learning, Planning, and Control
Aug 12, 2025Bulk material handling involves the efficient and precise moving of large quantities of materials, a core operation in many industries, including cargo ship unloading, waste sorting, construction, and demolition. These repetitive, labor-intensive, and safety-critical operations are typically performed using large hydraulic material handlers equipped with underactuated grippers. In this work, we present a comprehensive framework for the autonomous execution of large-scale material handling tasks. The system integrates specialized modules for environment perception, pile attack point selection, path planning, and motion control. The main contributions of this work are two reinforcement learning-based modules: an attack point planner that selects optimal grasping locations on the material pile to maximize removal efficiency and minimize the number of scoops, and a robust trajectory following controller that addresses the precision and safety challenges associated with underactuated grippers in movement, while utilizing their free-swinging nature to release material through dynamic throwing. We validate our framework through real-world experiments on a 40 t material handler in a representative worksite, focusing on two key tasks: high-throughput bulk pile management and high-precision truck loading. Comparative evaluations against human operators demonstrate the system's effectiveness in terms of precision, repeatability, and operational safety. To the best of our knowledge, this is the first complete automation of material handling tasks on a full scale.
Seeing All the Angles: Learning Multiview Manipulation Policies for Contact-Rich Tasks from Demonstrations
Apr 28, 2021
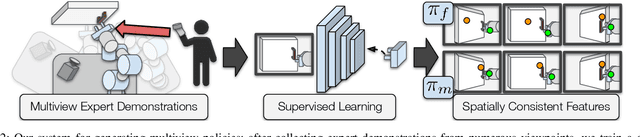
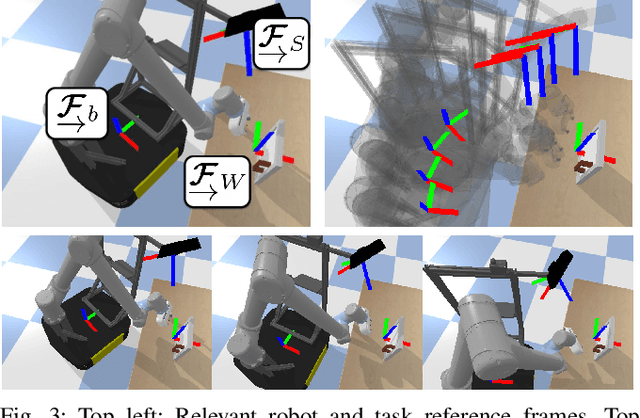
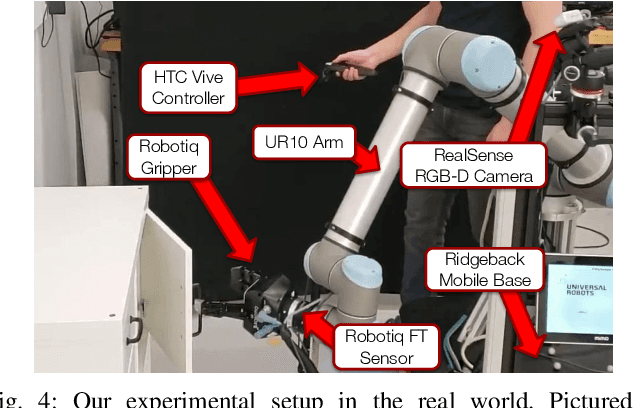
Learned visuomotor policies have shown considerable success as an alternative to traditional, hand-crafted frameworks for robotic manipulation tasks. Surprisingly, the extension of these methods to the multiview domain is relatively unexplored. A successful multiview policy could be deployed on a mobile manipulation platform, allowing it to complete a task regardless of its view of the scene. In this work, we demonstrate that a multiview policy can be found through imitation learning by collecting data from a variety of viewpoints. We illustrate the general applicability of the method by learning to complete several challenging multi-stage and contact-rich tasks, from numerous viewpoints, both in a simulated environment and on a real mobile manipulation platform. Furthermore, we analyze our policies to determine the benefits of learning from multiview data compared to learning with data from a fixed perspective. We show that learning from multiview data has little, if any, penalty to performance for a fixed-view task compared to learning with an equivalent amount of fixed-view data. Finally, we examine the visual features learned by the multiview and fixed-view policies. Our results indicate that multiview policies implicitly learn to identify spatially correlated features with a degree of view-invariance.