 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight
Mar 04, 2026Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55% to 100% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
A Fast Semidefinite Convex Relaxation for Optimal Control Problems With Spatio-Temporal Constraints
Jan 06, 2026Solving optimal control problems (OCPs) of autonomous agents operating under spatial and temporal constraints fast and accurately is essential in applications ranging from eco-driving of autonomous vehicles to quadrotor navigation. However, the nonlinear programs approximating the OCPs are inherently nonconvex due to the coupling between the dynamics and the event timing, and therefore, they are challenging to solve. Most approaches address this challenge by predefining waypoint times or just using nonconvex trajectory optimization, which simplifies the problem but often yields suboptimal solutions. To significantly improve the numerical properties, we propose a formulation with a time-scaling direct multiple shooting scheme that partitions the prediction horizon into segments aligned with characteristic time constraints. Moreover, we develop a fast semidefinite-programming-based convex relaxation that exploits the sparsity pattern of the lifted formulation. Comprehensive simulation studies demonstrate the solution optimality and computational efficiency. Furthermore, real-world experiments on a quadrotor waypoint flight task with constrained open time windows validate the practical applicability of the approach in complex environments.
Unifying Quadrotor Motion Planning and Control by Chaining Different Fidelity Models
Dec 13, 2025Many aerial tasks involving quadrotors demand both instant reactivity and long-horizon planning. High-fidelity models enable accurate control but are too slow for long horizons; low-fidelity planners scale but degrade closed-loop performance. We present Unique, a unified MPC that cascades models of different fidelity within a single optimization: a short-horizon, high-fidelity model for accurate control, and a long-horizon, low-fidelity model for planning. We align costs across horizons, derive feasibility-preserving thrust and body-rate constraints for the point-mass model, and introduce transition constraints that match the different states, thrust-induced acceleration, and jerk-body-rate relations. To prevent local minima emerging from nonsmooth clutter, we propose a 3D progressive smoothing schedule that morphs norm-based obstacles along the horizon. In addition, we deploy parallel randomly initialized MPC solvers to discover lower-cost local minima on the long, low-fidelity horizon. In simulation and real flights, under equal computational budgets, Unique improves closed-loop position or velocity tracking by up to 75% compared with standard MPC and hierarchical planner-tracker baselines. Ablations and Pareto analyses confirm robust gains across horizon variations, constraint approximations, and smoothing schedules.
PA-MPPI: Perception-Aware Model Predictive Path Integral Control for Quadrotor Navigation in Unknown Environments
Sep 18, 2025Quadrotor navigation in unknown environments is critical for practical missions such as search-and-rescue. Solving it requires addressing three key challenges: the non-convexity of free space due to obstacles, quadrotor-specific dynamics and objectives, and the need for exploration of unknown regions to find a path to the goal. Recently, the Model Predictive Path Integral (MPPI) method has emerged as a promising solution that solves the first two challenges. By leveraging sampling-based optimization, it can effectively handle non-convex free space while directly optimizing over the full quadrotor dynamics, enabling the inclusion of quadrotor-specific costs such as energy consumption. However, its performance in unknown environments is limited, as it lacks the ability to explore unknown regions when blocked by large obstacles. To solve this issue, we introduce Perception-Aware MPPI (PA-MPPI). Here, perception-awareness is defined as adapting the trajectory online based on perception objectives. Specifically, when the goal is occluded, PA-MPPI's perception cost biases trajectories that can perceive unknown regions. This expands the mapped traversable space and increases the likelihood of finding alternative paths to the goal. Through hardware experiments, we demonstrate that PA-MPPI, running at 50 Hz with our efficient perception and mapping module, performs up to 100% better than the baseline in our challenging settings where the state-of-the-art MPPI fails. In addition, we demonstrate that PA-MPPI can be used as a safe and robust action policy for navigation foundation models, which often provide goal poses that are not directly reachable.
Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
Aug 28, 2025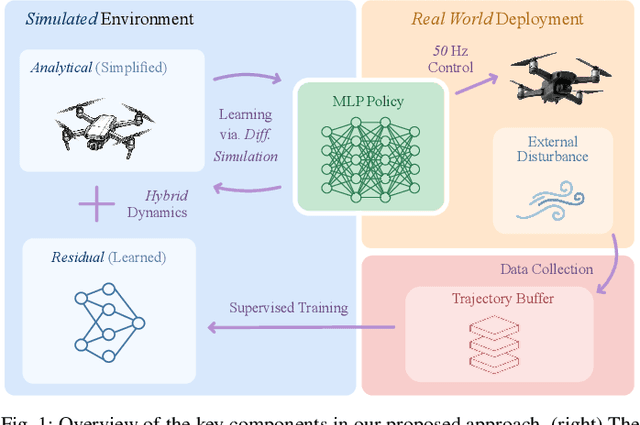

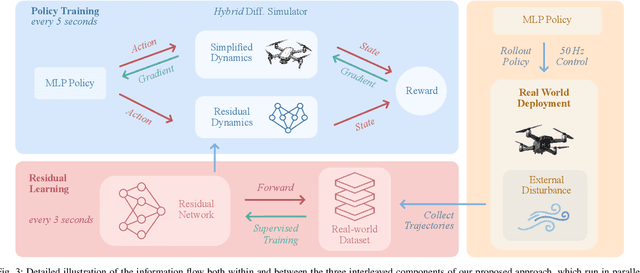
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.
Synthesis of Model Predictive Control and Reinforcement Learning: Survey and Classification
Feb 04, 2025



The fields of MPC and RL consider two successful control techniques for Markov decision processes. Both approaches are derived from similar fundamental principles, and both are widely used in practical applications, including robotics, process control, energy systems, and autonomous driving. Despite their similarities, MPC and RL follow distinct paradigms that emerged from diverse communities and different requirements. Various technical discrepancies, particularly the role of an environment model as part of the algorithm, lead to methodologies with nearly complementary advantages. Due to their orthogonal benefits, research interest in combination methods has recently increased significantly, leading to a large and growing set of complex ideas leveraging MPC and RL. This work illuminates the differences, similarities, and fundamentals that allow for different combination algorithms and categorizes existing work accordingly. Particularly, we focus on the versatile actor-critic RL approach as a basis for our categorization and examine how the online optimization approach of MPC can be used to improve the overall closed-loop performance of a policy.
AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
Jun 06, 2024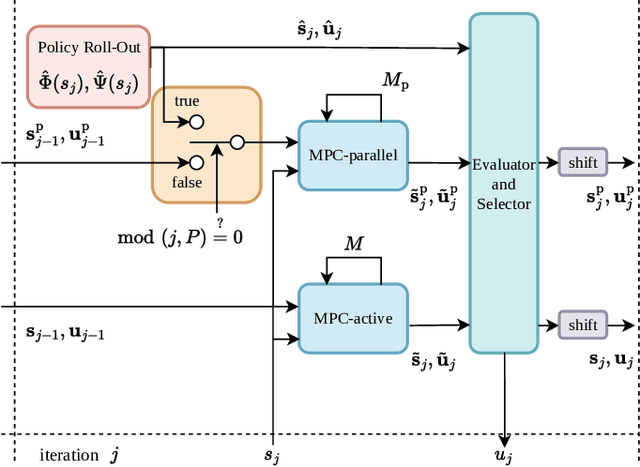
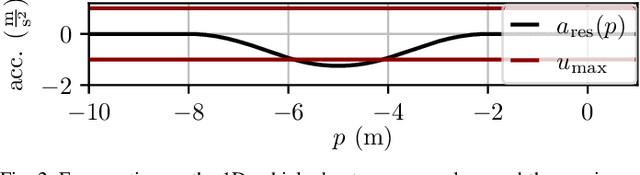
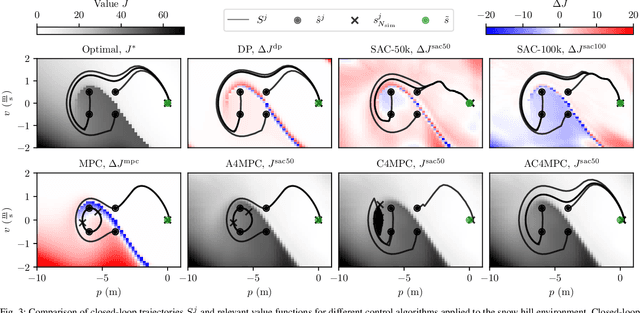
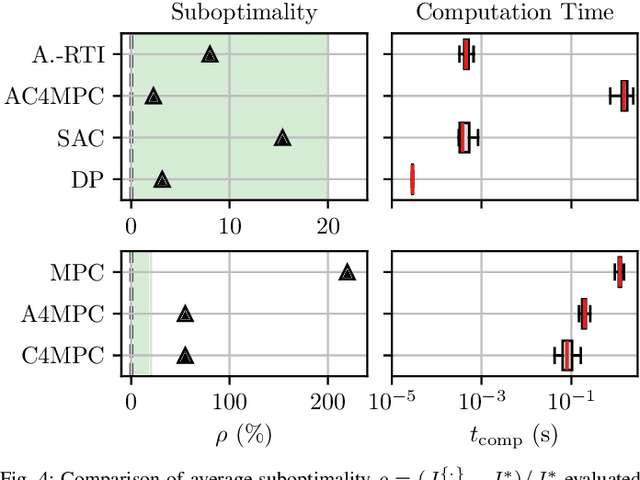
\Ac{MPC} and \ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic \ac{RL} techniques can be leveraged to improve the performance of \ac{MPC}. The \ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the \ac{MPC}. A parallel control architecture is proposed where each \ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original \ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the \ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an \ac{AD} overtaking scenario.
Equivariant Deep Learning of Mixed-Integer Optimal Control Solutions for Vehicle Decision Making and Motion Planning
May 13, 2024
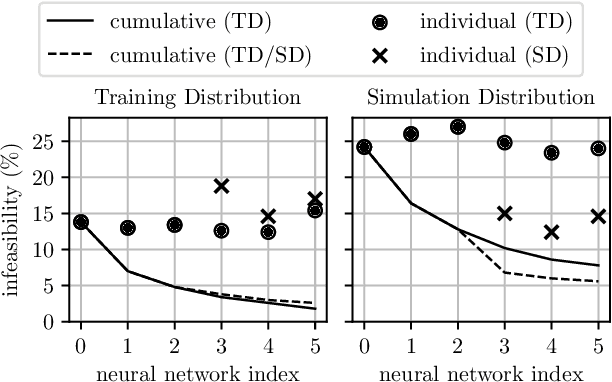
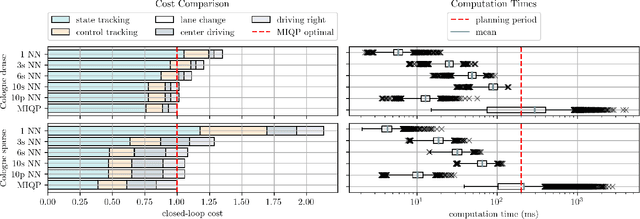

Mixed-integer quadratic programs (MIQPs) are a versatile way of formulating vehicle decision making and motion planning problems, where the prediction model is a hybrid dynamical system that involves both discrete and continuous decision variables. However, even the most advanced MIQP solvers can hardly account for the challenging requirements of automotive embedded platforms. Thus, we use machine learning to simplify and hence speed up optimization. Our work builds on recent ideas for solving MIQPs in real-time by training a neural network to predict the optimal values of integer variables and solving the remaining problem by online quadratic programming. Specifically, we propose a recurrent permutation equivariant deep set that is particularly suited for imitating MIQPs that involve many obstacles, which is often the major source of computational burden in motion planning problems. Our framework comprises also a feasibility projector that corrects infeasible predictions of integer variables and considerably increases the likelihood of computing a collision-free trajectory. We evaluate the performance, safety and real-time feasibility of decision-making for autonomous driving using the proposed approach on realistic multi-lane traffic scenarios with interactive agents in SUMO simulations.
A Long-Short-Term Mixed-Integer Formulation for Highway Lane Change Planning
May 05, 2024This work considers the problem of optimal lane changing in a structured multi-agent road environment. A novel motion planning algorithm that can capture long-horizon dependencies as well as short-horizon dynamics is presented. Pivotal to our approach is a geometric approximation of the long-horizon combinatorial transition problem which we formulate in the continuous time-space domain. Moreover, a discrete-time formulation of a short-horizon optimal motion planning problem is formulated and combined with the long-horizon planner. Both individual problems, as well as their combination, are formulated as MIQP and solved in real-time by using state-of-the-art solvers. We show how the presented algorithm outperforms two other state-of-the-art motion planning algorithms in closed-loop performance and computation time in lane changing problems. Evaluations are performed using the traffic simulator SUMO, a custom low-level tracking model predictive controller, and high-fidelity vehicle models and scenarios, provided by the CommonRoad environment.
Frenet-Cartesian Model Representations for Automotive Obstacle Avoidance within Nonlinear MPC
Dec 22, 2022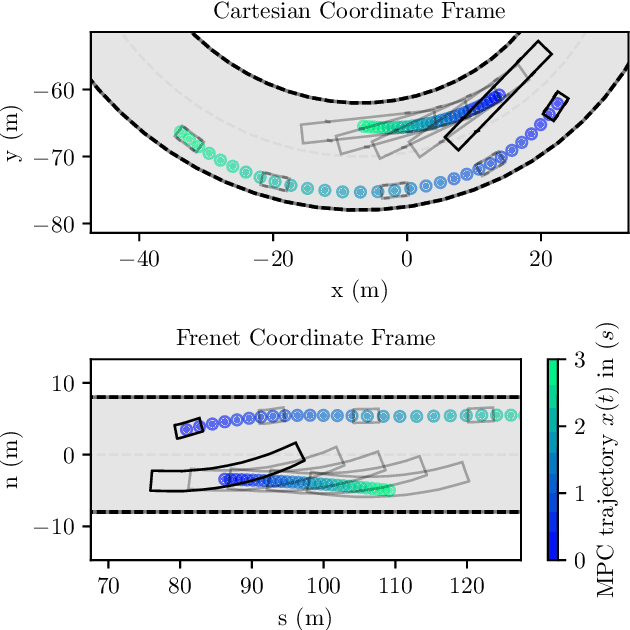

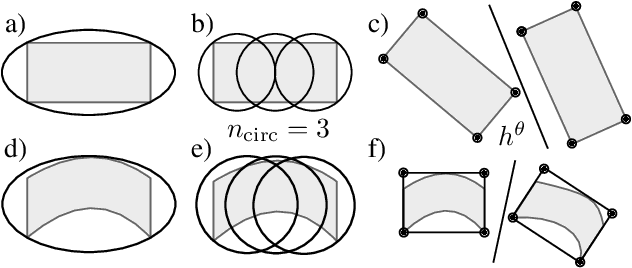
In recent years, nonlinear model predictive control (NMPC) has been extensively used for solving automotive motion control and planning tasks. In order to formulate the NMPC problem, different coordinate systems can be used with different advantages. We propose and compare formulations for the NMPC related optimization problem, involving a Cartesian and a Frenet coordinate frame (CCF/ FCF) in a single nonlinear program (NLP). We specify costs and collision avoidance constraints in the more advantageous coordinate frame, derive appropriate formulations and compare different obstacle constraints. With this approach, we exploit the simpler formulation of opponent vehicle constraints in the CCF, as well as road aligned costs and constraints related to the FCF. Comparisons to other approaches in a simulation framework highlight the advantages of the proposed approaches.