 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Nonlinear Model Predictive Control
May 02, 2025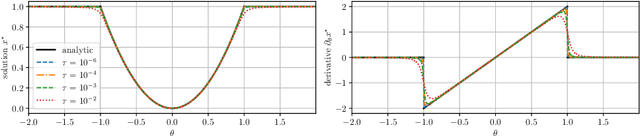

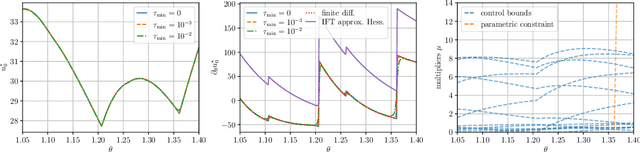

The efficient computation of parametric solution sensitivities is a key challenge in the integration of learning-enhanced methods with nonlinear model predictive control (MPC), as their availability is crucial for many learning algorithms. While approaches presented in the machine learning community are limited to convex or unconstrained formulations, this paper discusses the computation of solution sensitivities of general nonlinear programs (NLPs) using the implicit function theorem (IFT) and smoothed optimality conditions treated in interior-point methods (IPM). We detail sensitivity computation within a sequential quadratic programming (SQP) method which employs an IPM for the quadratic subproblems. The publication is accompanied by an efficient open-source implementation within the framework, providing both forward and adjoint sensitivities for general optimal control problems, achieving speedups exceeding 3x over the state-of-the-art solver mpc.pytorch.
Synthesis of Model Predictive Control and Reinforcement Learning: Survey and Classification
Feb 04, 2025



The fields of MPC and RL consider two successful control techniques for Markov decision processes. Both approaches are derived from similar fundamental principles, and both are widely used in practical applications, including robotics, process control, energy systems, and autonomous driving. Despite their similarities, MPC and RL follow distinct paradigms that emerged from diverse communities and different requirements. Various technical discrepancies, particularly the role of an environment model as part of the algorithm, lead to methodologies with nearly complementary advantages. Due to their orthogonal benefits, research interest in combination methods has recently increased significantly, leading to a large and growing set of complex ideas leveraging MPC and RL. This work illuminates the differences, similarities, and fundamentals that allow for different combination algorithms and categorizes existing work accordingly. Particularly, we focus on the versatile actor-critic RL approach as a basis for our categorization and examine how the online optimization approach of MPC can be used to improve the overall closed-loop performance of a policy.
All AI Models are Wrong, but Some are Optimal
Jan 10, 2025



AI models that predict the future behavior of a system (a.k.a. predictive AI models) are central to intelligent decision-making. However, decision-making using predictive AI models often results in suboptimal performance. This is primarily because AI models are typically constructed to best fit the data, and hence to predict the most likely future rather than to enable high-performance decision-making. The hope that such prediction enables high-performance decisions is neither guaranteed in theory nor established in practice. In fact, there is increasing empirical evidence that predictive models must be tailored to decision-making objectives for performance. In this paper, we establish formal (necessary and sufficient) conditions that a predictive model (AI-based or not) must satisfy for a decision-making policy established using that model to be optimal. We then discuss their implications for building predictive AI models for sequential decision-making.
Deep active learning for nonlinear system identification
Feb 24, 2023



The exploding research interest for neural networks in modeling nonlinear dynamical systems is largely explained by the networks' capacity to model complex input-output relations directly from data. However, they typically need vast training data before they can be put to any good use. The data generation process for dynamical systems can be an expensive endeavor both in terms of time and resources. Active learning addresses this shortcoming by acquiring the most informative data, thereby reducing the need to collect enormous datasets. What makes the current work unique is integrating the deep active learning framework into nonlinear system identification. We formulate a general static deep active learning acquisition problem for nonlinear system identification. This is enabled by exploring system dynamics locally in different regions of the input space to obtain a simulated dataset covering the broader input space. This simulated dataset can be used in a static deep active learning acquisition scheme referred to as global explorations. The global exploration acquires a batch of initial states corresponding to the most informative state-action trajectories according to a batch acquisition function. The local exploration solves an optimal control problem, finding the control trajectory that maximizes some measure of information. After a batch of informative initial states is acquired, a new round of local explorations from the initial states in the batch is conducted to obtain a set of corresponding control trajectories that are to be applied on the system dynamics to get data from the system. Information measures used in the acquisition scheme are derived from the predictive variance of an ensemble of neural networks. The novel method outperforms standard data acquisition methods used for system identification of nonlinear dynamical systems in the case study performed on simulated data.
Learning-based MPC from Big Data Using Reinforcement Learning
Jan 04, 2023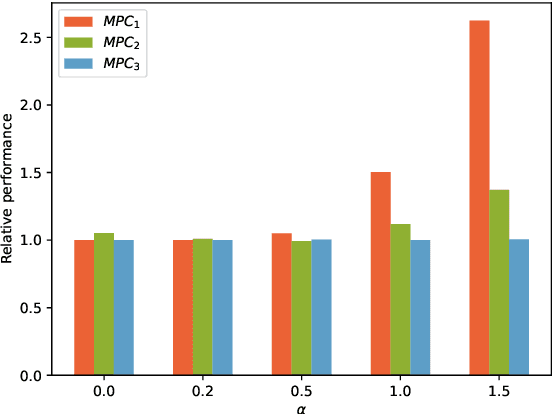
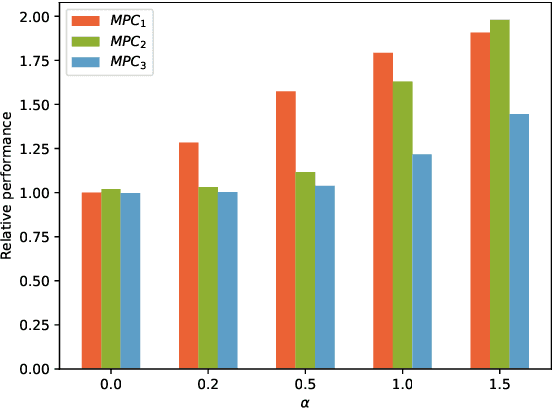
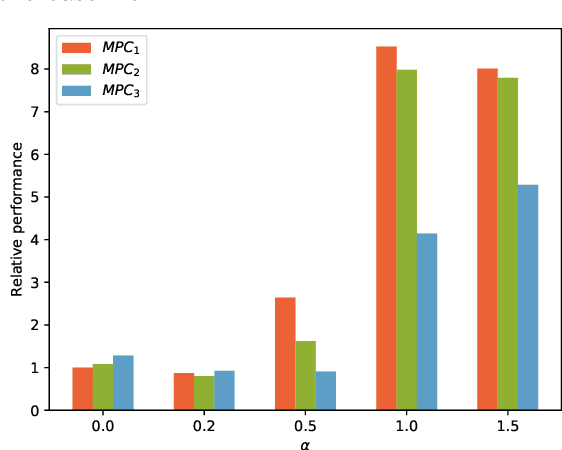
This paper presents an approach for learning Model Predictive Control (MPC) schemes directly from data using Reinforcement Learning (RL) methods. The state-of-the-art learning methods use RL to improve the performance of parameterized MPC schemes. However, these learning algorithms are often gradient-based methods that require frequent evaluations of computationally expensive MPC schemes, thereby restricting their use on big datasets. We propose to tackle this issue by using tools from RL to learn a parameterized MPC scheme directly from data in an offline fashion. Our approach derives an MPC scheme without having to solve it over the collected dataset, thereby eliminating the computational complexity of existing techniques for big data. We evaluate the proposed method on three simulated experiments of varying complexity.
Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing UAVs: Field Experiments
Nov 07, 2021

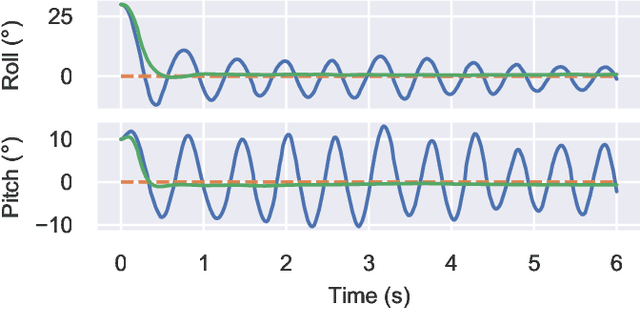

Attitude control of fixed-wing unmanned aerial vehicles (UAVs)is a difficult control problem in part due to uncertain nonlinear dynamics, actuator constraints, and coupled longitudinal and lateral motions. Current state-of-the-art autopilots are based on linear control and are thus limited in their effectiveness and performance. Deep reinforcement learning (DRL) is a machine learning method to automatically discover optimal control laws through interaction with the controlled system, that can handle complex nonlinear dynamics. We show in this paper that DRL can successfully learn to perform attitude control of a fixed-wing UAV operating directly on the original nonlinear dynamics, requiring as little as three minutes of flight data. We initially train our model in a simulation environment and then deploy the learned controller on the UAV in flight tests, demonstrating comparable performance to the state-of-the-art ArduPlaneproportional-integral-derivative (PID) attitude controller with no further online learning required. To better understand the operation of the learned controller we present an analysis of its behaviour, including a comparison to the existing well-tuned PID controller.