 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Why This Avoidance Maneuver?" Contrastive Explanations in Human-Supervised Maritime Autonomous Navigation
Apr 09, 2026Automated maritime collision avoidance will rely on human supervision for the foreseeable future. This necessitates transparency into how the system perceives a scenario and plans a maneuver. However, the causal logic behind avoidance maneuvers is often complex and difficult to convey to a navigator. This paper explores how to explain these factors in a selective, understandable manner for supervisors with a nautical background. We propose a method for generating contrastive explanations, which provide human-centric insights by comparing a system's proposed solution against relevant alternatives. To evaluate this, we developed a framework that uses visual and textual cues to highlight key objectives from a state-of-the-art collision avoidance system. An exploratory user study with four experienced marine officers suggests that contrastive explanations support the understanding of the system's objectives. However, our findings also reveal that while these explanations are highly valuable in complex multi-vessel encounters, they can increase cognitive workload, suggesting that future maritime interfaces may benefit most from demand-driven or scenario-specific explanation strategies.
An Informative Planning Framework for Target Tracking and Active Mapping in Dynamic Environments with ASVs
Aug 21, 2025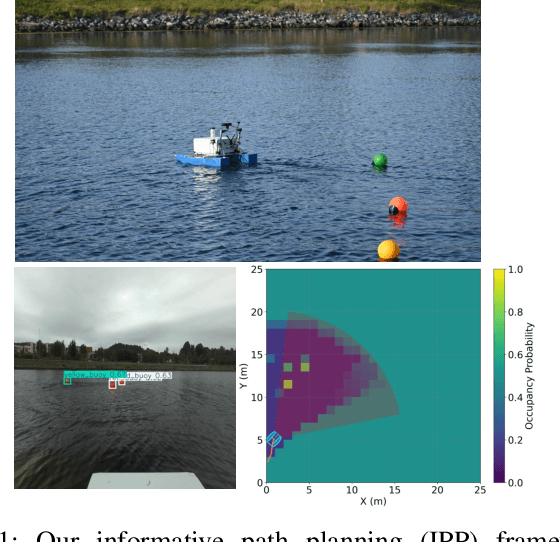
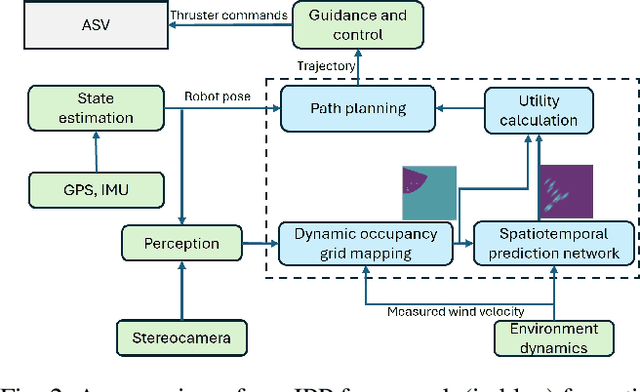
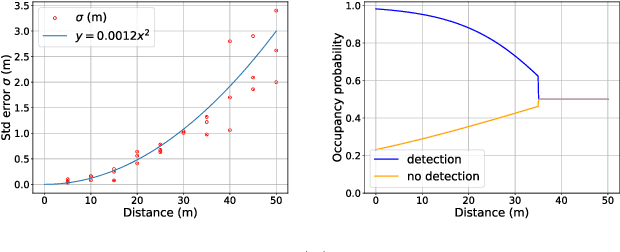
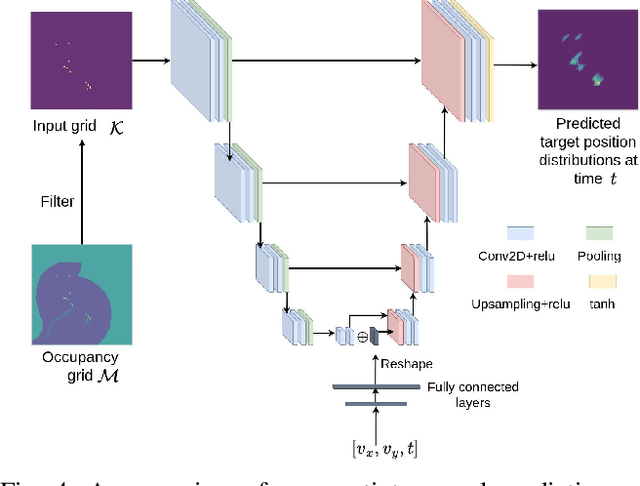
Mobile robot platforms are increasingly being used to automate information gathering tasks such as environmental monitoring. Efficient target tracking in dynamic environments is critical for applications such as search and rescue and pollutant cleanups. In this letter, we study active mapping of floating targets that drift due to environmental disturbances such as wind and currents. This is a challenging problem as it involves predicting both spatial and temporal variations in the map due to changing conditions. We propose an informative path planning framework to map an arbitrary number of moving targets with initially unknown positions in dynamic environments. A key component of our approach is a spatiotemporal prediction network that predicts target position distributions over time. We propose an adaptive planning objective for target tracking that leverages these predictions. Simulation experiments show that our proposed planning objective improves target tracking performance compared to existing methods that consider only entropy reduction as the planning objective. Finally, we validate our approach in field tests using an autonomous surface vehicle, showcasing its ability to track targets in real-world monitoring scenarios.
Efficient Online Learning and Adaptive Planning for Robotic Information Gathering Based on Streaming Data
Jul 17, 2025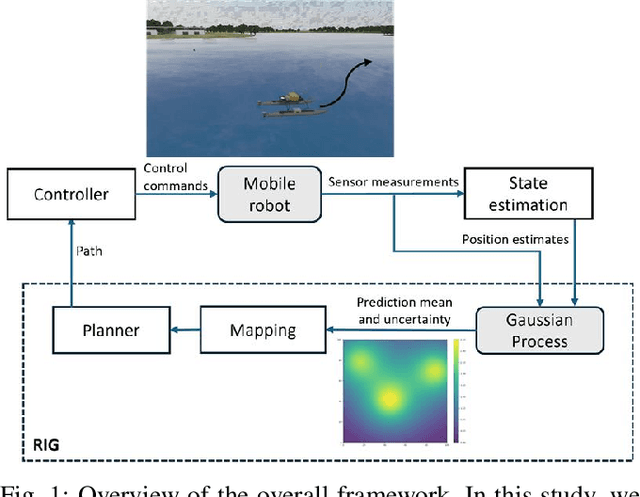
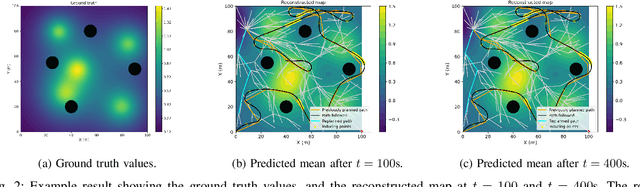
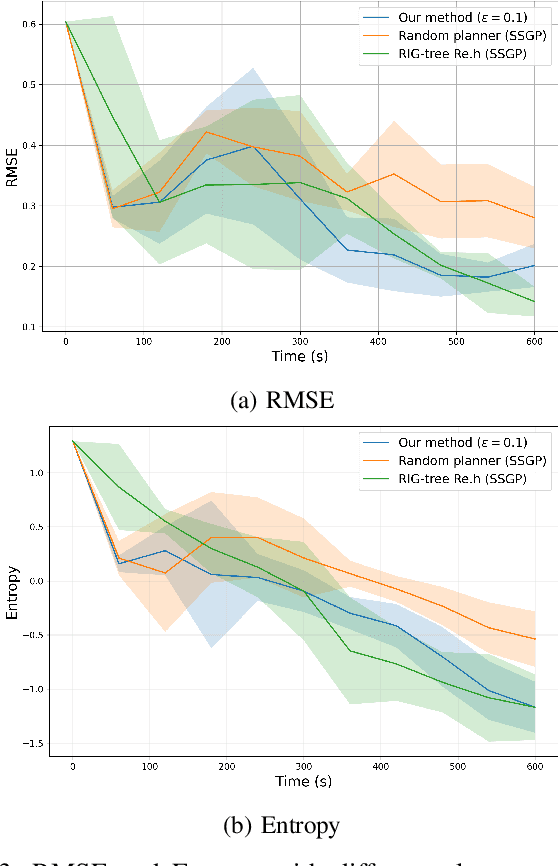
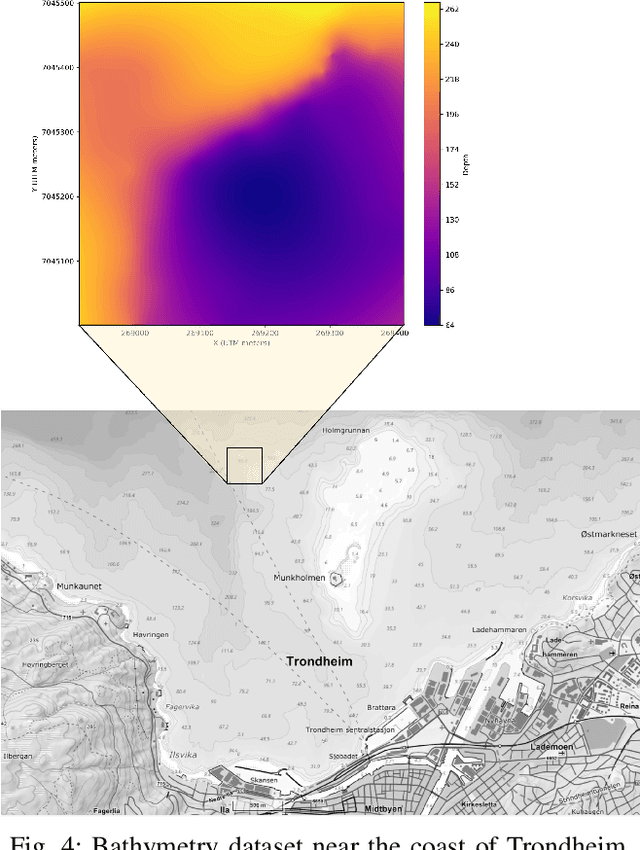
Robotic information gathering (RIG) techniques refer to methods where mobile robots are used to acquire data about the physical environment with a suite of sensors. Informative planning is an important part of RIG where the goal is to find sequences of actions or paths that maximize efficiency or the quality of information collected. Many existing solutions solve this problem by assuming that the environment is known in advance. However, real environments could be unknown or time-varying, and adaptive informative planning remains an active area of research. Adaptive planning and incremental online mapping are required for mapping initially unknown or varying spatial fields. Gaussian process (GP) regression is a widely used technique in RIG for mapping continuous spatial fields. However, it falls short in many applications as its real-time performance does not scale well to large datasets. To address these challenges, this paper proposes an efficient adaptive informative planning approach for mapping continuous scalar fields with GPs with streaming sparse GPs. Simulation experiments are performed with a synthetic dataset and compared against existing benchmarks. Finally, it is also verified with a real-world dataset to further validate the efficacy of the proposed method. Results show that our method achieves similar mapping accuracy to the baselines while reducing computational complexity for longer missions.
A spherical amplitude-phase formulation for 3-D adaptive line-of-sight (ALOS) guidance with USGES stability guarantees
May 13, 2025A recently proposed 3-D adaptive line-of-sight (ALOS) path-following algorithm addressed coupled motion dynamics of marine craft, aircraft, and uncrewed vehicles under environmental disturbances such as wind, waves, and ocean currents. Stability analysis established uniform semiglobal exponential stability (USGES) of the cross- and vertical-track errors using a body-velocity-based amplitude-phase representation of the North-East-Down (NED) kinematic differential equations. In this brief paper, we revisit the ALOS framework and introduce a novel spherical amplitude-phase representation. This formulation yields a more geometrically intuitive and physically observable description of the guidance errors and enables a significantly simplified stability proof. Unlike the previous model, which relied on a vertical crab angle derived from body-frame velocities, the new representation uses an alternative vertical crab angle and retains the USGES property. It also removes restrictive assumptions such as constant altitude/depth or zero horizontal crab angle, and remains valid for general 3-D maneuvers with nonzero roll, pitch, and flight-path angles.
Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing UAVs: Field Experiments
Nov 07, 2021

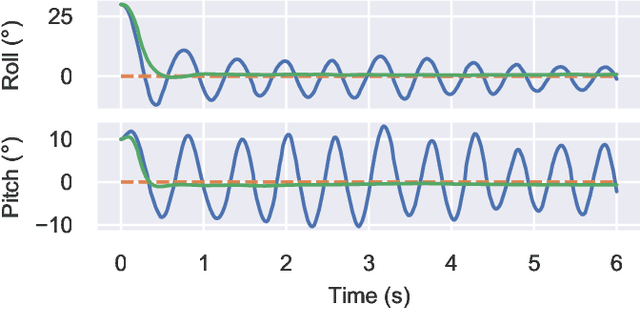

Attitude control of fixed-wing unmanned aerial vehicles (UAVs)is a difficult control problem in part due to uncertain nonlinear dynamics, actuator constraints, and coupled longitudinal and lateral motions. Current state-of-the-art autopilots are based on linear control and are thus limited in their effectiveness and performance. Deep reinforcement learning (DRL) is a machine learning method to automatically discover optimal control laws through interaction with the controlled system, that can handle complex nonlinear dynamics. We show in this paper that DRL can successfully learn to perform attitude control of a fixed-wing UAV operating directly on the original nonlinear dynamics, requiring as little as three minutes of flight data. We initially train our model in a simulation environment and then deploy the learned controller on the UAV in flight tests, demonstrating comparable performance to the state-of-the-art ArduPlaneproportional-integral-derivative (PID) attitude controller with no further online learning required. To better understand the operation of the learned controller we present an analysis of its behaviour, including a comparison to the existing well-tuned PID controller.
Deep Reinforcement Learning Attitude Control of Fixed-Wing UAVs Using Proximal Policy Optimization
Nov 13, 2019
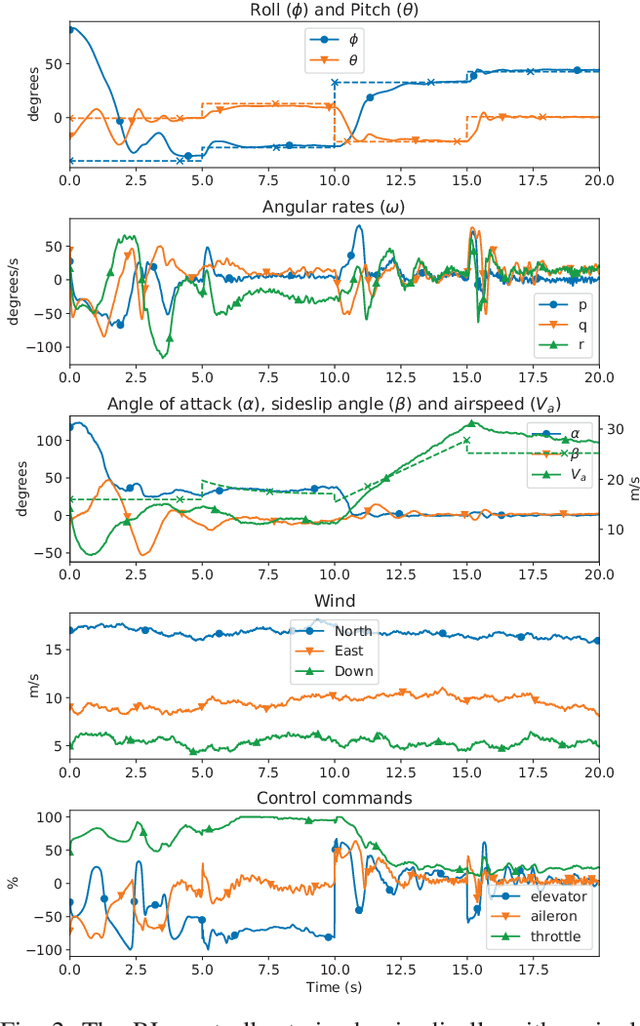
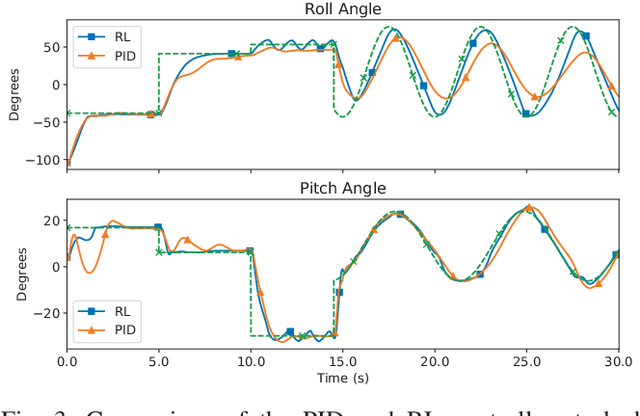

Contemporary autopilot systems for unmanned aerial vehicles (UAVs) are far more limited in their flight envelope as compared to experienced human pilots, thereby restricting the conditions UAVs can operate in and the types of missions they can accomplish autonomously. This paper proposes a deep reinforcement learning (DRL) controller to handle the nonlinear attitude control problem, enabling extended flight envelopes for fixed-wing UAVs. A proof-of-concept controller using the proximal policy optimization (PPO) algorithm is developed, and is shown to be capable of stabilizing a fixed-wing UAV from a large set of initial conditions to reference roll, pitch and airspeed values. The training process is outlined and key factors for its progression rate are considered, with the most important factor found to be limiting the number of variables in the observation vector, and including values for several previous time steps for these variables. The trained reinforcement learning (RL) controller is compared to a proportional-integral-derivative (PID) controller, and is found to converge in more cases than the PID controller, with comparable performance. Furthermore, the RL controller is shown to generalize well to unseen disturbances in the form of wind and turbulence, even in severe disturbance conditions.
* 11 pages, 3 figures, 2019 International Conference on Unmanned Aircraft Systems (ICUAS)