 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Attitude Control of Fixed-Wing UAVs Using Proximal Policy Optimization
Paper and Code

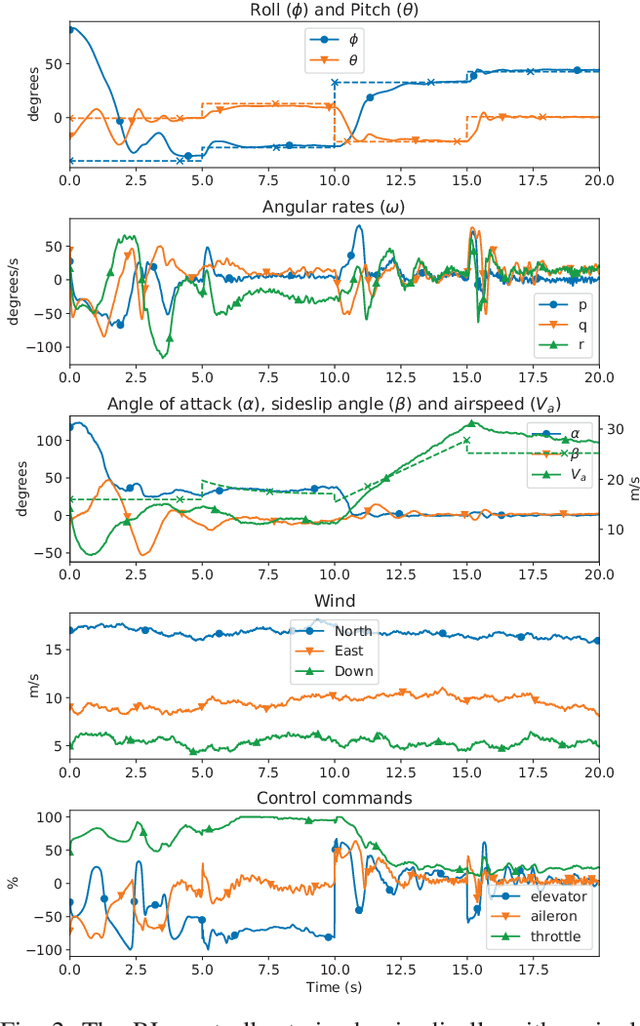
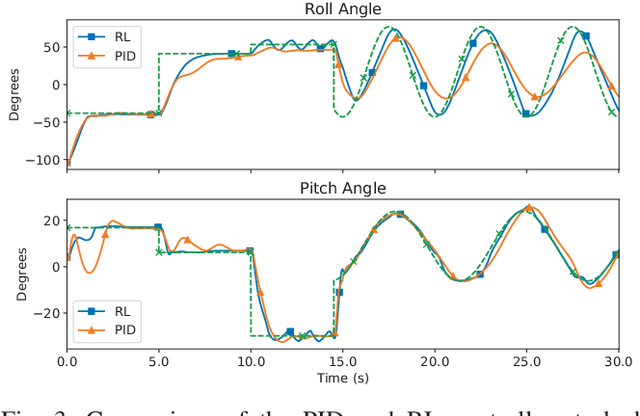

Contemporary autopilot systems for unmanned aerial vehicles (UAVs) are far more limited in their flight envelope as compared to experienced human pilots, thereby restricting the conditions UAVs can operate in and the types of missions they can accomplish autonomously. This paper proposes a deep reinforcement learning (DRL) controller to handle the nonlinear attitude control problem, enabling extended flight envelopes for fixed-wing UAVs. A proof-of-concept controller using the proximal policy optimization (PPO) algorithm is developed, and is shown to be capable of stabilizing a fixed-wing UAV from a large set of initial conditions to reference roll, pitch and airspeed values. The training process is outlined and key factors for its progression rate are considered, with the most important factor found to be limiting the number of variables in the observation vector, and including values for several previous time steps for these variables. The trained reinforcement learning (RL) controller is compared to a proportional-integral-derivative (PID) controller, and is found to converge in more cases than the PID controller, with comparable performance. Furthermore, the RL controller is shown to generalize well to unseen disturbances in the form of wind and turbulence, even in severe disturbance conditions.