 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning in wastewater treatment: insights from modelling a pilot denitrification reactor
Dec 18, 2024



Wastewater treatment plants are increasingly recognized as promising candidates for machine learning applications, due to their societal importance and high availability of data. However, their varied designs, operational conditions, and influent characteristics hinder straightforward automation. In this study, we use data from a pilot reactor at the Veas treatment facility in Norway to explore how machine learning can be used to optimize biological nitrate ($\mathrm{NO_3^-}$) reduction to molecular nitrogen ($\mathrm{N_2}$) in the biogeochemical process known as \textit{denitrification}. Rather than focusing solely on predictive accuracy, our approach prioritizes understanding the foundational requirements for effective data-driven modelling of wastewater treatment. Specifically, we aim to identify which process parameters are most critical, the necessary data quantity and quality, how to structure data effectively, and what properties are required by the models. We find that nonlinear models perform best on the training and validation data sets, indicating nonlinear relationships to be learned, but linear models transfer better to the unseen test data, which comes later in time. The variable measuring the water temperature has a particularly detrimental effect on the models, owing to a significant change in distributions between training and test data. We therefore conclude that multiple years of data is necessary to learn robust machine learning models. By addressing foundational elements, particularly in the context of the climatic variability faced by northern regions, this work lays the groundwork for a more structured and tailored approach to machine learning for wastewater treatment. We share publicly both the data and code used to produce the results in the paper.
Recency-Weighted Temporally-Segmented Ensemble for Time-Series Modeling
Mar 04, 2024



Time-series modeling in process industries faces the challenge of dealing with complex, multi-faceted, and evolving data characteristics. Conventional single model approaches often struggle to capture the interplay of diverse dynamics, resulting in suboptimal forecasts. Addressing this, we introduce the Recency-Weighted Temporally-Segmented (ReWTS, pronounced `roots') ensemble model, a novel chunk-based approach for multi-step forecasting. The key characteristics of the ReWTS model are twofold: 1) It facilitates specialization of models into different dynamics by segmenting the training data into `chunks' of data and training one model per chunk. 2) During inference, an optimization procedure assesses each model on the recent past and selects the active models, such that the appropriate mixture of previously learned dynamics can be recalled to forecast the future. This method not only captures the nuances of each period, but also adapts more effectively to changes over time compared to conventional `global' models trained on all data in one go. We present a comparative analysis, utilizing two years of data from a wastewater treatment plant and a drinking water treatment plant in Norway, demonstrating the ReWTS ensemble's superiority. It consistently outperforms the global model in terms of mean squared forecasting error across various model architectures by 10-70\% on both datasets, notably exhibiting greater resilience to outliers. This approach shows promise in developing automatic, adaptable forecasting models for decision-making and control systems in process industries and other complex systems.
Port-Hamiltonian Neural Networks with State Dependent Ports
Jun 06, 2022
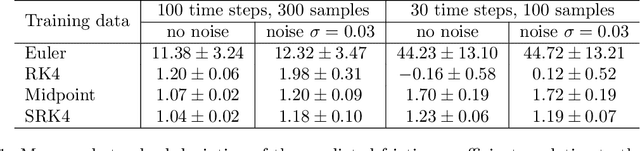
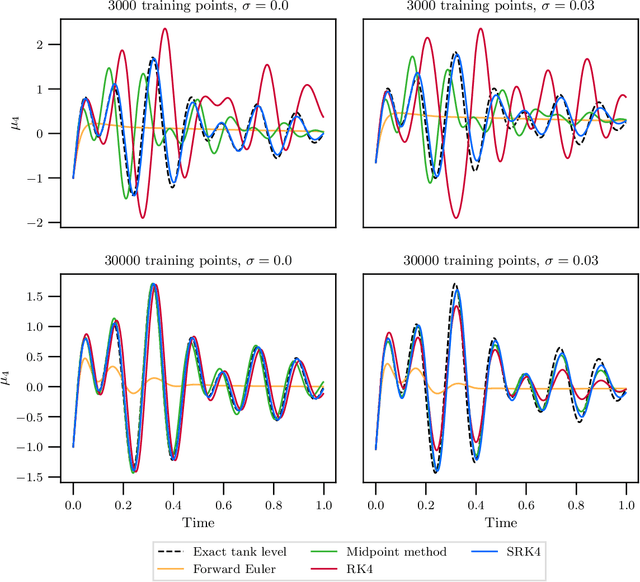
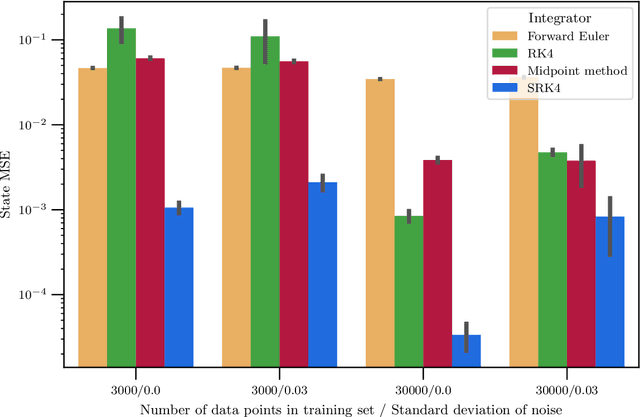
Hybrid machine learning based on Hamiltonian formulations has recently been successfully demonstrated for simple mechanical systems. In this work, we stress-test the method on both simple mass-spring systems and more complex and realistic systems with several internal and external forces, including a system with multiple connected tanks. We quantify performance under various conditions and show that imposing different assumptions greatly affect the performance during training presenting advantages and limitations of the method. We demonstrate that port-Hamiltonian neural networks can be extended to larger dimensions with state-dependent ports. We consider learning on systems with known and unknown external forces and show how it can be used to detect deviations in a system and still provide a valid model when the deviations are removed. Finally, we propose a symmetric high-order integrator for improved training on sparse and noisy data.
Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing UAVs: Field Experiments
Nov 07, 2021

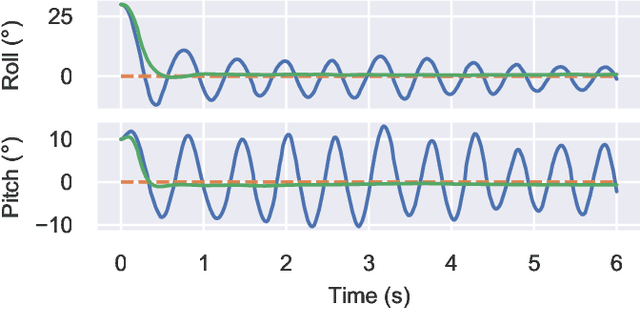

Attitude control of fixed-wing unmanned aerial vehicles (UAVs)is a difficult control problem in part due to uncertain nonlinear dynamics, actuator constraints, and coupled longitudinal and lateral motions. Current state-of-the-art autopilots are based on linear control and are thus limited in their effectiveness and performance. Deep reinforcement learning (DRL) is a machine learning method to automatically discover optimal control laws through interaction with the controlled system, that can handle complex nonlinear dynamics. We show in this paper that DRL can successfully learn to perform attitude control of a fixed-wing UAV operating directly on the original nonlinear dynamics, requiring as little as three minutes of flight data. We initially train our model in a simulation environment and then deploy the learned controller on the UAV in flight tests, demonstrating comparable performance to the state-of-the-art ArduPlaneproportional-integral-derivative (PID) attitude controller with no further online learning required. To better understand the operation of the learned controller we present an analysis of its behaviour, including a comparison to the existing well-tuned PID controller.
Optimization of the Model Predictive Control Meta-Parameters Through Reinforcement Learning
Nov 07, 2021
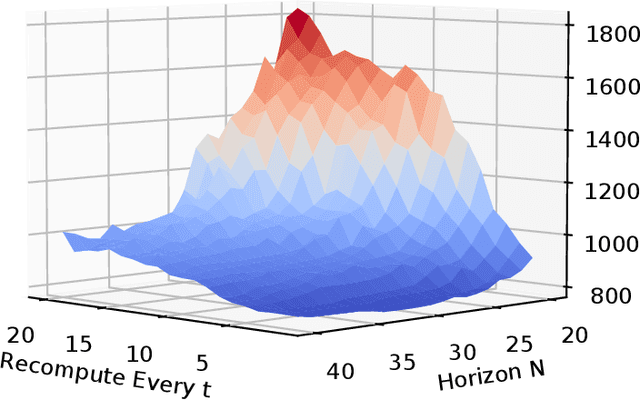
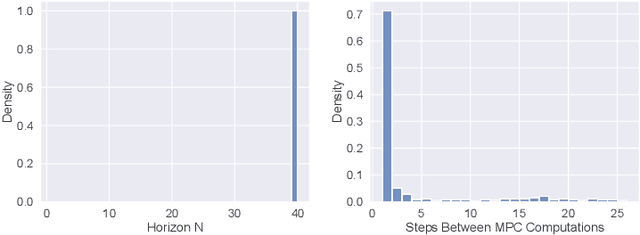
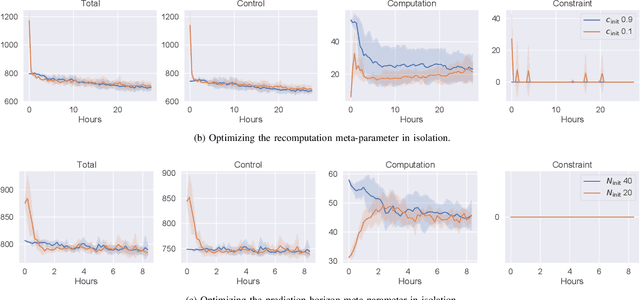
Model predictive control (MPC) is increasingly being considered for control of fast systems and embedded applications. However, the MPC has some significant challenges for such systems. Its high computational complexity results in high power consumption from the control algorithm, which could account for a significant share of the energy resources in battery-powered embedded systems. The MPC parameters must be tuned, which is largely a trial-and-error process that affects the control performance, the robustness and the computational complexity of the controller to a high degree. In this paper, we propose a novel framework in which any parameter of the control algorithm can be jointly tuned using reinforcement learning(RL), with the goal of simultaneously optimizing the control performance and the power usage of the control algorithm. We propose the novel idea of optimizing the meta-parameters of MPCwith RL, i.e. parameters affecting the structure of the MPCproblem as opposed to the solution to a given problem. Our control algorithm is based on an event-triggered MPC where we learn when the MPC should be re-computed, and a dual mode MPC and linear state feedback control law applied in between MPC computations. We formulate a novel mixture-distribution policy and show that with joint optimization we achieve improvements that do not present themselves when optimizing the same parameters in isolation. We demonstrate our framework on the inverted pendulum control task, reducing the total computation time of the control system by 36% while also improving the control performance by 18.4% over the best-performing MPC baseline.
Reinforcement Learning of the Prediction Horizon in Model Predictive Control
Feb 22, 2021
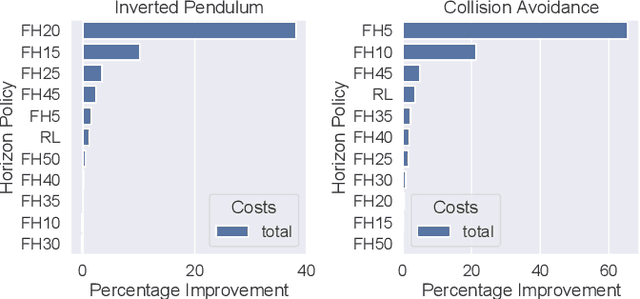
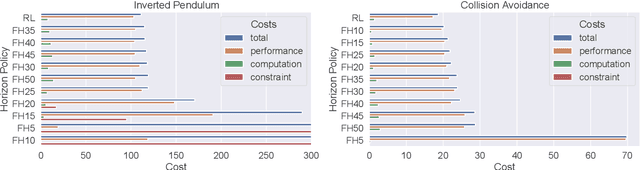
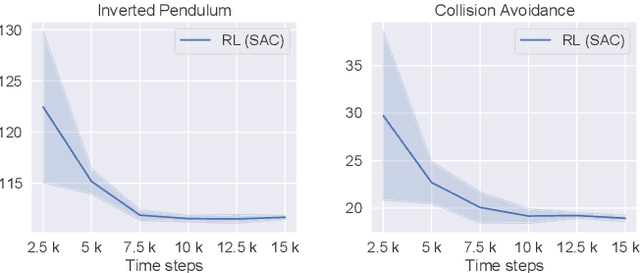
Model predictive control (MPC) is a powerful trajectory optimization control technique capable of controlling complex nonlinear systems while respecting system constraints and ensuring safe operation. The MPC's capabilities come at the cost of a high online computational complexity, the requirement of an accurate model of the system dynamics, and the necessity of tuning its parameters to the specific control application. The main tunable parameter affecting the computational complexity is the prediction horizon length, controlling how far into the future the MPC predicts the system response and thus evaluates the optimality of its computed trajectory. A longer horizon generally increases the control performance, but requires an increasingly powerful computing platform, excluding certain control applications.The performance sensitivity to the prediction horizon length varies over the state space, and this motivated the adaptive horizon model predictive control (AHMPC), which adapts the prediction horizon according to some criteria. In this paper we propose to learn the optimal prediction horizon as a function of the state using reinforcement learning (RL). We show how the RL learning problem can be formulated and test our method on two control tasks, showing clear improvements over the fixed horizon MPC scheme, while requiring only minutes of learning.
Optimization of the Model Predictive Control Update Interval Using Reinforcement Learning
Nov 26, 2020
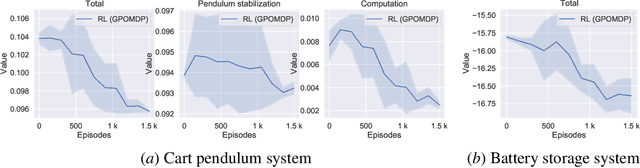

In control applications there is often a compromise that needs to be made with regards to the complexity and performance of the controller and the computational resources that are available. For instance, the typical hardware platform in embedded control applications is a microcontroller with limited memory and processing power, and for battery powered applications the control system can account for a significant portion of the energy consumption. We propose a controller architecture in which the computational cost is explicitly optimized along with the control objective. This is achieved by a three-part architecture where a high-level, computationally expensive controller generates plans, which a computationally simpler controller executes by compensating for prediction errors, while a recomputation policy decides when the plan should be recomputed. In this paper, we employ model predictive control (MPC) as the high-level plan-generating controller, a linear state feedback controller as the simpler compensating controller, and reinforcement learning (RL) to learn the recomputation policy. Simulation results for two examples showcase the architecture's ability to improve upon the MPC approach and find reasonable compromises weighing the performance on the control objective and the computational resources expended.
Accelerating Reinforcement Learning with Suboptimal Guidance
Nov 21, 2019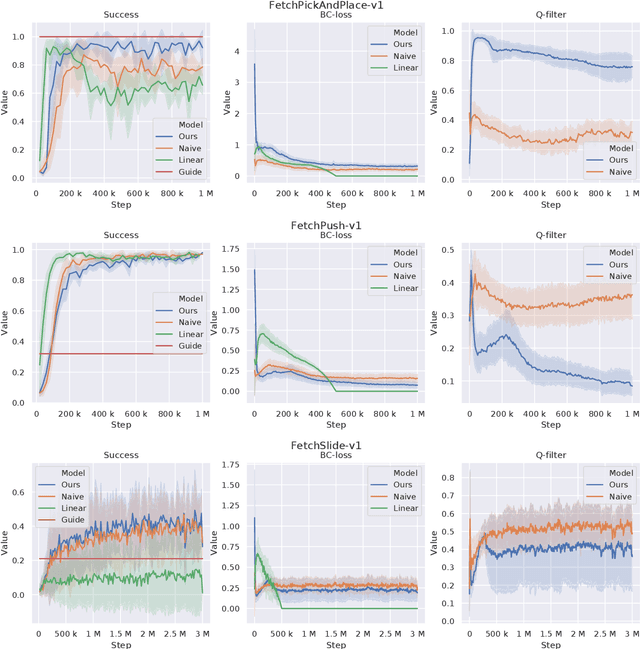
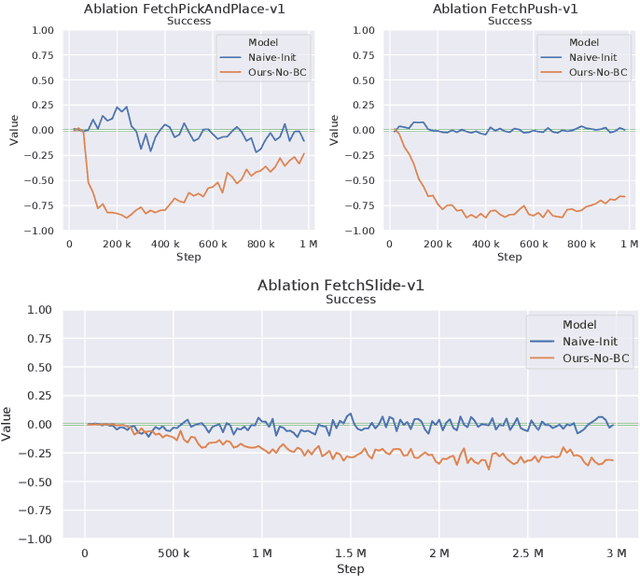
Reinforcement Learning in domains with sparse rewards is a difficult problem, and a large part of the training process is often spent searching the state space in a more or less random fashion for any learning signals. For control problems, we often have some controller readily available which might be suboptimal but nevertheless solves the problem to some degree. This controller can be used to guide the initial exploration phase of the learning controller towards reward yielding states, reducing the time before refinement of a viable policy can be initiated. In our work, the agent is guided through an auxiliary behaviour cloning loss which is made conditional on a Q-filter, i.e. it is only applied in situations where the critic deems the guiding controller to be better than the agent. The Q-filter provides a natural way to adjust the guidance throughout the training process, allowing the agent to exceed the guiding controller in a manner that is adaptive to the task at hand and the proficiency of the guiding controller. The contribution of this paper lies in identifying shortcomings in previously proposed implementations of the Q-filter concept, and in suggesting some ways these issues can be mitigated. These modifications are tested on the OpenAI Gym Fetch environments, showing clear improvements in adaptivity and yielding increased performance in all robotic environments tested.
Deep Reinforcement Learning Attitude Control of Fixed-Wing UAVs Using Proximal Policy Optimization
Nov 13, 2019
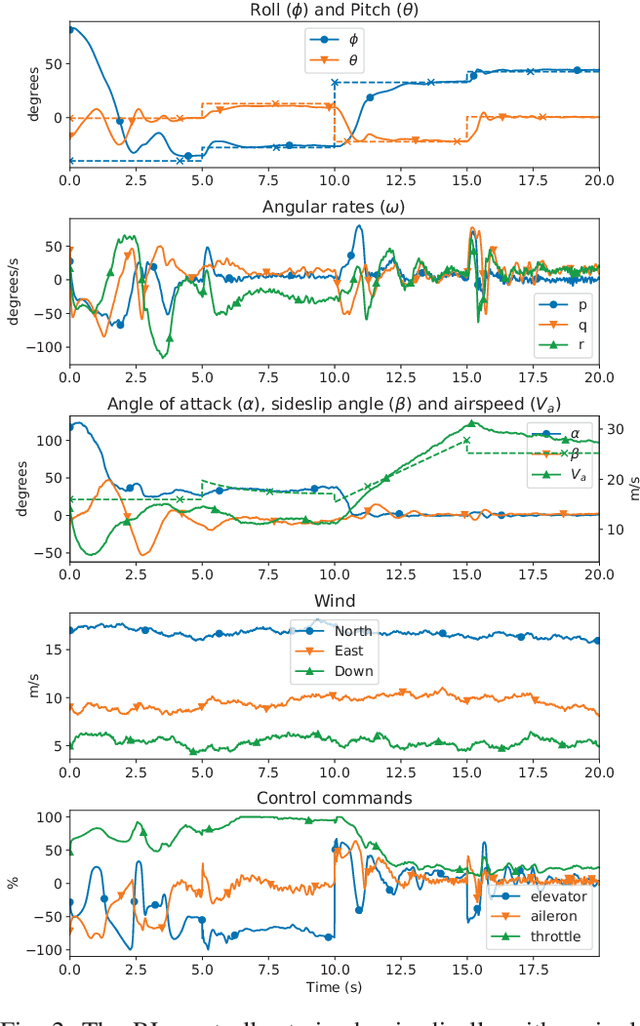
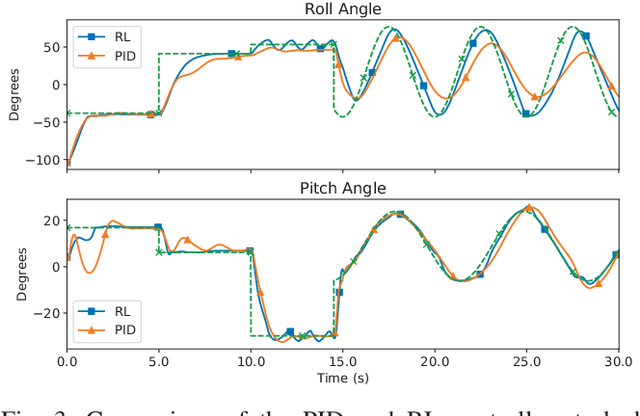

Contemporary autopilot systems for unmanned aerial vehicles (UAVs) are far more limited in their flight envelope as compared to experienced human pilots, thereby restricting the conditions UAVs can operate in and the types of missions they can accomplish autonomously. This paper proposes a deep reinforcement learning (DRL) controller to handle the nonlinear attitude control problem, enabling extended flight envelopes for fixed-wing UAVs. A proof-of-concept controller using the proximal policy optimization (PPO) algorithm is developed, and is shown to be capable of stabilizing a fixed-wing UAV from a large set of initial conditions to reference roll, pitch and airspeed values. The training process is outlined and key factors for its progression rate are considered, with the most important factor found to be limiting the number of variables in the observation vector, and including values for several previous time steps for these variables. The trained reinforcement learning (RL) controller is compared to a proportional-integral-derivative (PID) controller, and is found to converge in more cases than the PID controller, with comparable performance. Furthermore, the RL controller is shown to generalize well to unseen disturbances in the form of wind and turbulence, even in severe disturbance conditions.
* 11 pages, 3 figures, 2019 International Conference on Unmanned Aircraft Systems (ICUAS)