 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Reinforcement Learning with Suboptimal Guidance
Paper and Code
Nov 21, 2019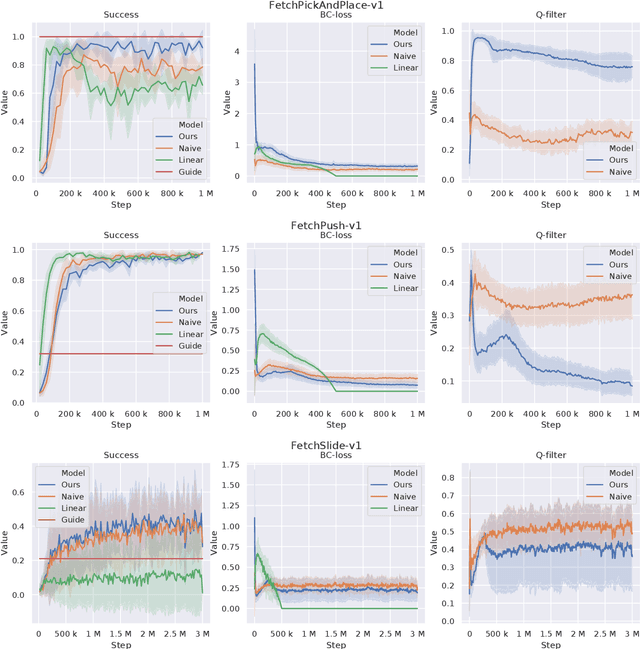
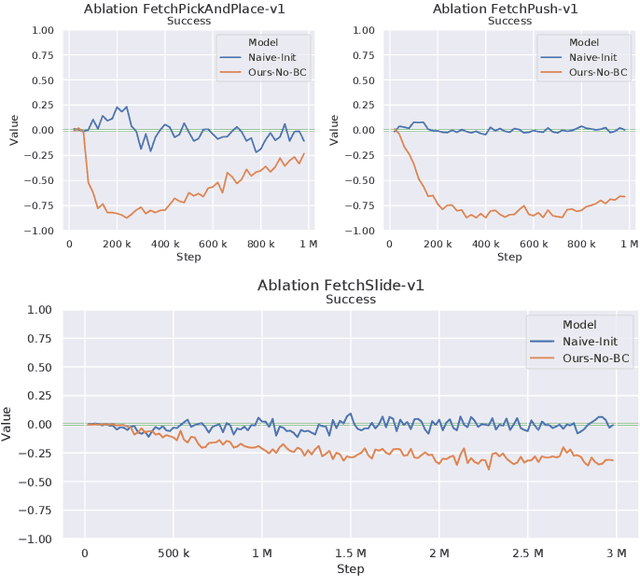
Reinforcement Learning in domains with sparse rewards is a difficult problem, and a large part of the training process is often spent searching the state space in a more or less random fashion for any learning signals. For control problems, we often have some controller readily available which might be suboptimal but nevertheless solves the problem to some degree. This controller can be used to guide the initial exploration phase of the learning controller towards reward yielding states, reducing the time before refinement of a viable policy can be initiated. In our work, the agent is guided through an auxiliary behaviour cloning loss which is made conditional on a Q-filter, i.e. it is only applied in situations where the critic deems the guiding controller to be better than the agent. The Q-filter provides a natural way to adjust the guidance throughout the training process, allowing the agent to exceed the guiding controller in a manner that is adaptive to the task at hand and the proficiency of the guiding controller. The contribution of this paper lies in identifying shortcomings in previously proposed implementations of the Q-filter concept, and in suggesting some ways these issues can be mitigated. These modifications are tested on the OpenAI Gym Fetch environments, showing clear improvements in adaptivity and yielding increased performance in all robotic environments tested.