 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Alignment in Forward-Backward Representations via Temporal Abstraction
Mar 23, 2026Forward-backward (FB) representations provide a powerful framework for learning the successor representation (SR) in continuous spaces by enforcing a low-rank factorization. However, a fundamental spectral mismatch often exists between the high-rank transition dynamics of continuous environments and the low-rank bottleneck of the FB architecture, making accurate low-rank representation learning difficult. In this work, we analyze temporal abstraction as a mechanism to mitigate this mismatch. By characterizing the spectral properties of the transition operator, we show that temporal abstraction acts as a low-pass filter that suppresses high-frequency spectral components. This suppression reduces the effective rank of the induced SR while preserving a formal bound on the resulting value function error. Empirically, we show that this alignment is a key factor for stable FB learning, particularly at high discount factors where bootstrapping becomes error-prone. Our results identify temporal abstraction as a principled mechanism for shaping the spectral structure of the underlying MDP and enabling effective long-horizon representations in continuous control.
Fitting Reinforcement Learning Model to Behavioral Data under Bandits
Nov 06, 2025
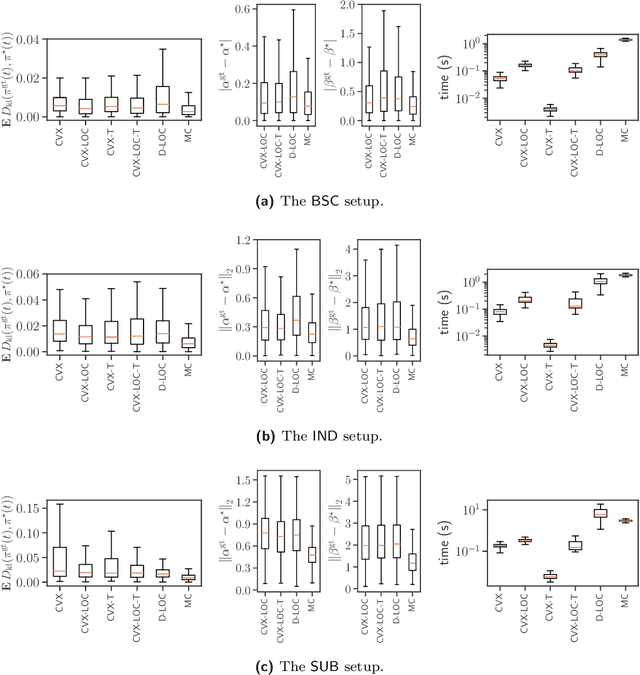

We consider the problem of fitting a reinforcement learning (RL) model to some given behavioral data under a multi-armed bandit environment. These models have received much attention in recent years for characterizing human and animal decision making behavior. We provide a generic mathematical optimization problem formulation for the fitting problem of a wide range of RL models that appear frequently in scientific research applications, followed by a detailed theoretical analysis of its convexity properties. Based on the theoretical results, we introduce a novel solution method for the fitting problem of RL models based on convex relaxation and optimization. Our method is then evaluated in several simulated bandit environments to compare with some benchmark methods that appear in the literature. Numerical results indicate that our method achieves comparable performance to the state-of-the-art, while significantly reducing computation time. We also provide an open-source Python package for our proposed method to empower researchers to apply it in the analysis of their datasets directly, without prior knowledge of convex optimization.
Differentiable Nonlinear Model Predictive Control
May 02, 2025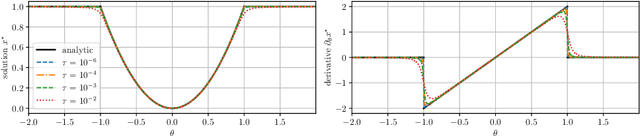

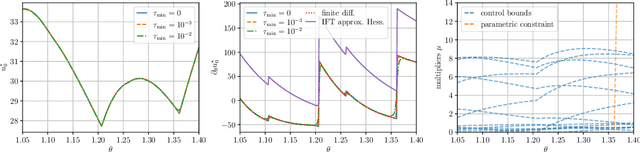

The efficient computation of parametric solution sensitivities is a key challenge in the integration of learning-enhanced methods with nonlinear model predictive control (MPC), as their availability is crucial for many learning algorithms. While approaches presented in the machine learning community are limited to convex or unconstrained formulations, this paper discusses the computation of solution sensitivities of general nonlinear programs (NLPs) using the implicit function theorem (IFT) and smoothed optimality conditions treated in interior-point methods (IPM). We detail sensitivity computation within a sequential quadratic programming (SQP) method which employs an IPM for the quadratic subproblems. The publication is accompanied by an efficient open-source implementation within the framework, providing both forward and adjoint sensitivities for general optimal control problems, achieving speedups exceeding 3x over the state-of-the-art solver mpc.pytorch.
Multi-convex Programming for Discrete Latent Factor Models Prototyping
Apr 02, 2025Discrete latent factor models (DLFMs) are widely used in various domains such as machine learning, economics, neuroscience, psychology, etc. Currently, fitting a DLFM to some dataset relies on a customized solver for individual models, which requires lots of effort to implement and is limited to the targeted specific instance of DLFMs. In this paper, we propose a generic framework based on CVXPY, which allows users to specify and solve the fitting problem of a wide range of DLFMs, including both regression and classification models, within a very short script. Our framework is flexible and inherently supports the integration of regularization terms and constraints on the DLFM parameters and latent factors, such that the users can easily prototype the DLFM structure according to their dataset and application scenario. We introduce our open-source Python implementation and illustrate the framework in several examples.
Synthesis of Model Predictive Control and Reinforcement Learning: Survey and Classification
Feb 04, 2025



The fields of MPC and RL consider two successful control techniques for Markov decision processes. Both approaches are derived from similar fundamental principles, and both are widely used in practical applications, including robotics, process control, energy systems, and autonomous driving. Despite their similarities, MPC and RL follow distinct paradigms that emerged from diverse communities and different requirements. Various technical discrepancies, particularly the role of an environment model as part of the algorithm, lead to methodologies with nearly complementary advantages. Due to their orthogonal benefits, research interest in combination methods has recently increased significantly, leading to a large and growing set of complex ideas leveraging MPC and RL. This work illuminates the differences, similarities, and fundamentals that allow for different combination algorithms and categorizes existing work accordingly. Particularly, we focus on the versatile actor-critic RL approach as a basis for our categorization and examine how the online optimization approach of MPC can be used to improve the overall closed-loop performance of a policy.
AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
Jun 06, 2024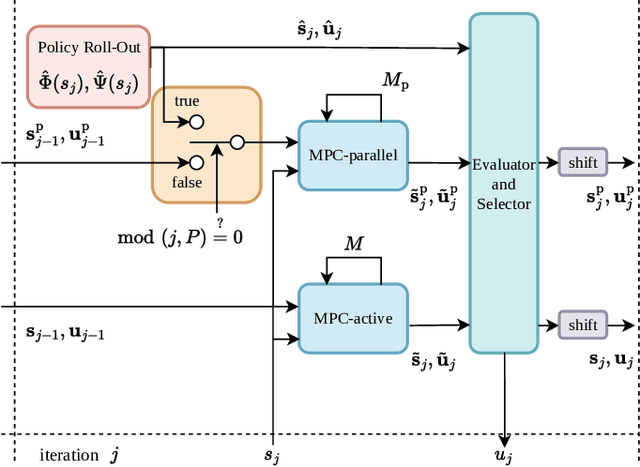
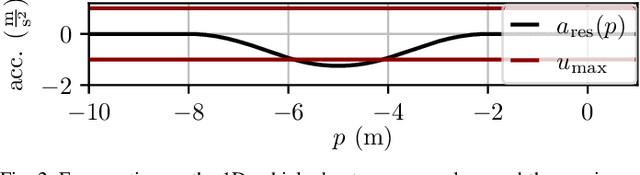
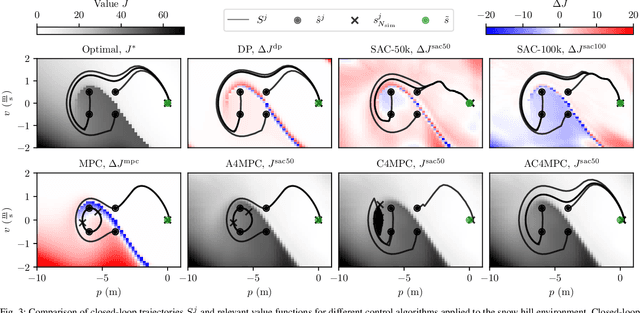
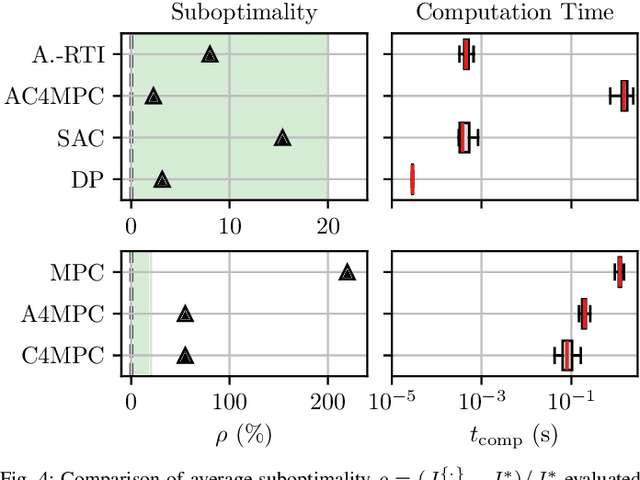
\Ac{MPC} and \ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic \ac{RL} techniques can be leveraged to improve the performance of \ac{MPC}. The \ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the \ac{MPC}. A parallel control architecture is proposed where each \ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original \ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the \ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an \ac{AD} overtaking scenario.
UDUC: An Uncertainty-driven Approach for Learning-based Robust Control
May 04, 2024Learning-based techniques have become popular in both model predictive control (MPC) and reinforcement learning (RL). Probabilistic ensemble (PE) models offer a promising approach for modelling system dynamics, showcasing the ability to capture uncertainty and scalability in high-dimensional control scenarios. However, PE models are susceptible to mode collapse, resulting in non-robust control when faced with environments slightly different from the training set. In this paper, we introduce the $\textbf{u}$ncertainty-$\textbf{d}$riven rob$\textbf{u}$st $\textbf{c}$ontrol (UDUC) loss as an alternative objective for training PE models, drawing inspiration from contrastive learning. We analyze the robustness of UDUC loss through the lens of robust optimization and evaluate its performance on the challenging Real-world Reinforcement Learning (RWRL) benchmark, which involves significant environmental mismatches between the training and testing environments.
PlanNetX: Learning an Efficient Neural Network Planner from MPC for Longitudinal Control
Apr 29, 2024


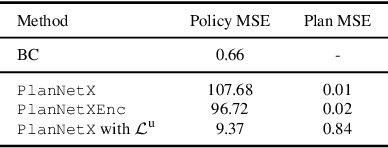
Model predictive control (MPC) is a powerful, optimization-based approach for controlling dynamical systems. However, the computational complexity of online optimization can be problematic on embedded devices. Especially, when we need to guarantee fixed control frequencies. Thus, previous work proposed to reduce the computational burden using imitation learning (IL) approximating the MPC policy by a neural network. In this work, we instead learn the whole planned trajectory of the MPC. We introduce a combination of a novel neural network architecture PlanNetX and a simple loss function based on the state trajectory that leverages the parameterized optimal control structure of the MPC. We validate our approach in the context of autonomous driving by learning a longitudinal planner and benchmarking it extensively in the CommonRoad simulator using synthetic scenarios and scenarios derived from real data. Our experimental results show that we can learn the open-loop MPC trajectory with high accuracy while improving the closed-loop performance of the learned control policy over other baselines like behavior cloning.
A Hierarchical Approach for Strategic Motion Planning in Autonomous Racing
Dec 03, 2022We present an approach for safe trajectory planning, where a strategic task related to autonomous racing is learned sample-efficient within a simulation environment. A high-level policy, represented as a neural network, outputs a reward specification that is used within the cost function of a parametric nonlinear model predictive controller (NMPC). By including constraints and vehicle kinematics in the NLP, we are able to guarantee safe and feasible trajectories related to the used model. Compared to classical reinforcement learning (RL), our approach restricts the exploration to safe trajectories, starts with a good prior performance and yields full trajectories that can be passed to a tracking lowest-level controller. We do not address the lowest-level controller in this work and assume perfect tracking of feasible trajectories. We show the superior performance of our algorithm on simulated racing tasks that include high-level decision making. The vehicle learns to efficiently overtake slower vehicles and to avoid getting overtaken by blocking faster vehicles.