 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanNetX: Learning an Efficient Neural Network Planner from MPC for Longitudinal Control
Apr 29, 2024


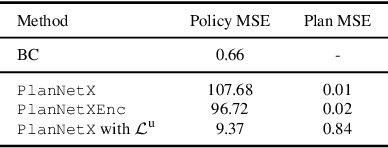
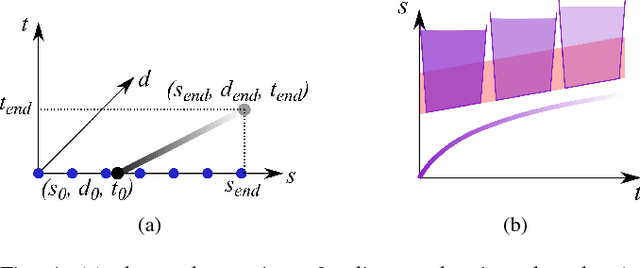
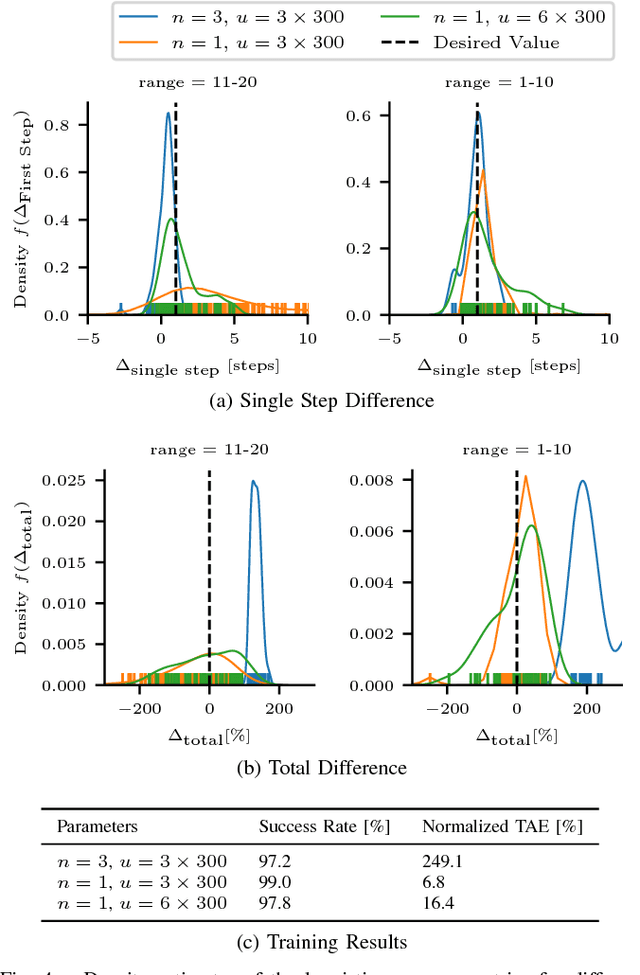
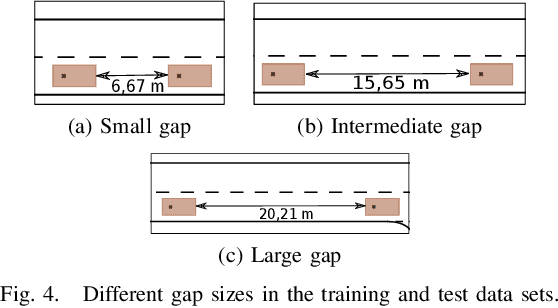
Model predictive control (MPC) is a powerful, optimization-based approach for controlling dynamical systems. However, the computational complexity of online optimization can be problematic on embedded devices. Especially, when we need to guarantee fixed control frequencies. Thus, previous work proposed to reduce the computational burden using imitation learning (IL) approximating the MPC policy by a neural network. In this work, we instead learn the whole planned trajectory of the MPC. We introduce a combination of a novel neural network architecture PlanNetX and a simple loss function based on the state trajectory that leverages the parameterized optimal control structure of the MPC. We validate our approach in the context of autonomous driving by learning a longitudinal planner and benchmarking it extensively in the CommonRoad simulator using synthetic scenarios and scenarios derived from real data. Our experimental results show that we can learn the open-loop MPC trajectory with high accuracy while improving the closed-loop performance of the learned control policy over other baselines like behavior cloning.
Spatiotemporal motion planning with combinatorial reasoning for autonomous driving
Jul 10, 2022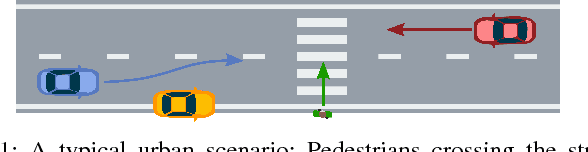
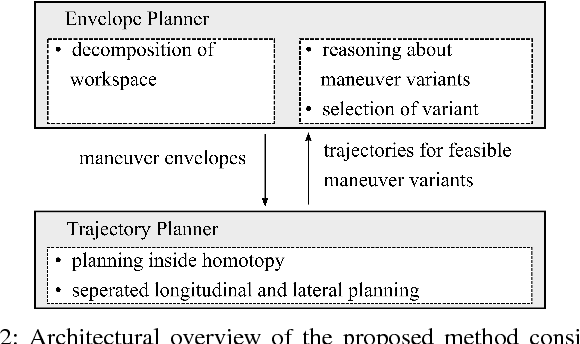
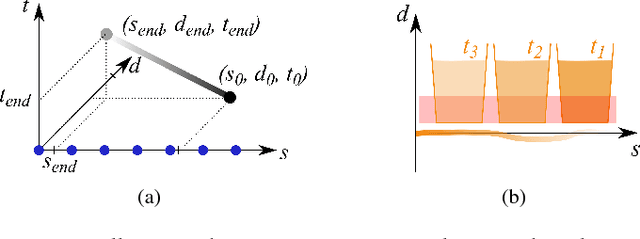
Motion planning for urban environments with numerous moving agents can be viewed as a combinatorial problem. With passing an obstacle before, after, right or left, there are multiple options an autonomous vehicle could choose to execute. These combinatorial aspects need to be taken into account in the planning framework. We address this problem by proposing a novel planning approach that combines trajectory planning and maneuver reasoning. We define a classification for dynamic obstacles along a reference curve that allows us to extract tactical decision sequences. We separate longitudinal and lateral movement to speed up the optimization-based trajectory planning. To map the set of obtained trajectories to maneuver variants, we define a semantic language to describe them. This allows us to choose an optimal trajectory while also ensuring maneuver consistency over time. We demonstrate the capabilities of our approach for a scenario that is still widely considered to be challenging.
Experience-Based Heuristic Search: Robust Motion Planning with Deep Q-Learning
Feb 05, 2021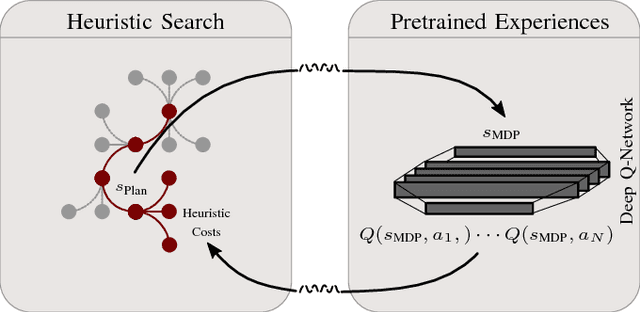
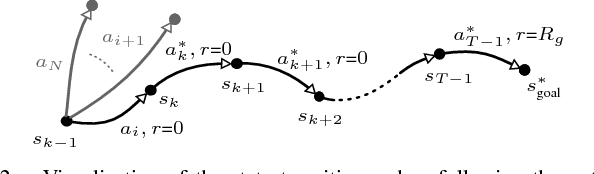
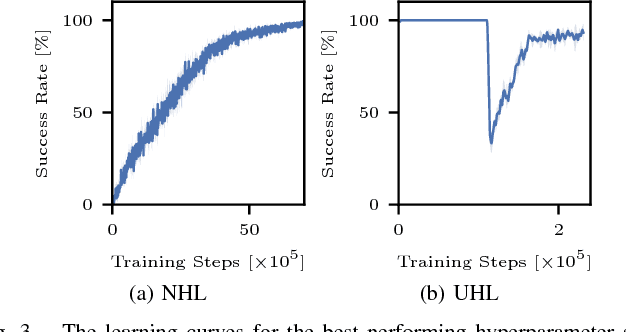
Interaction-aware planning for autonomous driving requires an exploration of a combinatorial solution space when using conventional search- or optimization-based motion planners. With Deep Reinforcement Learning, optimal driving strategies for such problems can be derived also for higher-dimensional problems. However, these methods guarantee optimality of the resulting policy only in a statistical sense, which impedes their usage in safety critical systems, such as autonomous vehicles. Thus, we propose the Experience-Based-Heuristic-Search algorithm, which overcomes the statistical failure rate of a Deep-reinforcement-learning-based planner and still benefits computationally from the pre-learned optimal policy. Specifically, we show how experiences in the form of a Deep Q-Network can be integrated as heuristic into a heuristic search algorithm. We benchmark our algorithm in the field of path planning in semi-structured valet parking scenarios. There, we analyze the accuracy of such estimates and demonstrate the computational advantages and robustness of our method. Our method may encourage further investigation of the applicability of reinforcement-learning-based planning in the field of self-driving vehicles.
Addressing Inherent Uncertainty: Risk-Sensitive Behavior Generation for Automated Driving using Distributional Reinforcement Learning
Feb 05, 2021


For highly automated driving above SAE level~3, behavior generation algorithms must reliably consider the inherent uncertainties of the traffic environment, e.g. arising from the variety of human driving styles. Such uncertainties can generate ambiguous decisions, requiring the algorithm to appropriately balance low-probability hazardous events, e.g. collisions, and high-probability beneficial events, e.g. quickly crossing the intersection. State-of-the-art behavior generation algorithms lack a distributional treatment of decision outcome. This impedes a proper risk evaluation in ambiguous situations, often encouraging either unsafe or conservative behavior. Thus, we propose a two-step approach for risk-sensitive behavior generation combining offline distribution learning with online risk assessment. Specifically, we first learn an optimal policy in an uncertain environment with Deep Distributional Reinforcement Learning. During execution, the optimal risk-sensitive action is selected by applying established risk criteria, such as the Conditional Value at Risk, to the learned state-action return distributions. In intersection crossing scenarios, we evaluate different risk criteria and demonstrate that our approach increases safety, while maintaining an active driving style. Our approach shall encourage further studies about the benefits of risk-sensitive approaches for self-driving vehicles.
Risk-Constrained Interactive Safety under Behavior Uncertainty for Autonomous Driving
Feb 05, 2021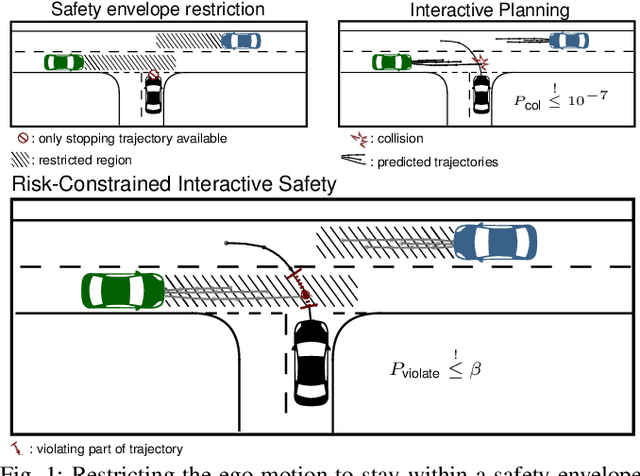
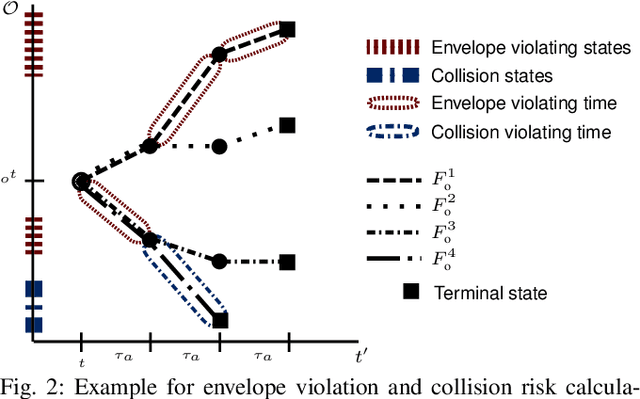

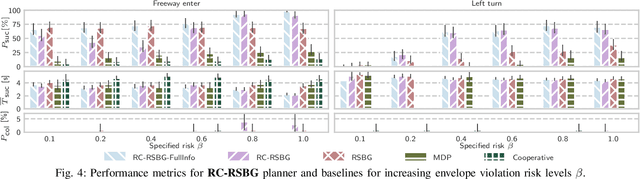
Balancing safety and efficiency when planning in dense traffic is challenging. Interactive behavior planners incorporate prediction uncertainty and interactivity inherent to these traffic situations. Yet, their use of single-objective optimality impedes interpretability of the resulting safety goal. Safety envelopes which restrict the allowed planning region yield interpretable safety under the presence of behavior uncertainty, yet, they sacrifice efficiency in dense traffic due to conservative driving. Studies show that humans balance safety and efficiency in dense traffic by accepting a probabilistic risk of violating the safety envelope. In this work, we adopt this safety objective for interactive planning. Specifically, we formalize this safety objective, present the Risk-Constrained Robust Stochastic Bayesian Game modeling interactive decisions satisfying a maximum risk of violating a safety envelope under uncertainty of other traffic participants' behavior and solve it using our variant of Multi-Agent Monte Carlo Tree Search. We demonstrate in simulation that our approach outperforms baselines approaches, and by reaching the specified violation risk level over driven simulation time, provides an interpretable and tunable safety objective for interactive planning.
Bridging the Gap between Open Source Software and Vehicle Hardware for Autonomous Driving
May 08, 2019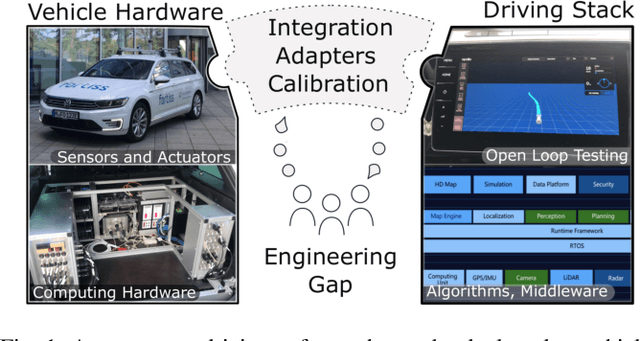



Although many research vehicle platforms for autonomous driving have been built in the past, hardware design, source code and lessons learned have not been made available for the next generation of demonstrators. This raises the efforts for the research community to contribute results based on real-world evaluations as engineering knowledge of building and maintaining a research vehicle is lost. In this paper, we deliver an analysis of our approach to transferring an open source driving stack to a research vehicle. We put the hardware and software setup in context to other demonstrators and explain the criteria that led to our chosen hardware and software design. Specifically, we discuss the mapping of the Apollo driving stack to the system layout of our research vehicle, fortuna, including communication with the actuators by a controller running on a real-time hardware platform and the integration of the sensor setup. With our collection of the lessons learned, we encourage a faster setup of such systems by other research groups in the future.