 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Search for Squawk: Agile Modeling in Bioacoustics
May 07, 2025Passive acoustic monitoring (PAM) has shown great promise in helping ecologists understand the health of animal populations and ecosystems. However, extracting insights from millions of hours of audio recordings requires the development of specialized recognizers. This is typically a challenging task, necessitating large amounts of training data and machine learning expertise. In this work, we introduce a general, scalable and data-efficient system for developing recognizers for novel bioacoustic problems in under an hour. Our system consists of several key components that tackle problems in previous bioacoustic workflows: 1) highly generalizable acoustic embeddings pre-trained for birdsong classification minimize data hunger; 2) indexed audio search allows the efficient creation of classifier training datasets, and 3) precomputation of embeddings enables an efficient active learning loop, improving classifier quality iteratively with minimal wait time. Ecologists employed our system in three novel case studies: analyzing coral reef health through unidentified sounds; identifying juvenile Hawaiian bird calls to quantify breeding success and improve endangered species monitoring; and Christmas Island bird occupancy modeling. We augment the case studies with simulated experiments which explore the range of design decisions in a structured way and help establish best practices. Altogether these experiments showcase our system's scalability, efficiency, and generalizability, enabling scientists to quickly address new bioacoustic challenges.
Spatiotemporal motion planning with combinatorial reasoning for autonomous driving
Jul 10, 2022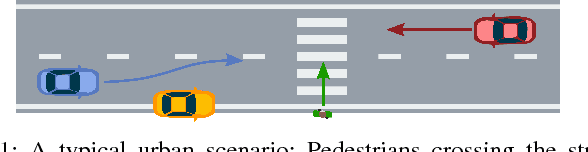
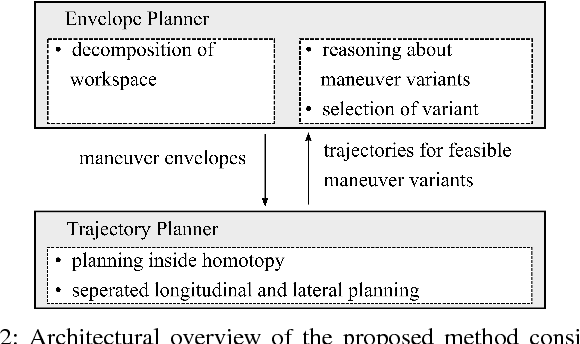
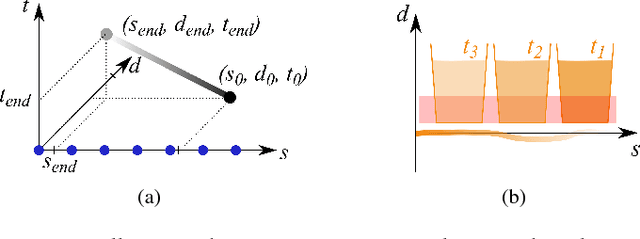
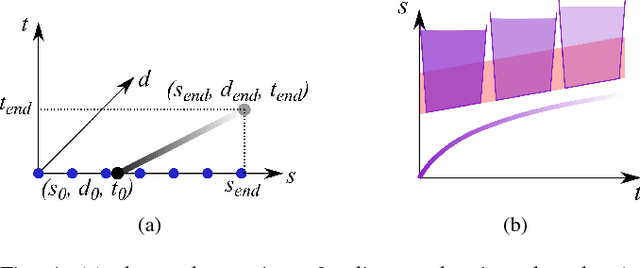
Motion planning for urban environments with numerous moving agents can be viewed as a combinatorial problem. With passing an obstacle before, after, right or left, there are multiple options an autonomous vehicle could choose to execute. These combinatorial aspects need to be taken into account in the planning framework. We address this problem by proposing a novel planning approach that combines trajectory planning and maneuver reasoning. We define a classification for dynamic obstacles along a reference curve that allows us to extract tactical decision sequences. We separate longitudinal and lateral movement to speed up the optimization-based trajectory planning. To map the set of obtained trajectories to maneuver variants, we define a semantic language to describe them. This allows us to choose an optimal trajectory while also ensuring maneuver consistency over time. We demonstrate the capabilities of our approach for a scenario that is still widely considered to be challenging.
Graph Neural Networks and Reinforcement Learning for Behavior Generation in Semantic Environments
Jun 22, 2020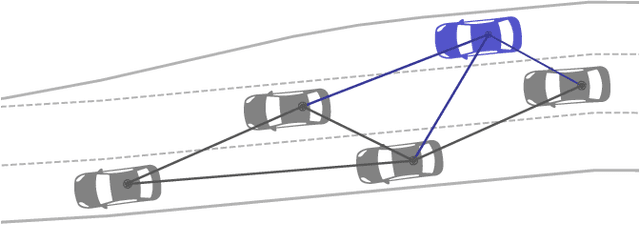
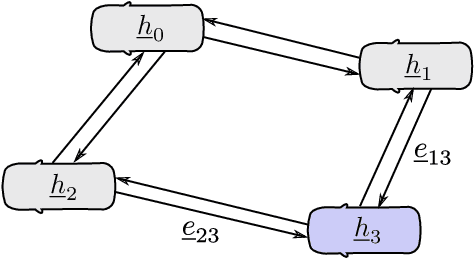
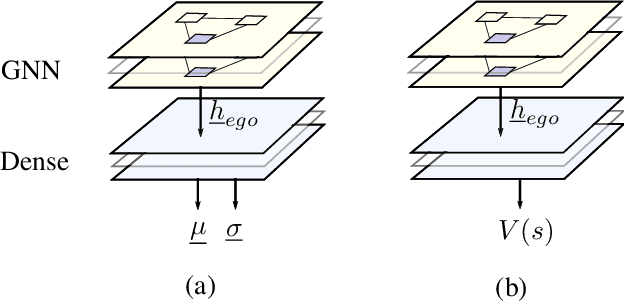
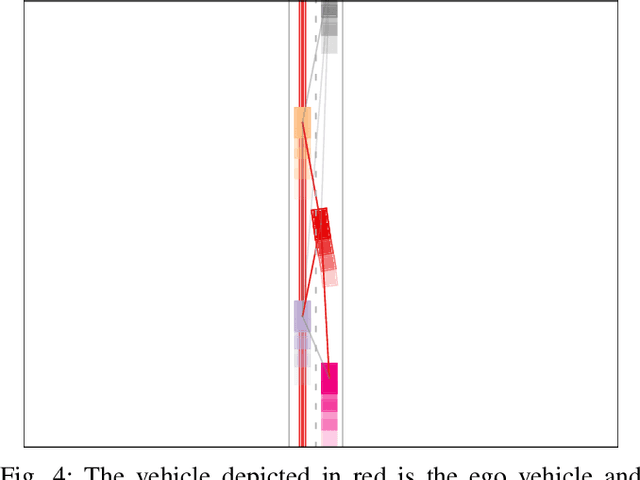
Most reinforcement learning approaches used in behavior generation utilize vectorial information as input. However, this requires the network to have a pre-defined input-size -- in semantic environments this means assuming the maximum number of vehicles. Additionally, this vectorial representation is not invariant to the order and number of vehicles. To mitigate the above-stated disadvantages, we propose combining graph neural networks with actor-critic reinforcement learning. As graph neural networks apply the same network to every vehicle and aggregate incoming edge information, they are invariant to the number and order of vehicles. This makes them ideal candidates to be used as networks in semantic environments -- environments consisting of objects lists. Graph neural networks exhibit some other advantages that make them favorable to be used in semantic environments. The relational information is explicitly given and does not have to be inferred. Moreover, graph neural networks propagate information through the network and can gather higher-degree information. We demonstrate our approach using a highway lane-change scenario and compare the performance of graph neural networks to conventional ones. We show that graph neural networks are capable of handling scenarios with a varying number and order of vehicles during training and application.
Using Counterfactual Reasoning and Reinforcement Learning for Decision-Making in Autonomous Driving
Mar 20, 2020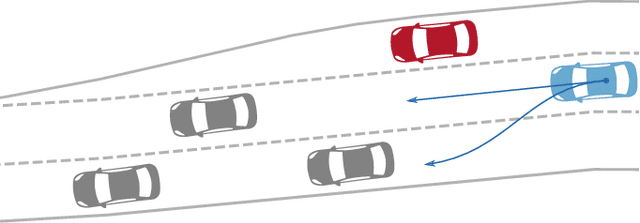
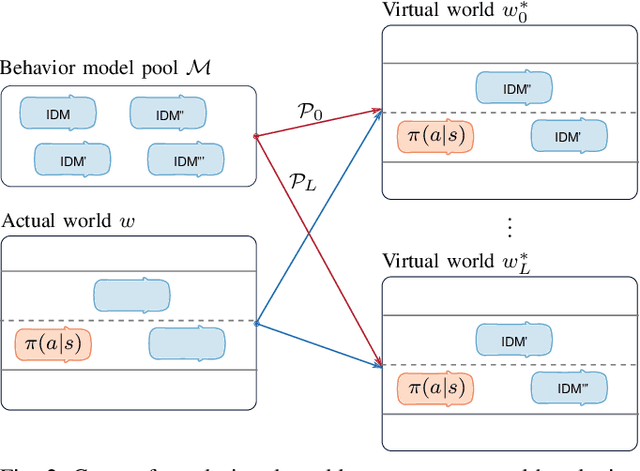
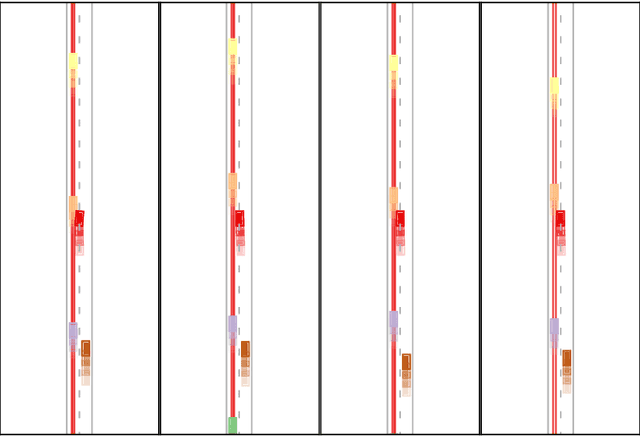
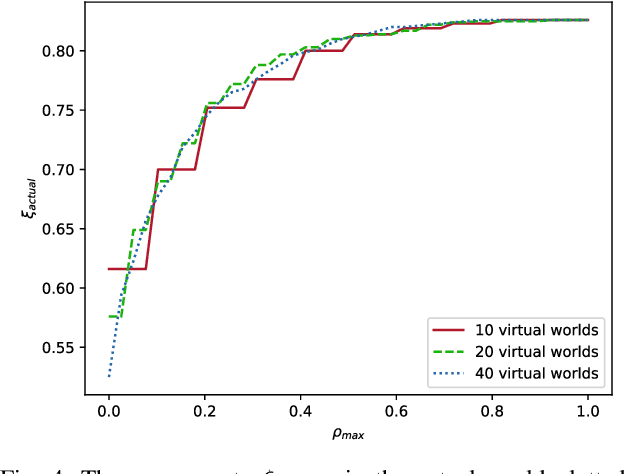
In decision-making for autonomous vehicles, we need to predict other vehicle's behaviors or learn their behavior implicitly using machine learning. However, often the predictions and learned models have errors or might be wrong altogether which can lead to dangerous situations. Therefore, decision-making algorithms should consider counterfactual reasoning such as: what would happen if the other agents will behave in a certain way? The approach we present in this paper is two-fold: First, during training, we randomly select behavior models from a behavior model pool and assign them to the other vehicles in the scenario, such as more passive or aggressive behavior models. Second, during the application, we derive several virtual worlds from the actual world that have the same initial state. In each of these worlds, we also assign behavior models from the behavior model pool to others. We then evolve these virtual worlds for a defined time-horizon. This enables us to apply counterfactual reasoning by asking what would happen if the actual world evolves as in the virtual world. In uncertain environments, this makes it possible to generate more probable risk estimates and, thus, to enable safer decision-making. We conduct studies using a lane-change scenario that shows the advantages of counterfactual reasoning using learned policies and virtual worlds to estimate their risk and performance.
Lane-Merging Using Policy-based Reinforcement Learning and Post-Optimization
Mar 06, 2020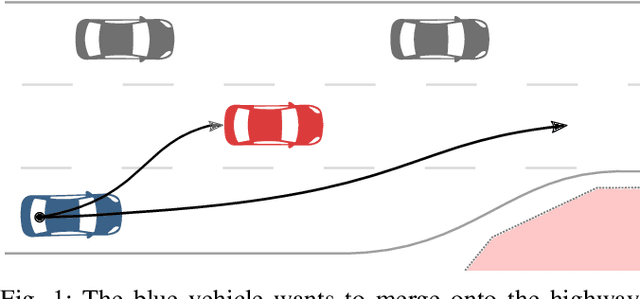
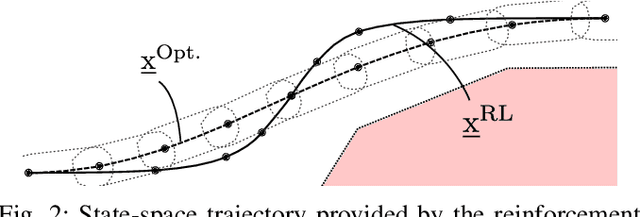
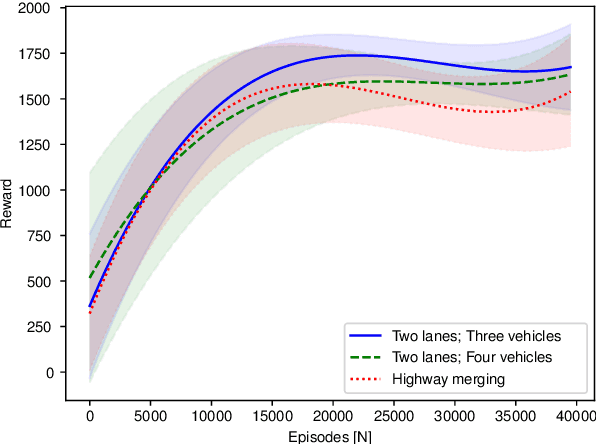
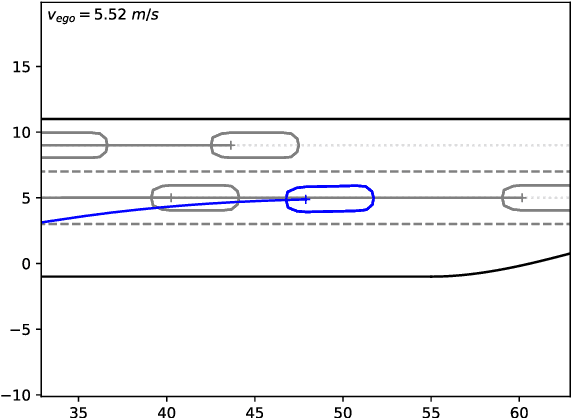
Many current behavior generation methods struggle to handle real-world traffic situations as they do not scale well with complexity. However, behaviors can be learned off-line using data-driven approaches. Especially, reinforcement learning is promising as it implicitly learns how to behave utilizing collected experiences. In this work, we combine policy-based reinforcement learning with local optimization to foster and synthesize the best of the two methodologies. The policy-based reinforcement learning algorithm provides an initial solution and guiding reference for the post-optimization. Therefore, the optimizer only has to compute a single homotopy class, e.g.\ drive behind or in front of the other vehicle. By storing the state-history during reinforcement learning, it can be used for constraint checking and the optimizer can account for interactions. The post-optimization additionally acts as a safety-layer and the novel method, thus, can be applied in safety-critical applications. We evaluate the proposed method using lane-change scenarios with a varying number of vehicles.
Bridging the Gap between Open Source Software and Vehicle Hardware for Autonomous Driving
May 08, 2019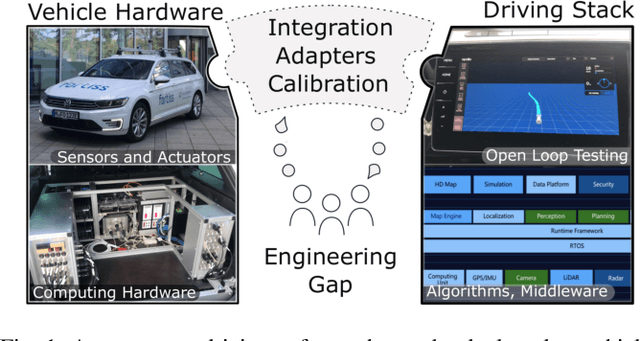



Although many research vehicle platforms for autonomous driving have been built in the past, hardware design, source code and lessons learned have not been made available for the next generation of demonstrators. This raises the efforts for the research community to contribute results based on real-world evaluations as engineering knowledge of building and maintaining a research vehicle is lost. In this paper, we deliver an analysis of our approach to transferring an open source driving stack to a research vehicle. We put the hardware and software setup in context to other demonstrators and explain the criteria that led to our chosen hardware and software design. Specifically, we discuss the mapping of the Apollo driving stack to the system layout of our research vehicle, fortuna, including communication with the actuators by a controller running on a real-time hardware platform and the integration of the sensor setup. With our collection of the lessons learned, we encourage a faster setup of such systems by other research groups in the future.