 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanNetX: Learning an Efficient Neural Network Planner from MPC for Longitudinal Control
Apr 29, 2024


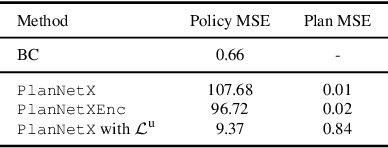
Model predictive control (MPC) is a powerful, optimization-based approach for controlling dynamical systems. However, the computational complexity of online optimization can be problematic on embedded devices. Especially, when we need to guarantee fixed control frequencies. Thus, previous work proposed to reduce the computational burden using imitation learning (IL) approximating the MPC policy by a neural network. In this work, we instead learn the whole planned trajectory of the MPC. We introduce a combination of a novel neural network architecture PlanNetX and a simple loss function based on the state trajectory that leverages the parameterized optimal control structure of the MPC. We validate our approach in the context of autonomous driving by learning a longitudinal planner and benchmarking it extensively in the CommonRoad simulator using synthetic scenarios and scenarios derived from real data. Our experimental results show that we can learn the open-loop MPC trajectory with high accuracy while improving the closed-loop performance of the learned control policy over other baselines like behavior cloning.
Spatiotemporal motion planning with combinatorial reasoning for autonomous driving
Jul 10, 2022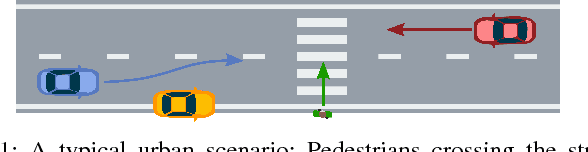
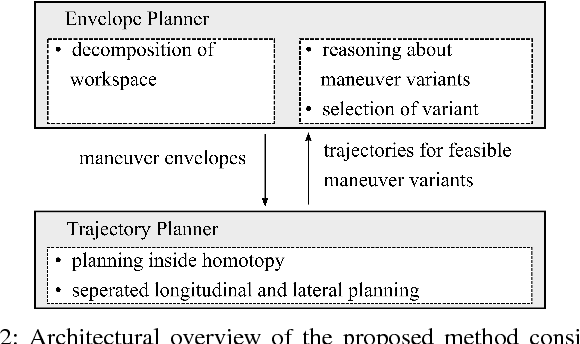
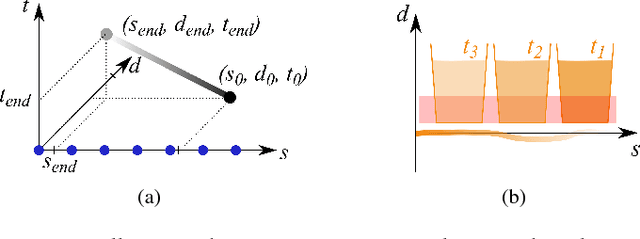
Motion planning for urban environments with numerous moving agents can be viewed as a combinatorial problem. With passing an obstacle before, after, right or left, there are multiple options an autonomous vehicle could choose to execute. These combinatorial aspects need to be taken into account in the planning framework. We address this problem by proposing a novel planning approach that combines trajectory planning and maneuver reasoning. We define a classification for dynamic obstacles along a reference curve that allows us to extract tactical decision sequences. We separate longitudinal and lateral movement to speed up the optimization-based trajectory planning. To map the set of obtained trajectories to maneuver variants, we define a semantic language to describe them. This allows us to choose an optimal trajectory while also ensuring maneuver consistency over time. We demonstrate the capabilities of our approach for a scenario that is still widely considered to be challenging.
Linear Differential Games for Cooperative Behavior Planning of Autonomous Vehicles Using Mixed-Integer Programming
Sep 30, 2021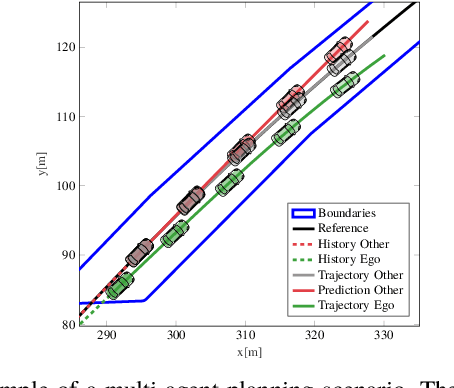



Cooperatively planning for multiple agents has been proposed as a promising method for strategic and motion planning for automated vehicles. By taking into account the intent of every agent, the ego agent can incorporate future interactions with human-driven vehicles into its planning. The problem is often formulated as a multi-agent game and solved using iterative algorithms operating on a discretized action or state space. Even if converging to a Nash equilibrium, the result will often be only sub-optimal. In this paper, we define a linear differential game for a set of interacting agents and solve it to optimality using mixed-integer programming. A disjunctive formulation of the orientation allows us to formulate linear constraints to prevent agent-to-agent collision while preserving the non-holonomic motion properties of the vehicle model. Soft constraints account for prediction errors. We then define a joint cost function, where a cooperation factor can adapt between altruistic, cooperative, and egoistic behavior. We study the influence of the cooperation factor to solve scenarios, where interaction between the agents is necessary to solve them successfully. The approach is then evaluated in a racing scenario, where we show the applicability of the formulation in a closed-loop receding horizon replanning fashion. By accounting for inaccuracies in the cooperative assumption and the actual behavior, we can indeed successfully plan an optimal control strategy interacting closely with other agents.
Experience-Based Heuristic Search: Robust Motion Planning with Deep Q-Learning
Feb 05, 2021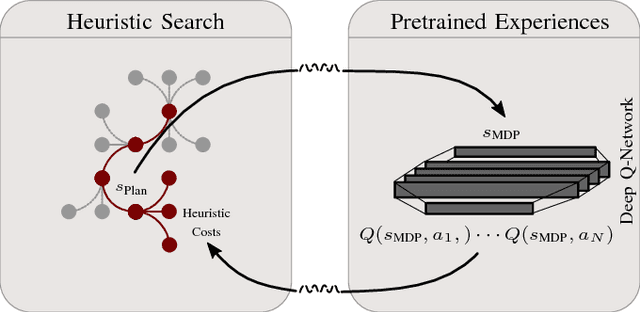
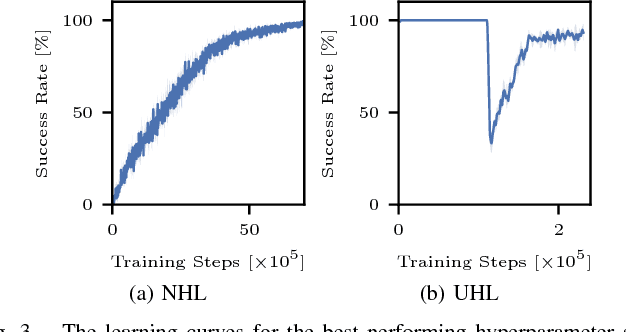
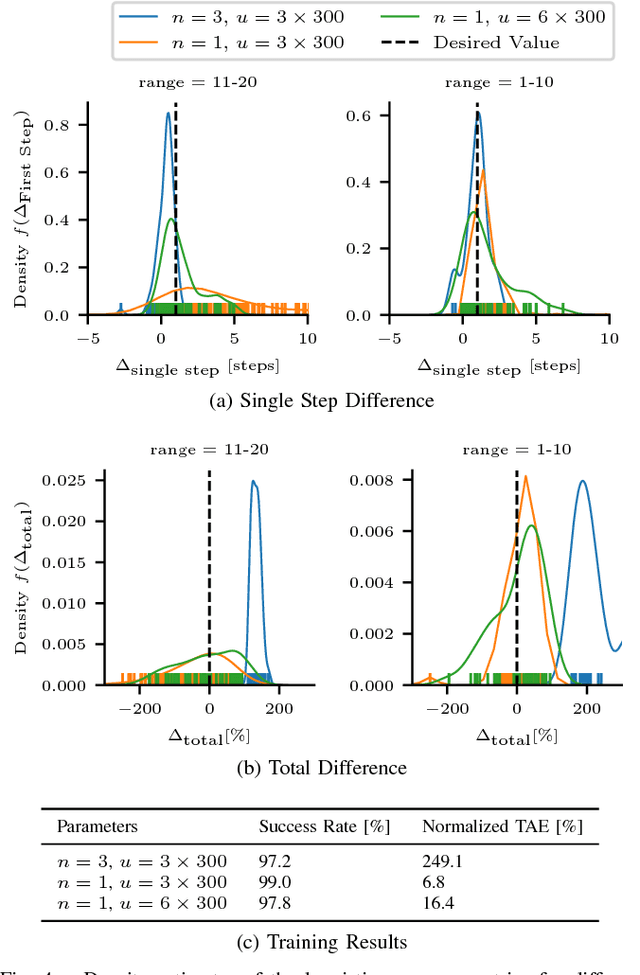
Interaction-aware planning for autonomous driving requires an exploration of a combinatorial solution space when using conventional search- or optimization-based motion planners. With Deep Reinforcement Learning, optimal driving strategies for such problems can be derived also for higher-dimensional problems. However, these methods guarantee optimality of the resulting policy only in a statistical sense, which impedes their usage in safety critical systems, such as autonomous vehicles. Thus, we propose the Experience-Based-Heuristic-Search algorithm, which overcomes the statistical failure rate of a Deep-reinforcement-learning-based planner and still benefits computationally from the pre-learned optimal policy. Specifically, we show how experiences in the form of a Deep Q-Network can be integrated as heuristic into a heuristic search algorithm. We benchmark our algorithm in the field of path planning in semi-structured valet parking scenarios. There, we analyze the accuracy of such estimates and demonstrate the computational advantages and robustness of our method. Our method may encourage further investigation of the applicability of reinforcement-learning-based planning in the field of self-driving vehicles.
Modeling and Testing Multi-Agent Traffic Rules within Interactive Behavior Planning
Sep 29, 2020Autonomous vehicles need to abide by the same rules that humans follow. Some of these traffic rules may depend on multiple agents or time. Especially in situations with traffic participants that interact densely, the interactions with other agents need to be accounted for during planning. To study how multi-agent and time-dependent traffic rules shall be modeled, a framework is needed that restricts the behavior to rule-conformant actions during planning, and that can eventually evaluate the satisfaction of these rules. This work presents a method to model the conformance to traffic rules for interactive behavior planning and to test the ramifications of the traffic rule formulations on metrics such as collision, progress, or rule violations. The interactive behavior planning problem is formulated as a dynamic game and solved using Monte Carlo Tree Search, for which we contribute a new method to integrate history-dependent traffic rules into a decision tree. To study the effect of the rules, we treat it as a multi-objective problem and apply a relaxed lexicographical ordering to the vectorized rewards. We demonstrate our approach in a merging scenario. We evaluate the effect of modeling and combining traffic rules to the eventual compliance in simulation. We show that with our approach, interactive behavior planning while satisfying even complex traffic rules can be achieved. Moving forward, this gives us a generic framework to formalize traffic rules for autonomous vehicles.
Formalizing Traffic Rules for Machine Interpretability
Jul 01, 2020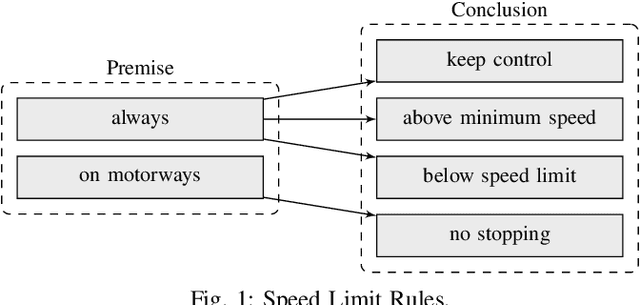
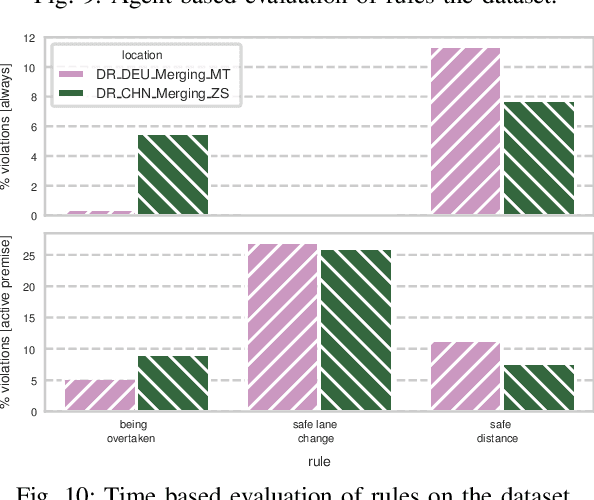
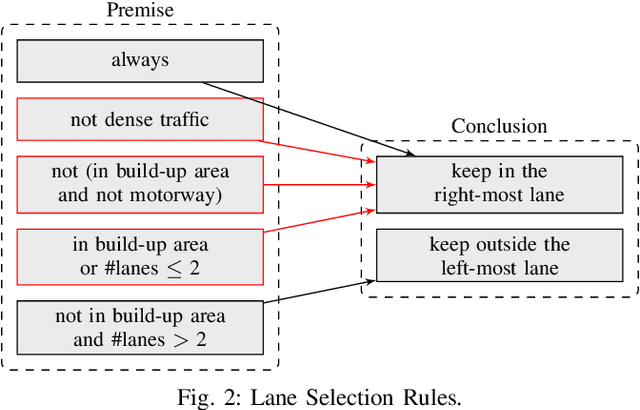
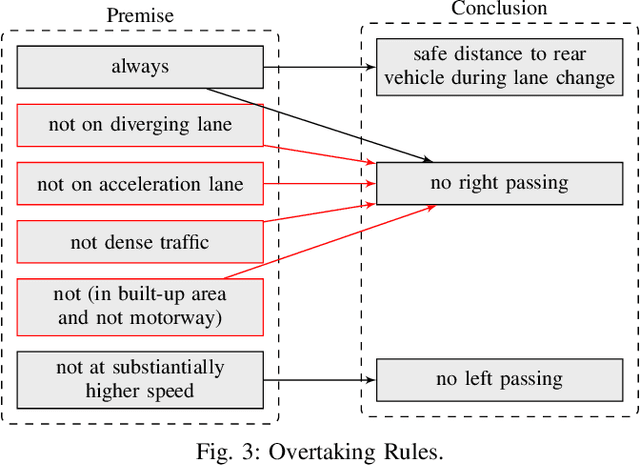
Autonomous vehicles need to be designed to abide by the same rules that humans follow. This is challenging, as traffic rules are fuzzy and not specified at a level of detail to be comprehensible for machines. Without proper formalization, satisfaction cannot be implemented in a planning component, nor can it be monitored and verified during simulation or testing. However, no work has provided a complete set of machine-interpretable traffic rules for a given operational driving domain. We propose a methodology on how to legally analyze and formalize traffic rules in a formal language. We use Linear Temporal Logic as a formal specification language to describe temporal behavior, thus capable of capturing a wide range of traffic rules. We contribute a formalized set of traffic rules for single-direction carriageways, such as on highways. We then test the effectiveness of our formalized rules on a public dataset.
Optimal Behavior Planning for Autonomous Driving: A Generic Mixed-Integer Formulation
Mar 30, 2020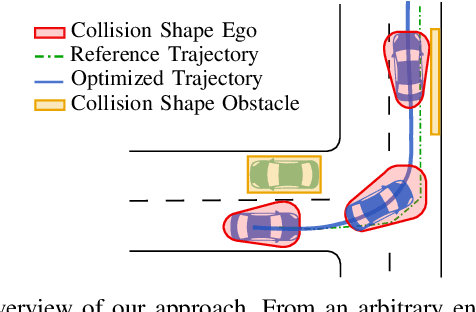
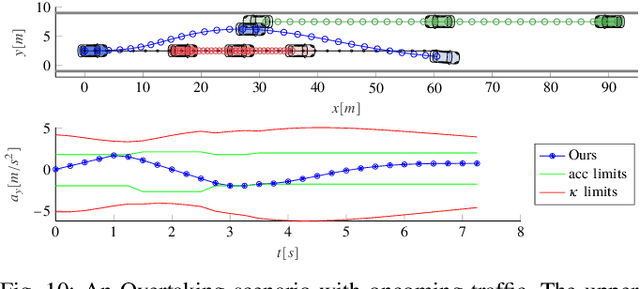
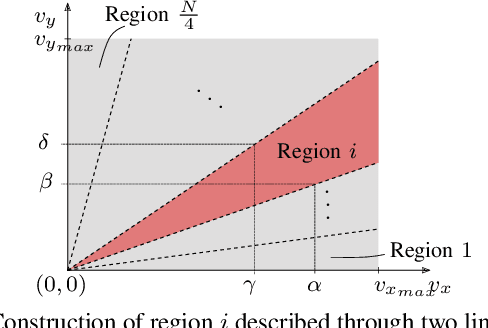
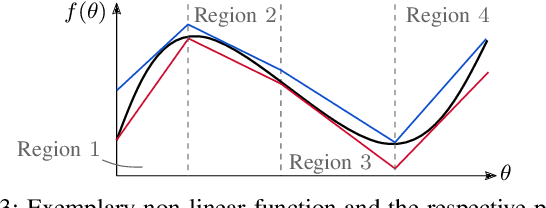
Mixed-Integer Quadratic Programming (MIQP) has been identified as a suitable approach for finding an optimal solution to the behavior planning problem with low runtimes. Logical constraints and continuous equations are optimized alongside. However, it has only been formulated for a straight road, omitting common situations such as taking turns at intersections. This has prevented the model from being used in reality so far. Based on a triple integrator model formulation, we compute the orientation of the vehicle and model it in a disjunctive manner. That allows us to formulate linear constraints to account for the non-holonomy and collision avoidance. These constraints are approximations, for which we introduce the theory. We show the applicability in two benchmark scenarios and prove the feasibility by solving the same models using nonlinear optimization. This new model will allow researchers to leverage the benefits of MIQP, such as logical constraints, or global optimality.
Bridging the Gap between Open Source Software and Vehicle Hardware for Autonomous Driving
May 08, 2019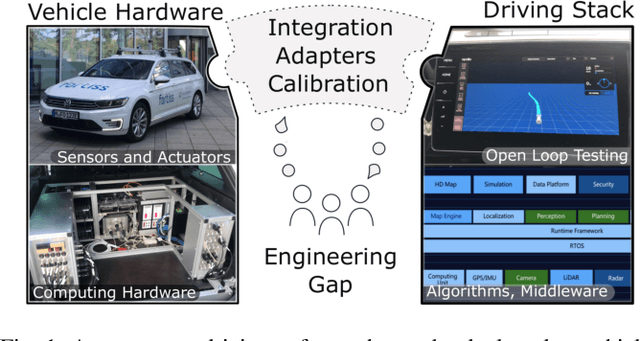



Although many research vehicle platforms for autonomous driving have been built in the past, hardware design, source code and lessons learned have not been made available for the next generation of demonstrators. This raises the efforts for the research community to contribute results based on real-world evaluations as engineering knowledge of building and maintaining a research vehicle is lost. In this paper, we deliver an analysis of our approach to transferring an open source driving stack to a research vehicle. We put the hardware and software setup in context to other demonstrators and explain the criteria that led to our chosen hardware and software design. Specifically, we discuss the mapping of the Apollo driving stack to the system layout of our research vehicle, fortuna, including communication with the actuators by a controller running on a real-time hardware platform and the integration of the sensor setup. With our collection of the lessons learned, we encourage a faster setup of such systems by other research groups in the future.
From Specifications to Behavior: Maneuver Verification in a Semantic State Space
May 02, 2019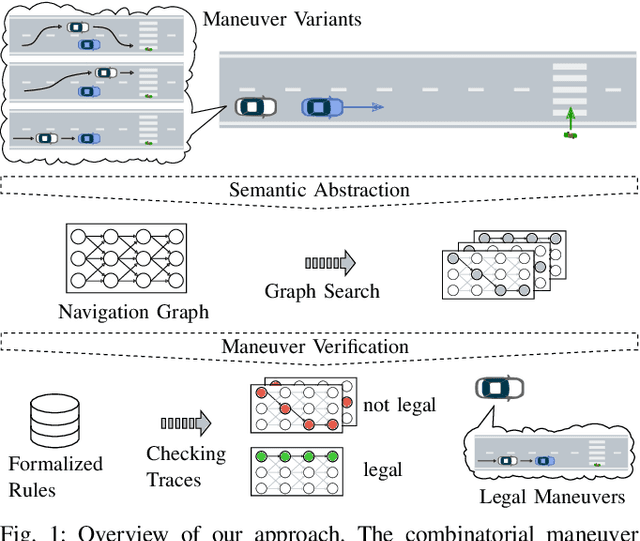
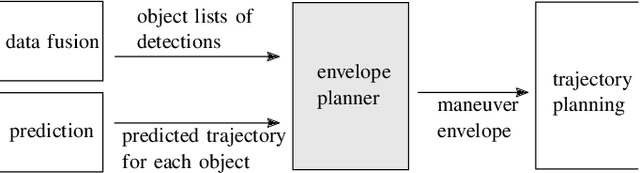

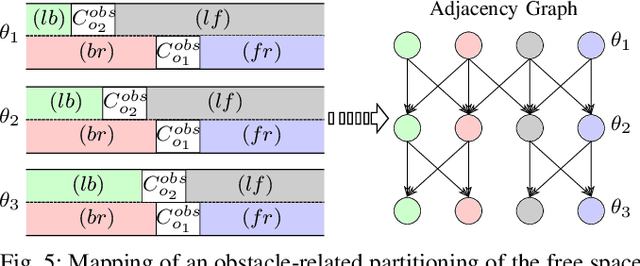
To realize a market entry of autonomous vehicles in the foreseeable future, the behavior planning system will need to abide by the same rules that humans follow. Product liability cannot be enforced without a proper solution to the approval trap. In this paper, we define a semantic abstraction of the continuous space and formalize traffic rules in linear temporal logic (LTL). Sequences in the semantic state space represent maneuvers a high-level planner could choose to execute. We check these maneuvers against the formalized traffic rules using runtime verification. By using the standard model checker NuSMV, we demonstrate the effectiveness of our approach and provide runtime properties for the maneuver verification. We show that high-level behavior can be verified in a semantic state space to fulfill a set of formalized rules, which could serve as a step towards safety of the intended functionality.