 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
Paper and Code
Jun 06, 2024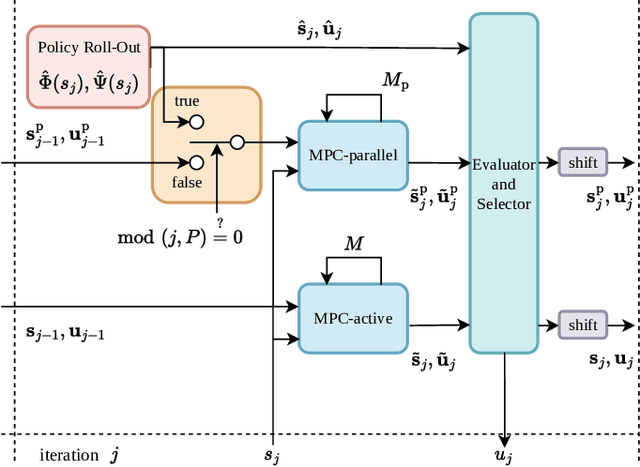
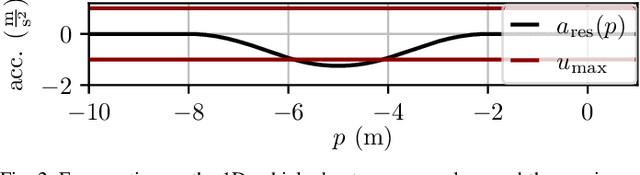
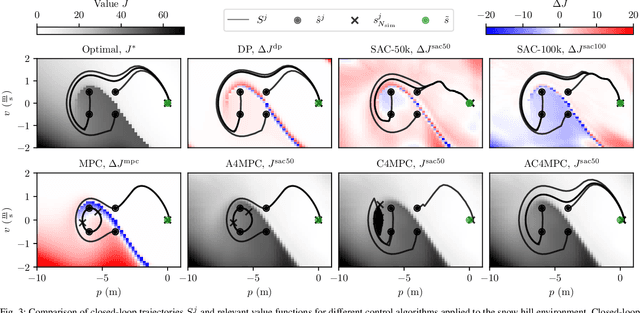
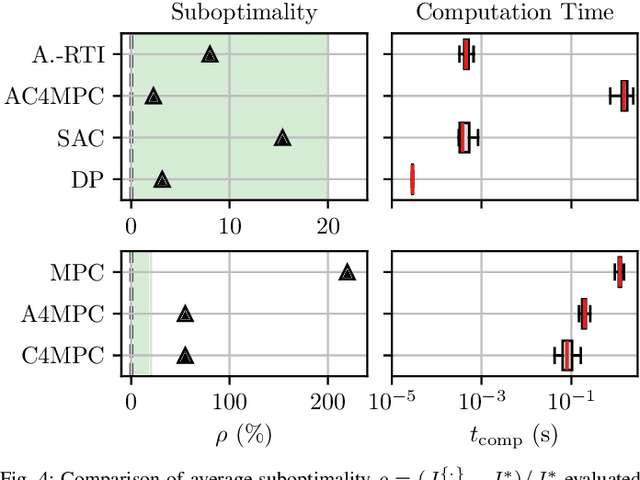
\Ac{MPC} and \ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic \ac{RL} techniques can be leveraged to improve the performance of \ac{MPC}. The \ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the \ac{MPC}. A parallel control architecture is proposed where each \ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original \ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the \ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an \ac{AD} overtaking scenario.