 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Classification for Detecting Parkinson's Disease from Wrist Motions
Apr 21, 2023



Parkinson's disease (PD) is a neurodegenerative disease with frequently changing motor symptoms where continuous symptom monitoring enables more targeted treatment. Classical time series classification (TSC) and deep learning techniques have limited performance for PD symptom monitoring using wearable accelerometer data because PD movement patterns are complex, but datasets are small. We investigate InceptionTime and RandOm Convolutional KErnel Transform (ROCKET) because they are state-of-the-art for TSC and promising for PD symptom monitoring: InceptionTime's high learning capacity is suited to modeling complex movement patterns while ROCKET is suited to small datasets. We used a random search to find the highest-scoring InceptionTime architecture and compared it to ROCKET with a ridge classifier and a multi-layer perceptron (MLP) on wrist motions of PD patients. We find that all approaches are suitable for estimating tremor severity and bradykinesia presence but struggle with detecting dyskinesia. ROCKET performs better for dyskinesia, whereas InceptionTime is slightly better for tremor and bradykinesia but has much higher variability in performance. Both outperform the MLP. In conclusion, both InceptionTime and ROCKET are suitable for continuous symptom monitoring, with the choice depending on the symptom of interest and desired robustness.
Safe Learning-Based Control of Elastic Joint Robots via Control Barrier Functions
Dec 01, 2022



Ensuring safety is of paramount importance in physical human-robot interaction applications. This requires both an adherence to safety constraints defined on the system state, as well as guaranteeing compliant behaviour of the robot. If the underlying dynamical system is known exactly, the former can be addressed with the help of control barrier functions. Incorporation of elastic actuators in the robot's mechanical design can address the latter requirement. However, this elasticity can increase the complexity of the resulting system, leading to unmodeled dynamics, such that control barrier functions cannot directly ensure safety. In this paper, we mitigate this issue by learning the unknown dynamics using Gaussian process regression. By employing the model in a feedback linearizing control law, the safety conditions resulting from control barrier functions can be robustified to take into account model errors, while remaining feasible. In order enforce them on-line, we formulate the derived safety conditions in the form of a second-order cone program. We demonstrate our proposed approach with simulations on a two-degree of freedom planar robot with elastic joints.
Learning Extended Body Schemas from Visual Keypoints for Object Manipulation
Nov 08, 2020
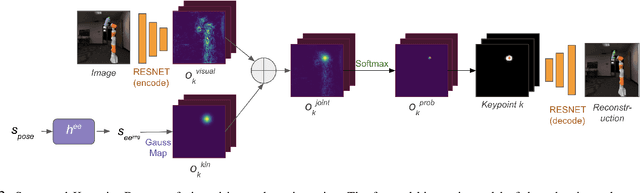
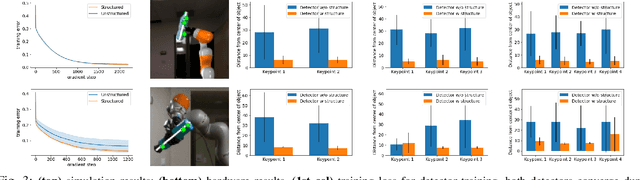

Humans have impressive generalization capabilities when it comes to manipulating objects and tools in completely novel environments. These capabilities are, at least partially, a result of humans having internal models of their bodies and any grasped object. How to learn such body schemas for robots remains an open problem. In this work, we develop an approach that can extend a robot's kinematic model when grasping an object from visual latent representations. Our framework comprises two components: 1) a structured keypoint detector, which fuses proprioception and vision to predict visual key points on an object; 2) Learning an adaptation of the kinematic chain by regressing virtual joints from the predicted key points. Our evaluation shows that our approach learns to consistently predict visual keypoints on objects, and can easily adapt a kinematic chain to the object grasped in various configurations, from a few seconds of data. Finally we show that this extended kinematic chain lends itself for object manipulation tasks such as placing a grasped object.
Model-Based Inverse Reinforcement Learning from Visual Demonstrations
Oct 18, 2020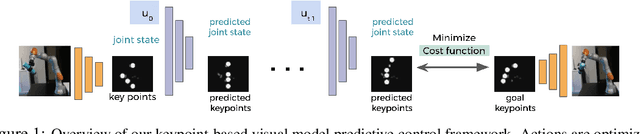
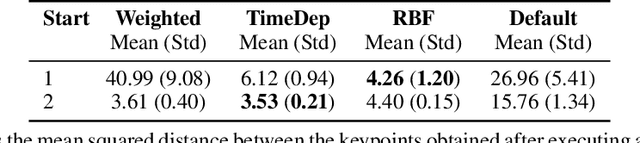
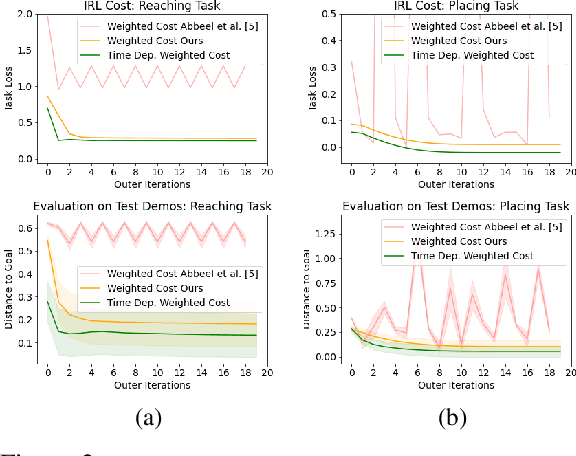

Scaling model-based inverse reinforcement learning (IRL) to real robotic manipulation tasks with unknown dynamics remains an open problem. The key challenges lie in learning good dynamics models, developing algorithms that scale to high-dimensional state-spaces and being able to learn from both visual and proprioceptive demonstrations. In this work, we present a gradient-based inverse reinforcement learning framework that utilizes a pre-trained visual dynamics model to learn cost functions when given only visual human demonstrations. The learned cost functions are then used to reproduce the demonstrated behavior via visual model predictive control. We evaluate our framework on hardware on two basic object manipulation tasks.
Learning State-Dependent Losses for Inverse Dynamics Learning
Mar 12, 2020
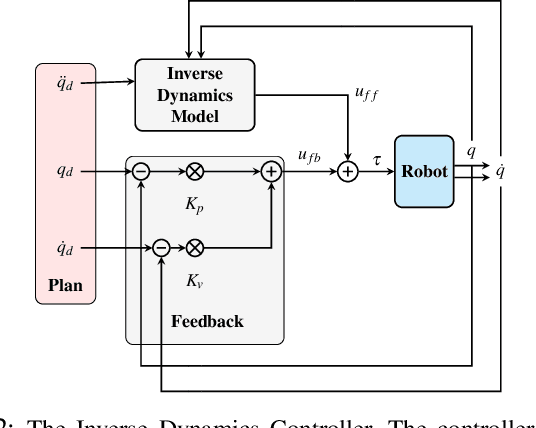

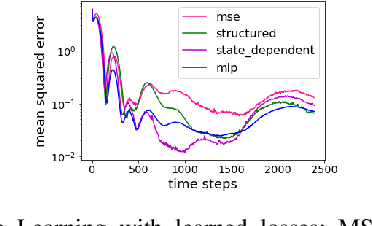
Being able to quickly adapt to changes in dynamics is paramount in model-based control for object manipulation tasks. In order to influence fast adaptation of the inverse dynamics model's parameters, data efficiency is crucial. Given observed data, a key element to how an optimizer updates model parameters is the loss function. In this work, we propose to apply meta-learning to learn structured, state-dependent loss functions during a meta-training phase. We then replace standard losses with our learned losses during online adaptation tasks. We evaluate our proposed approach on inverse dynamics learning tasks, both in simulation and on real hardware data. In both settings, the structured learned losses improve online adaptation speed, when compared to standard, state-independent loss functions.
Beta DVBF: Learning State-Space Models for Control from High Dimensional Observations
Nov 02, 2019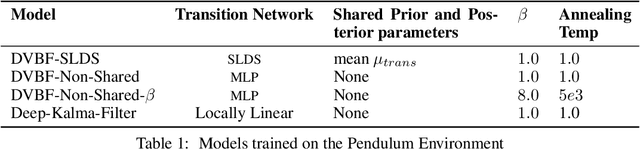
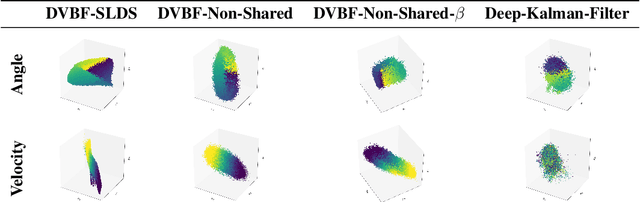
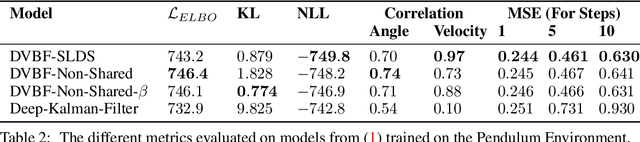
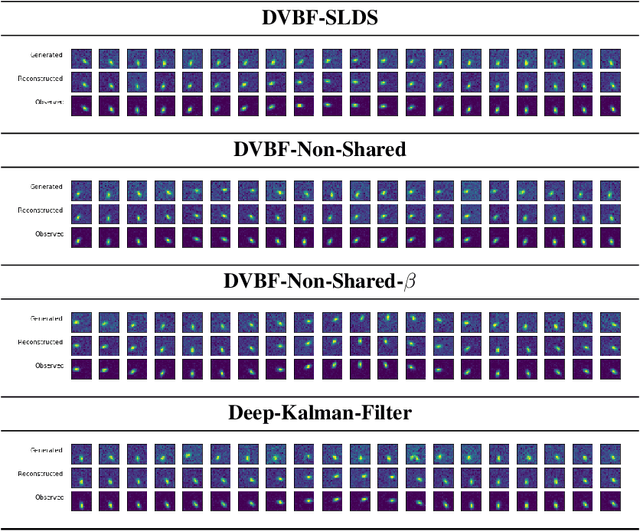
Learning a model of dynamics from high-dimensional images can be a core ingredient for success in many applications across different domains, especially in sequential decision making. However, currently prevailing methods based on latent-variable models are limited to working with low resolution images only. In this work, we show that some of the issues with using high-dimensional observations arise from the discrepancy between the dimensionality of the latent and observable space, and propose solutions to overcome them.