 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Extended Body Schemas from Visual Keypoints for Object Manipulation
Paper and Code
Nov 08, 2020
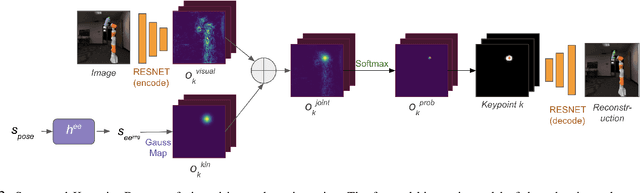
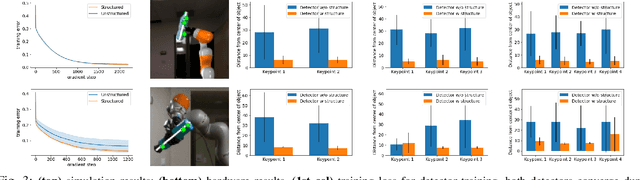

Humans have impressive generalization capabilities when it comes to manipulating objects and tools in completely novel environments. These capabilities are, at least partially, a result of humans having internal models of their bodies and any grasped object. How to learn such body schemas for robots remains an open problem. In this work, we develop an approach that can extend a robot's kinematic model when grasping an object from visual latent representations. Our framework comprises two components: 1) a structured keypoint detector, which fuses proprioception and vision to predict visual key points on an object; 2) Learning an adaptation of the kinematic chain by regressing virtual joints from the predicted key points. Our evaluation shows that our approach learns to consistently predict visual keypoints on objects, and can easily adapt a kinematic chain to the object grasped in various configurations, from a few seconds of data. Finally we show that this extended kinematic chain lends itself for object manipulation tasks such as placing a grasped object.