 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Action World Models for Control with Unlabeled Trajectories
Dec 10, 2025

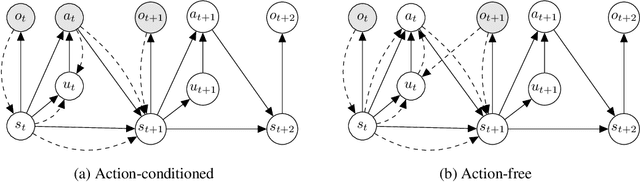

Inspired by how humans combine direct interaction with action-free experience (e.g., videos), we study world models that learn from heterogeneous data. Standard world models typically rely on action-conditioned trajectories, which limits effectiveness when action labels are scarce. We introduce a family of latent-action world models that jointly use action-conditioned and action-free data by learning a shared latent action representation. This latent space aligns observed control signals with actions inferred from passive observations, enabling a single dynamics model to train on large-scale unlabeled trajectories while requiring only a small set of action-labeled ones. We use the latent-action world model to learn a latent-action policy through offline reinforcement learning (RL), thereby bridging two traditionally separate domains: offline RL, which typically relies on action-conditioned data, and action-free training, which is rarely used with subsequent RL. On the DeepMind Control Suite, our approach achieves strong performance while using about an order of magnitude fewer action-labeled samples than purely action-conditioned baselines. These results show that latent actions enable training on both passive and interactive data, which makes world models learn more efficiently.
Overcoming Knowledge Barriers: Online Imitation Learning from Observation with Pretrained World Models
Apr 29, 2024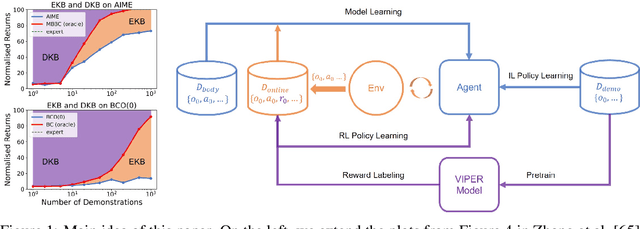
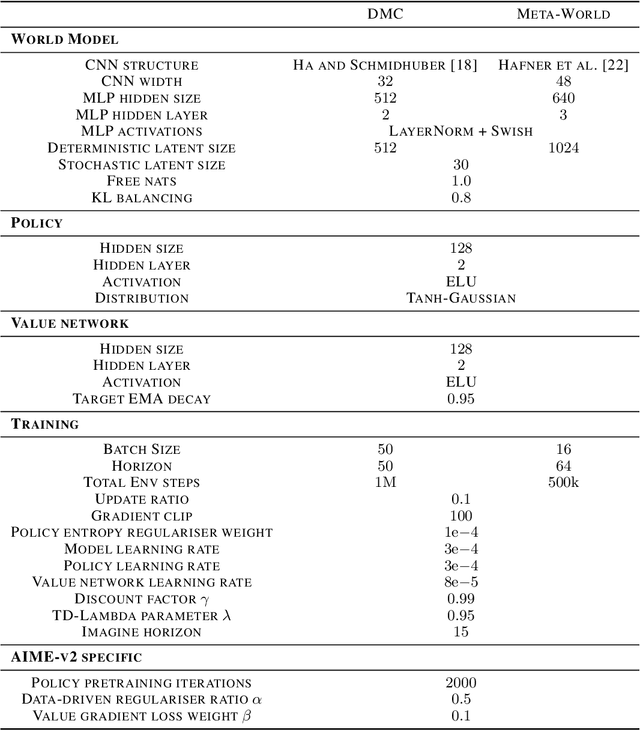
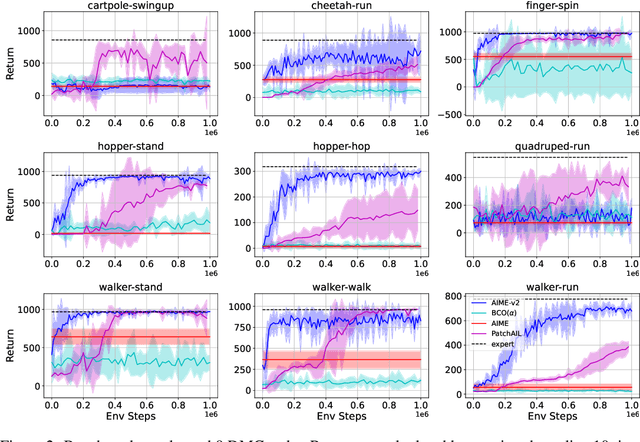
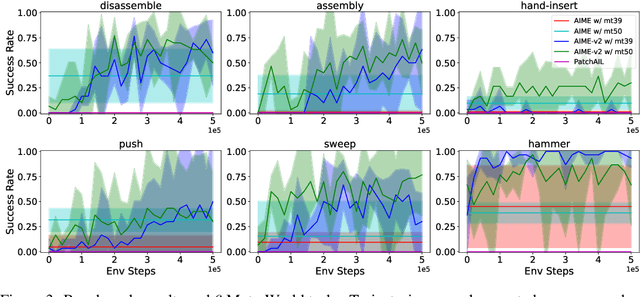
Incorporating the successful paradigm of pretraining and finetuning from Computer Vision and Natural Language Processing into decision-making has become increasingly popular in recent years. In this paper, we study Imitation Learning from Observation with pretrained models and find existing approaches such as BCO and AIME face knowledge barriers, specifically the Embodiment Knowledge Barrier (EKB) and the Demonstration Knowledge Barrier (DKB), greatly limiting their performance. The EKB arises when pretrained models lack knowledge about unseen observations, leading to errors in action inference. The DKB results from policies trained on limited demonstrations, hindering adaptability to diverse scenarios. We thoroughly analyse the underlying mechanism of these barriers and propose AIME-v2 upon AIME as a solution. AIME-v2 uses online interactions with data-driven regulariser to alleviate the EKB and mitigates the DKB by introducing a surrogate reward function to enhance policy training. Experimental results on tasks from the DeepMind Control Suite and Meta-World benchmarks demonstrate the effectiveness of these modifications in improving both sample-efficiency and converged performance. The study contributes valuable insights into resolving knowledge barriers for enhanced decision-making in pretraining-based approaches. Code will be available at https://github.com/argmax-ai/aime-v2.
Action Inference by Maximising Evidence: Zero-Shot Imitation from Observation with World Models
Dec 04, 2023Unlike most reinforcement learning agents which require an unrealistic amount of environment interactions to learn a new behaviour, humans excel at learning quickly by merely observing and imitating others. This ability highly depends on the fact that humans have a model of their own embodiment that allows them to infer the most likely actions that led to the observed behaviour. In this paper, we propose Action Inference by Maximising Evidence (AIME) to replicate this behaviour using world models. AIME consists of two distinct phases. In the first phase, the agent learns a world model from its past experience to understand its own body by maximising the ELBO. While in the second phase, the agent is given some observation-only demonstrations of an expert performing a novel task and tries to imitate the expert's behaviour. AIME achieves this by defining a policy as an inference model and maximising the evidence of the demonstration under the policy and world model. Our method is "zero-shot" in the sense that it does not require further training for the world model or online interactions with the environment after given the demonstration. We empirically validate the zero-shot imitation performance of our method on the Walker and Cheetah embodiment of the DeepMind Control Suite and find it outperforms the state-of-the-art baselines. Code is available at: https://github.com/argmax-ai/aime.
NeoRL: A Near Real-World Benchmark for Offline Reinforcement Learning
Feb 08, 2021
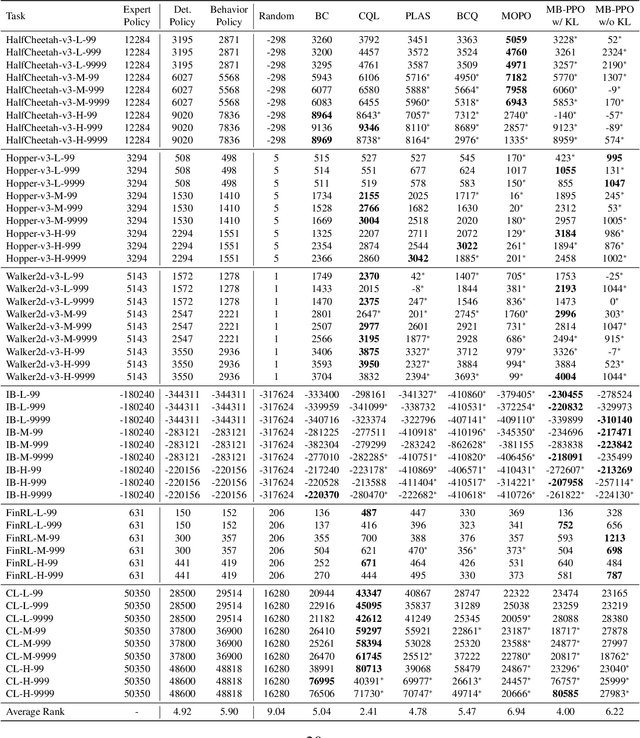

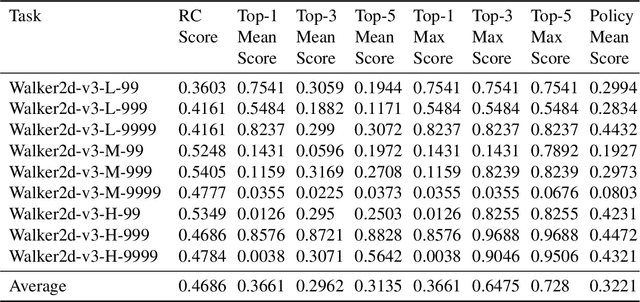
Offline reinforcement learning (RL) aims at learning a good policy from a batch of collected data, without extra interactions with the environment during training. However, current offline RL benchmarks commonly have a large reality gap, because they involve large datasets collected by highly exploratory policies, and the trained policy is directly evaluated in the environment. In real-world situations, running a highly exploratory policy is prohibited to ensure system safety, the data is commonly very limited, and a trained policy should be well validated before deployment. In this paper, we present a near real-world offline RL benchmark, named NeoRL, which contains datasets from various domains with controlled sizes, and extra test datasets for policy validation. We evaluate existing offline RL algorithms on NeoRL and argue that the performance of a policy should also be compared with the deterministic version of the behavior policy, instead of the dataset reward. The empirical results demonstrate that the tested offline RL algorithms become less competitive to the deterministic policy on many datasets, and the offline policy evaluation hardly helps. The NeoRL suit can be found at http://polixir.ai/research/neorl. We hope this work will shed some light on future research and draw more attention when deploying RL in real-world systems.
Classification-driven Single Image Dehazing
Nov 21, 2019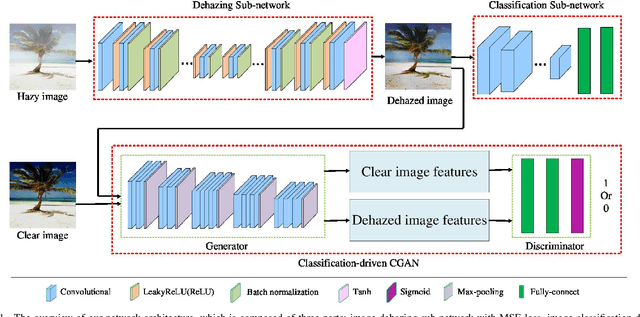



Most existing dehazing algorithms often use hand-crafted features or Convolutional Neural Networks (CNN)-based methods to generate clear images using pixel-level Mean Square Error (MSE) loss. The generated images generally have better visual appeal, but not always have better performance for high-level vision tasks, e.g. image classification. In this paper, we investigate a new point of view in addressing this problem. Instead of focusing only on achieving good quantitative performance on pixel-based metrics such as Peak Signal to Noise Ratio (PSNR), we also ensure that the dehazed image itself does not degrade the performance of the high-level vision tasks such as image classification. To this end, we present an unified CNN architecture that includes three parts: a dehazing sub-network (DNet), a classification-driven Conditional Generative Adversarial Networks sub-network (CCGAN) and a classification sub-network (CNet) related to image classification, which has better performance both on visual appeal and image classification. We conduct comprehensive experiments on two challenging benchmark datasets for fine-grained and object classification: CUB-200-2011 and Caltech-256. Experimental results demonstrate that the proposed method outperforms many recent state-of-the-art single image dehazing methods in terms of image dehazing metrics and classification accuracy.
Pixel-wise Regression: 3D Hand Pose Estimation via Spatial-form Representation and Differentiable Decoder
May 27, 2019


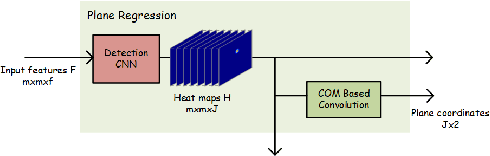
3D Hand pose estimation from a single depth image is an essential topic in computer vision and human-computer interaction. Although the rising of deep learning method boosts the accuracy a lot, the problem is still hard to solve due to the complex structure of the human hand. Existing methods with deep learning either lose spatial information of hand structure or lack a direct supervision of joint coordinates. In this paper, we propose a novel Pixel-wise Regression method, which use spatial-form representation (SFR) and differentiable decoder (DD) to solve the two problems. To use our method, we build a model, in which we design a particular SFR and its correlative DD which divided the 3D joint coordinates into two parts, plane coordinates and depth coordinates and use two modules named Plane Regression (PR) and Depth Regression (DR) to deal with them respectively. We conduct an ablation experiment to show the method we proposed achieve better results than the former methods. We also make an exploration on how different training strategies influence the learned SFRs and results. The experiment on three public datasets demonstrates that our model is comparable with the existing state-of-the-art models and in one of them our model can reduce mean 3D joint error by 25%.
Effects of Image Degradations to CNN-based Image Classification
Oct 12, 2018

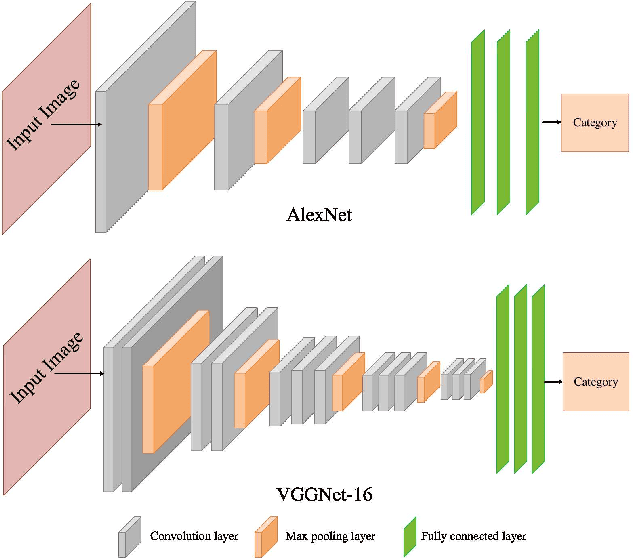

Just like many other topics in computer vision, image classification has achieved significant progress recently by using deep-learning neural networks, especially the Convolutional Neural Networks (CNN). Most of the existing works are focused on classifying very clear natural images, evidenced by the widely used image databases such as Caltech-256, PASCAL VOCs and ImageNet. However, in many real applications, the acquired images may contain certain degradations that lead to various kinds of blurring, noise, and distortions. One important and interesting problem is the effect of such degradations to the performance of CNN-based image classification. More specifically, we wonder whether image-classification performance drops with each kind of degradation, whether this drop can be avoided by including degraded images into training, and whether existing computer vision algorithms that attempt to remove such degradations can help improve the image-classification performance. In this paper, we empirically study this problem for four kinds of degraded images -- hazy images, underwater images, motion-blurred images and fish-eye images. For this study, we synthesize a large number of such degraded images by applying respective physical models to the clear natural images and collect a new hazy image dataset from the Internet. We expect this work can draw more interests from the community to study the classification of degraded images.