 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-wise Regression: 3D Hand Pose Estimation via Spatial-form Representation and Differentiable Decoder
Paper and Code



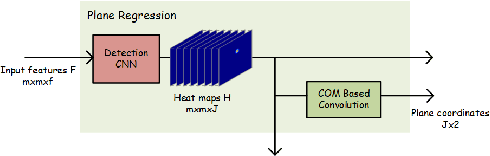
3D Hand pose estimation from a single depth image is an essential topic in computer vision and human-computer interaction. Although the rising of deep learning method boosts the accuracy a lot, the problem is still hard to solve due to the complex structure of the human hand. Existing methods with deep learning either lose spatial information of hand structure or lack a direct supervision of joint coordinates. In this paper, we propose a novel Pixel-wise Regression method, which use spatial-form representation (SFR) and differentiable decoder (DD) to solve the two problems. To use our method, we build a model, in which we design a particular SFR and its correlative DD which divided the 3D joint coordinates into two parts, plane coordinates and depth coordinates and use two modules named Plane Regression (PR) and Depth Regression (DR) to deal with them respectively. We conduct an ablation experiment to show the method we proposed achieve better results than the former methods. We also make an exploration on how different training strategies influence the learned SFRs and results. The experiment on three public datasets demonstrates that our model is comparable with the existing state-of-the-art models and in one of them our model can reduce mean 3D joint error by 25%.