 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking and Planning with Spatial World Models
Paper and Code


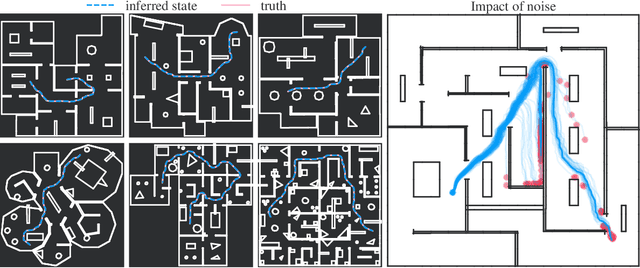

We introduce a method for real-time navigation and tracking with differentiably rendered world models. Learning models for control has led to impressive results in robotics and computer games, but this success has yet to be extended to vision-based navigation. To address this, we transfer advances in the emergent field of differentiable rendering to model-based control. We do this by planning in a learned 3D spatial world model, combined with a pose estimation algorithm previously used in the context of TSDF fusion, but now tailored to our setting and improved to incorporate agent dynamics. We evaluate over six simulated environments based on complex human-designed floor plans and provide quantitative results. We achieve up to 92% navigation success rate at a frequency of 15 Hz using only image and depth observations under stochastic, continuous dynamics.