 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Analysis of Bootstrap Ensemble Classifiers
May 20, 2025Bootstrap methods have long been a cornerstone of ensemble learning in machine learning. This paper presents a theoretical analysis of bootstrap techniques applied to the Least Square Support Vector Machine (LSSVM) ensemble in the context of large and growing sample sizes and feature dimensionalities. Leveraging tools from Random Matrix Theory, we investigate the performance of this classifier that aggregates decision functions from multiple weak classifiers, each trained on different subsets of the data. We provide insights into the use of bootstrap methods in high-dimensional settings, enhancing our understanding of their impact. Based on these findings, we propose strategies to select the number of subsets and the regularization parameter that maximize the performance of the LSSVM. Empirical experiments on synthetic and real-world datasets validate our theoretical results.
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Nov 05, 2024



We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimise, and generalise across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience. It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks. It optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards. This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent's apabilities using Kaggle competitions as a case study. Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0's end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL. Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users. Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle's progression system.
A systematic study comparing hyperparameter optimization engines on tabular data
Nov 27, 2023We run an independent comparison of all hyperparameter optimization (hyperopt) engines available in the Ray Tune library. We introduce two ways to normalize and aggregate statistics across data sets and models, one rank-based, and another one sandwiching the score between the random search score and the full grid search score. This affords us i) to rank the hyperopt engines, ii) to make generalized and statistically significant statements on how much they improve over random search, and iii) to make recommendations on which engine should be used to hyperopt a given learning algorithm. We find that most engines beat random search, but that only three of them (HEBO, AX, and BlendSearch) clearly stand out. We also found that some engines seem to specialize in hyperopting certain learning algorithms, which makes it tricky to use hyperopt in comparison studies, since the choice of the hyperopt technique may favor some of the models in the comparison.
Fast classification using sparse decision DAGs
Jun 27, 2012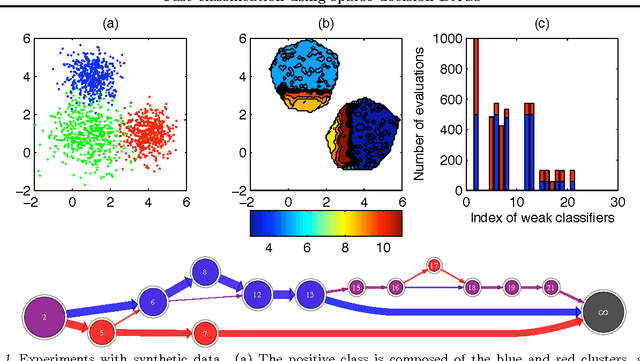
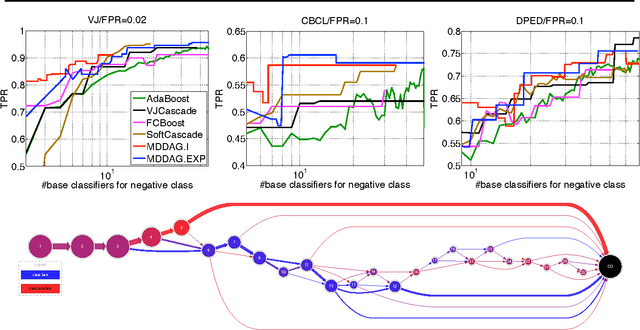
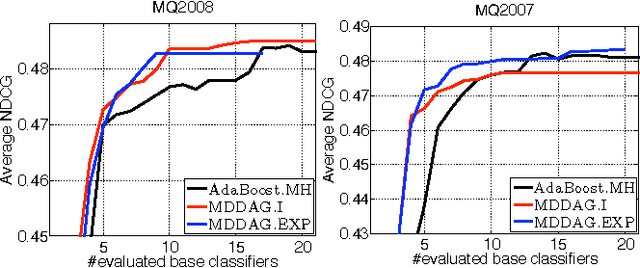
In this paper we propose an algorithm that builds sparse decision DAGs (directed acyclic graphs) from a list of base classifiers provided by an external learning method such as AdaBoost. The basic idea is to cast the DAG design task as a Markov decision process. Each instance can decide to use or to skip each base classifier, based on the current state of the classifier being built. The result is a sparse decision DAG where the base classifiers are selected in a data-dependent way. The method has a single hyperparameter with a clear semantics of controlling the accuracy/speed trade-off. The algorithm is competitive with state-of-the-art cascade detectors on three object-detection benchmarks, and it clearly outperforms them when there is a small number of base classifiers. Unlike cascades, it is also readily applicable for multi-class classification. Using the multi-class setup, we show on a benchmark web page ranking data set that we can significantly improve the decision speed without harming the performance of the ranker.