 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open Knowledge Graph-Based Approach for Mapping Concepts and Requirements between the EU AI Act and International Standards
Aug 21, 2024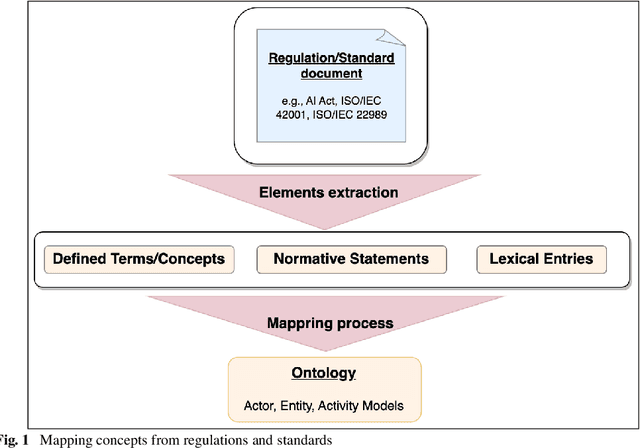
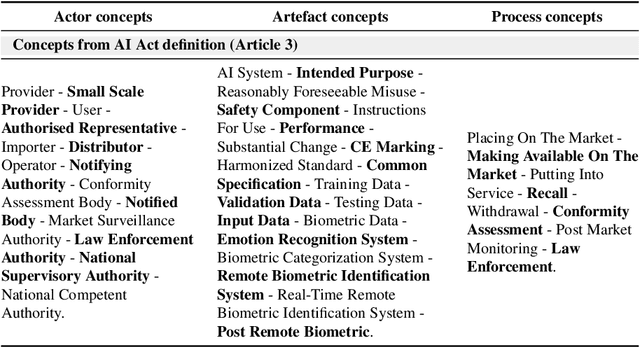
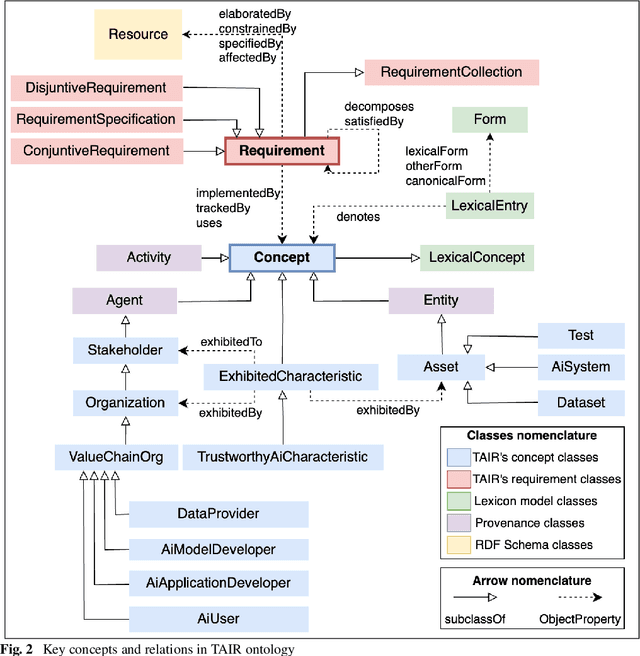
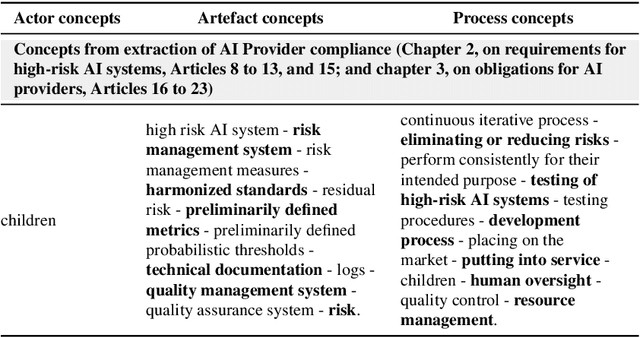
The many initiatives on trustworthy AI result in a confusing and multipolar landscape that organizations operating within the fluid and complex international value chains must navigate in pursuing trustworthy AI. The EU's AI Act will now shift the focus of such organizations toward conformance with the technical requirements for regulatory compliance, for which the Act relies on Harmonized Standards. Though a high-level mapping to the Act's requirements will be part of such harmonization, determining the degree to which standards conformity delivers regulatory compliance with the AI Act remains a complex challenge. Variance and gaps in the definitions of concepts and how they are used in requirements between the Act and harmonized standards may impact the consistency of compliance claims across organizations, sectors, and applications. This may present regulatory uncertainty, especially for SMEs and public sector bodies relying on standards conformance rather than proprietary equivalents for developing and deploying compliant high-risk AI systems. To address this challenge, this paper offers a simple and repeatable mechanism for mapping the terms and requirements relevant to normative statements in regulations and standards, e.g., AI Act and ISO management system standards, texts into open knowledge graphs. This representation is used to assess the adequacy of standards conformance to regulatory compliance and thereby provide a basis for identifying areas where further technical consensus development in trustworthy AI value chains is required to achieve regulatory compliance.
A Collaborative, Human-Centred Taxonomy of AI, Algorithmic, and Automation Harms
Jul 01, 2024This paper introduces a collaborative, human-centered taxonomy of AI, algorithmic and automation harms. We argue that existing taxonomies, while valuable, can be narrow, unclear, typically cater to practitioners and government, and often overlook the needs of the wider public. Drawing on existing taxonomies and a large repository of documented incidents, we propose a taxonomy that is clear and understandable to a broad set of audiences, as well as being flexible, extensible, and interoperable. Through iterative refinement with topic experts and crowdsourced annotation testing, we propose a taxonomy that can serve as a powerful tool for civil society organisations, educators, policymakers, product teams and the general public. By fostering a greater understanding of the real-world harms of AI and related technologies, we aim to increase understanding, empower NGOs and individuals to identify and report violations, inform policy discussions, and encourage responsible technology development and deployment.
DBpedia NIF: Open, Large-Scale and Multilingual Knowledge Extraction Corpus
Dec 26, 2018
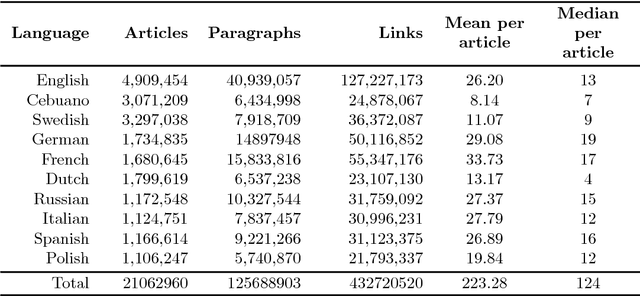

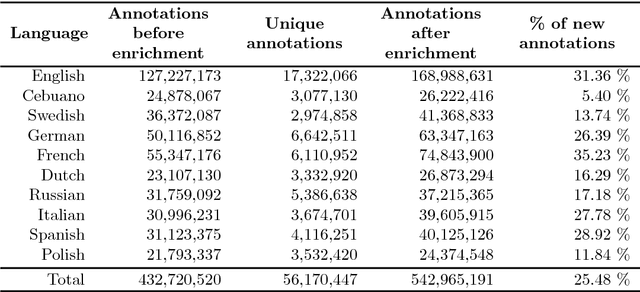
In the past decade, the DBpedia community has put significant amount of effort on developing technical infrastructure and methods for efficient extraction of structured information from Wikipedia. These efforts have been primarily focused on harvesting, refinement and publishing semi-structured information found in Wikipedia articles, such as information from infoboxes, categorization information, images, wikilinks and citations. Nevertheless, still vast amount of valuable information is contained in the unstructured Wikipedia article texts. In this paper, we present DBpedia NIF - a large-scale and multilingual knowledge extraction corpus. The aim of the dataset is two-fold: to dramatically broaden and deepen the amount of structured information in DBpedia, and to provide large-scale and multilingual language resource for development of various NLP and IR task. The dataset provides the content of all articles for 128 Wikipedia languages. We describe the dataset creation process and the NLP Interchange Format (NIF) used to model the content, links and the structure the information of the Wikipedia articles. The dataset has been further enriched with about 25% more links and selected partitions published as Linked Data. Finally, we describe the maintenance and sustainability plans, and selected use cases of the dataset from the TextExt knowledge extraction challenge.