 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBpedia NIF: Open, Large-Scale and Multilingual Knowledge Extraction Corpus
Paper and Code

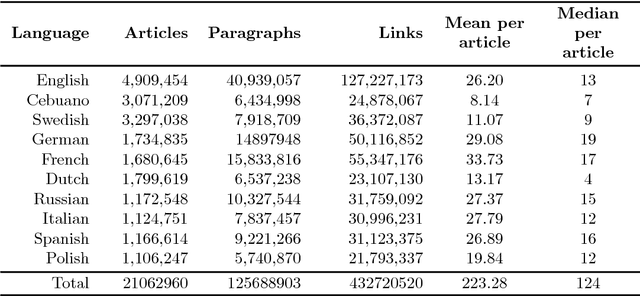

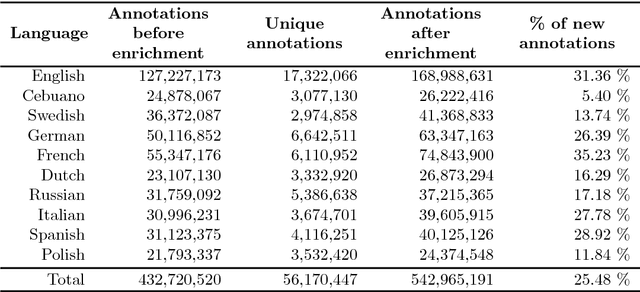
In the past decade, the DBpedia community has put significant amount of effort on developing technical infrastructure and methods for efficient extraction of structured information from Wikipedia. These efforts have been primarily focused on harvesting, refinement and publishing semi-structured information found in Wikipedia articles, such as information from infoboxes, categorization information, images, wikilinks and citations. Nevertheless, still vast amount of valuable information is contained in the unstructured Wikipedia article texts. In this paper, we present DBpedia NIF - a large-scale and multilingual knowledge extraction corpus. The aim of the dataset is two-fold: to dramatically broaden and deepen the amount of structured information in DBpedia, and to provide large-scale and multilingual language resource for development of various NLP and IR task. The dataset provides the content of all articles for 128 Wikipedia languages. We describe the dataset creation process and the NLP Interchange Format (NIF) used to model the content, links and the structure the information of the Wikipedia articles. The dataset has been further enriched with about 25% more links and selected partitions published as Linked Data. Finally, we describe the maintenance and sustainability plans, and selected use cases of the dataset from the TextExt knowledge extraction challenge.