 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation
Paper and Code
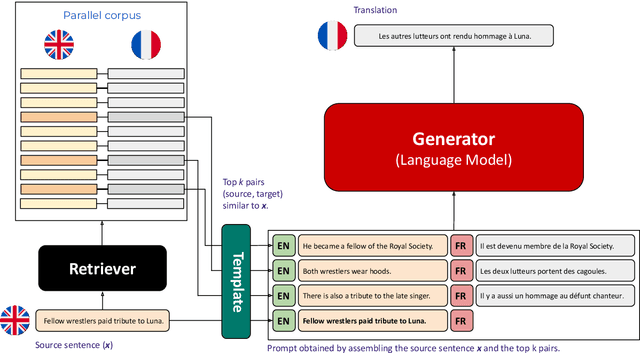

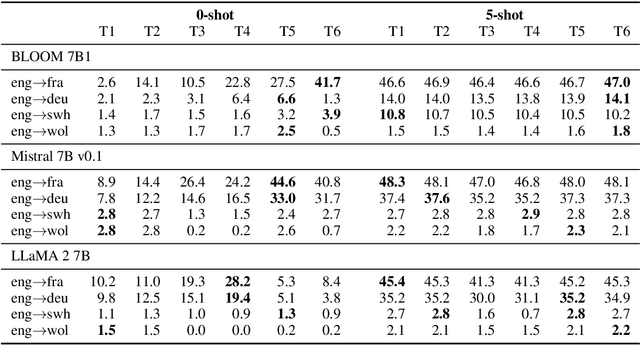
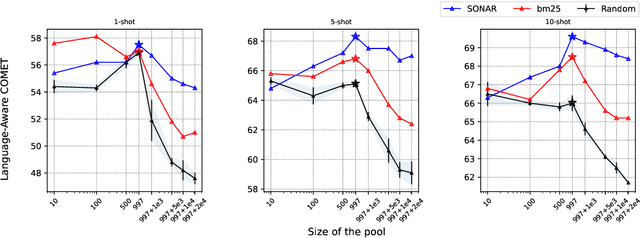
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. In this paper, we focus on machine translation (MT), a task that has been shown to benefit from in-context translation examples. However no systematic studies have been published on how best to select examples, and mixed results have been reported on the usefulness of similarity-based selection over random selection. We provide a study covering multiple LLMs and multiple in-context example retrieval strategies, comparing multilingual sentence embeddings. We cover several language directions, representing different levels of language resourcedness (English into French, German, Swahili and Wolof). Contrarily to previously published results, we find that sentence embedding similarity can improve MT, especially for low-resource language directions, and discuss the balance between selection pool diversity and quality. We also highlight potential problems with the evaluation of LLM-based MT and suggest a more appropriate evaluation protocol, adapting the COMET metric to the evaluation of LLMs. Code and outputs are freely available at https://github.com/ArmelRandy/ICL-MT.